1 Ciencia de datos
1.1 ¿Qué es la ciencia de datos?
La ciencia de datos es un campo interdisciplinario que combina métodos estadísticos, matemáticas, informática y conocimientos de dominio específico para extraer conocimiento y valor de grandes volúmenes de datos. Su objetivo es procesar, analizar y modelar datos estructurados y no estructurados para descubrir patrones, hacer predicciones y facilitar la toma de decisiones basada en datos.
En la práctica, la ciencia de datos integra técnicas de machine learning, algoritmos de procesamiento y visualización avanzada de datos, y programación (principalmente en Python y R), apoyándose en infraestructura de big data y plataformas de análisis.
ChatGPT
1.2 ¿El quehacer de la estadística o de la ciencia de datos?
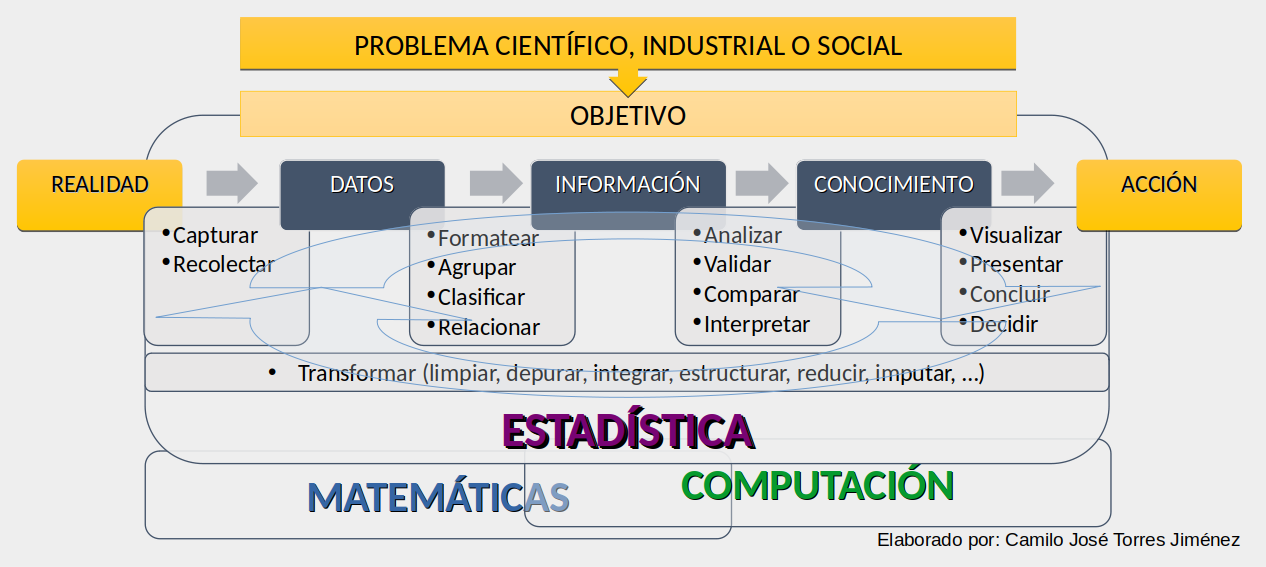
Identificar el problema y el objetivo
- ¿Cuál es el problema que quiero resolver?
- ¿Cuál es el objetivo?
- ¿Cuál es la meta a la que quiero llegar?
Capturar y recolectar datos
Transformar
- ¿Qué limpieza, depuración o transformaciones en general se requieren para este conjunto de datos? (el objetivo y las características de los datos guían la respuesta a esta pregunta)
Explorar, analizar, modelar, visualizar y concluir
- ¿Estadísticas básicas?
- ¿Gráficos?
- ¿Qué métodos, técnicas, modelos debo aplicar? (el objetivo y las características de los datos guían la respuesta a esta pregunta)
1.3 Roles en un equipo de ciencia de datos
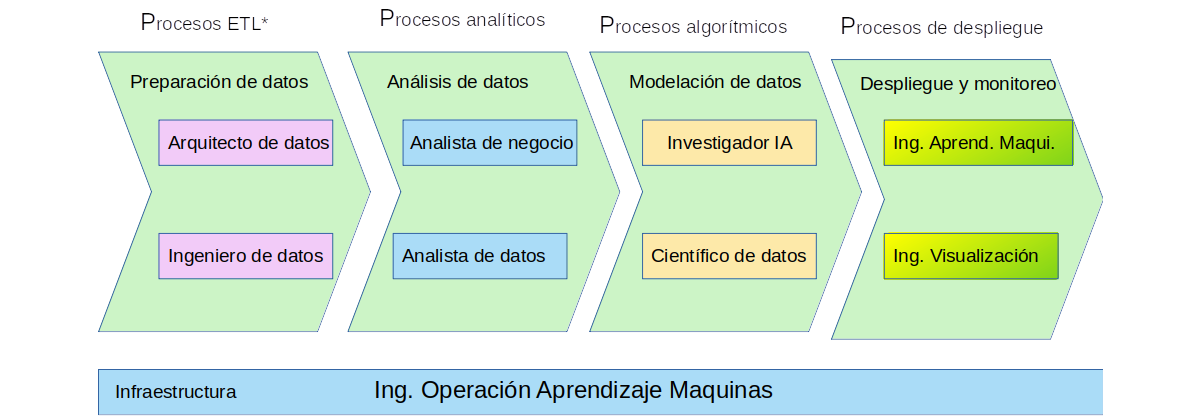
Analista de datos: Responde preguntas analizando los datos e interpretando los resultados.
Analista de negocio: Procesa, interpreta y documenta procesos comerciales, productos, servicios y software a través del análisis de datos para ayudar a formar conocimientos comerciales y tomar decisiones comerciales más efectivas.
Ingeniero de visualización de datos: Diseña soluciones de informes de datos que simplifiquen la comprensión de los datos y sus conocimientos.
Científico de datos: Se enfoca en resolver problemas mediante el desarrollo de modelos basados en IA más que dar respuestas a preguntas.
Investigador de IA: Explora y propone nuevos sistemas para resolver problemas que luego son utilizados por otros roles para escenarios del mundo real.
Ingeniero de datos: Crea canalizaciones de datos para reunir información de diferentes sistemas de origen.
Arquitecto de datos: define las políticas, los procedimientos, los modelos y las tecnologías que se utilizarán para recopilar, organizar, almacenar y acceder a la información de la empresa
Ingeniero de ML: Crea y mantiene sistemas de inteligencia artificial para automatizar modelos predictivos.
Ingeniero de MLOps: Brinda a los científicos de datos y otros roles acceso a las herramientas e infraestructura especializadas (por ejemplo, almacenamiento, computación distribuida, GPU, etc.) que necesitan a lo largo del ciclo de vida de los datos. Desarrollan las metodologías para equilibrar los requisitos únicos de ciencia de datos con los del resto del negocio para proporcionar integración con los procesos existentes y las canalizaciones de CI/CD.

1.4 Habilidades necesarias

Matemáticas
- Tensores / arreglos
- Diferenciación automática
- Optimización a gran escala. Gradiente descendiente estocástico
- Convoluciones
Estadística descriptiva, estadística inferencial, modelado estadístico, máquinas de aprendizaje / aprendizaje automático (machine learning)
Dominio de la tecnología
- Programación “clasica” y orientada a objetos
- Manejo de bases de datos y sistemas de información
- Entendimiento de lo que ocurre a nivel de hardware: Por ejemplo, diferencias entre: CPU, GPU, TPU, WSE, etc.
- Manejo de macrodatos / datos masivos (bigdata)
- Computación en la nube
Digitalización de los datos y transformación de los problemas
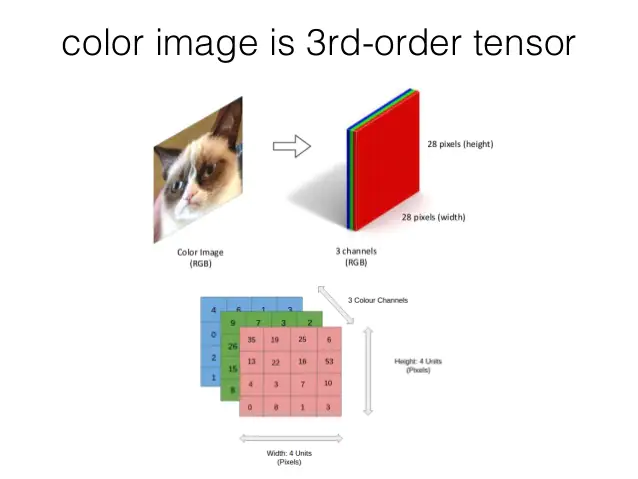
Imagen a tensor
Texto a tensor