Estadística descriptiva univariada
Estadística Descriptiva Univariada (Sección 2 del material de PyEF) https://cjtorresj.quarto.pub/pyef/02-estad_descr_univar.html
Ejemplo de aplicación (admitidos)
Admitidos a la Facultad de Ciencias
data(admi) # cargar la tabla
n <- nrow(admi) # n: número de individuos
# tabla con los datos de los primeros individuos:
kable(head(admi), digits=2) | carr | mate | cien | soci | text | imag | exam | gene | estr | orig | edad | niLE | niMa | stra | age |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Biol | 12.03 | 10.84 | 12.08 | 10.62 | 10.68 | 696.4 | F | alto | Bogo | a17 | noLE | siMa | E4 | 17 |
| Biol | 11.75 | 11.16 | 11.71 | 10.35 | 11.60 | 703.2 | M | medio | Bogo | a17 | noLE | siMa | E3 | 17 |
| Biol | 10.03 | 10.51 | 10.70 | 9.57 | 8.80 | 504.0 | F | bajo | Bogo | a18 | siLE | siMa | E2 | 18 |
| Biol | 11.48 | 11.48 | 11.71 | 10.91 | 11.60 | 714.7 | F | bajo | Bogo | a18 | noLE | siMa | E2 | 18 |
| Biol | 11.21 | 10.84 | 12.08 | 11.21 | 11.26 | 693.1 | M | medio | Bogo | a17 | noLE | siMa | E3 | 17 |
| Biol | 11.75 | 10.84 | 11.36 | 10.91 | 10.96 | 675.1 | F | medio | Bogo | a17 | noLE | siMa | E3 | 17 |
summary(admi) # resumen para las variables carr mate cien soci text
Biol:63 Min. : 9.3 Min. : 9.37 Min. : 9.02 Min. : 8.2
Esta:66 1st Qu.:10.9 1st Qu.:10.84 1st Qu.:10.70 1st Qu.:10.9
Farm:73 Median :11.5 Median :11.48 Median :11.36 Median :11.2
Fisi:82 Mean :11.8 Mean :11.59 Mean :11.36 Mean :11.4
Geol:45 3rd Qu.:12.3 3rd Qu.:12.12 3rd Qu.:11.71 3rd Qu.:11.9
Mate:53 Max. :18.3 Max. :16.52 Max. :14.84 Max. :16.5
Quim:63
imag exam gene estr orig edad
Min. : 8.48 Min. : 477 F:128 bajo :179 Bogo:311 a16m:118
1st Qu.:10.68 1st Qu.: 667 M:317 medio:185 Cund: 38 a17 :171
Median :11.26 Median : 710 alto : 81 Otro: 96 a18 : 56
Mean :11.30 Mean : 718 a19M:100
3rd Qu.:12.01 3rd Qu.: 761
Max. :14.71 Max. :1151
niLE niMa stra age
siLE: 46 siMa:315 E0: 2 Min. :15.0
noLE:399 noMa:130 E1: 36 1st Qu.:16.0
E2:141 Median :17.0
E3:185 Mean :18.1
E4: 72 3rd Qu.:18.0
E5: 8 Max. :44.0
E6: 1 # Diagrama de barras
fig <- plot_ly(admi, x=~carr, type='histogram')
fig <- fig %>% layout(title = "Carrera",
yaxis=list(title='Frec. abs.'))
fig# Diagrama de torta/pastel
cat <- attributes(admi[,1])$levels
per <- tabulate(admi[,1])/nrow(admi)*100
data <- data.frame(cat, per)
fig <- plot_ly(data, labels=~cat, values=~per, type='pie')
fig <- fig %>% layout(title = "Carrera")
fig# Histograma
fig <- plot_ly(admi, x=~mate, type="histogram")
fig <- fig %>% layout(title = "Matemáticas",
yaxis=list(title='Frec. abs.'))
fig# Histograma con densidad kernel
gg <- ggplot(data=admi) +
geom_histogram(aes(x=mate, y=after_stat(density)),
bins=30, alpha=0.7, fill=4) +
geom_density(aes(x=mate), color=4) +
ylab("") + xlab("")
ggplotly(gg) %>% layout(plot_bgcolor=grey(0.95))# Diagrama de violín con diagrama de caja
fig <- plot_ly(admi, x=~mate, type='violin',
box=list(visible=T),
meanline=list(visible=T))
fig <- fig %>% layout(title = "Matemáticas",
yaxis=list(title = "", zeroline=F))
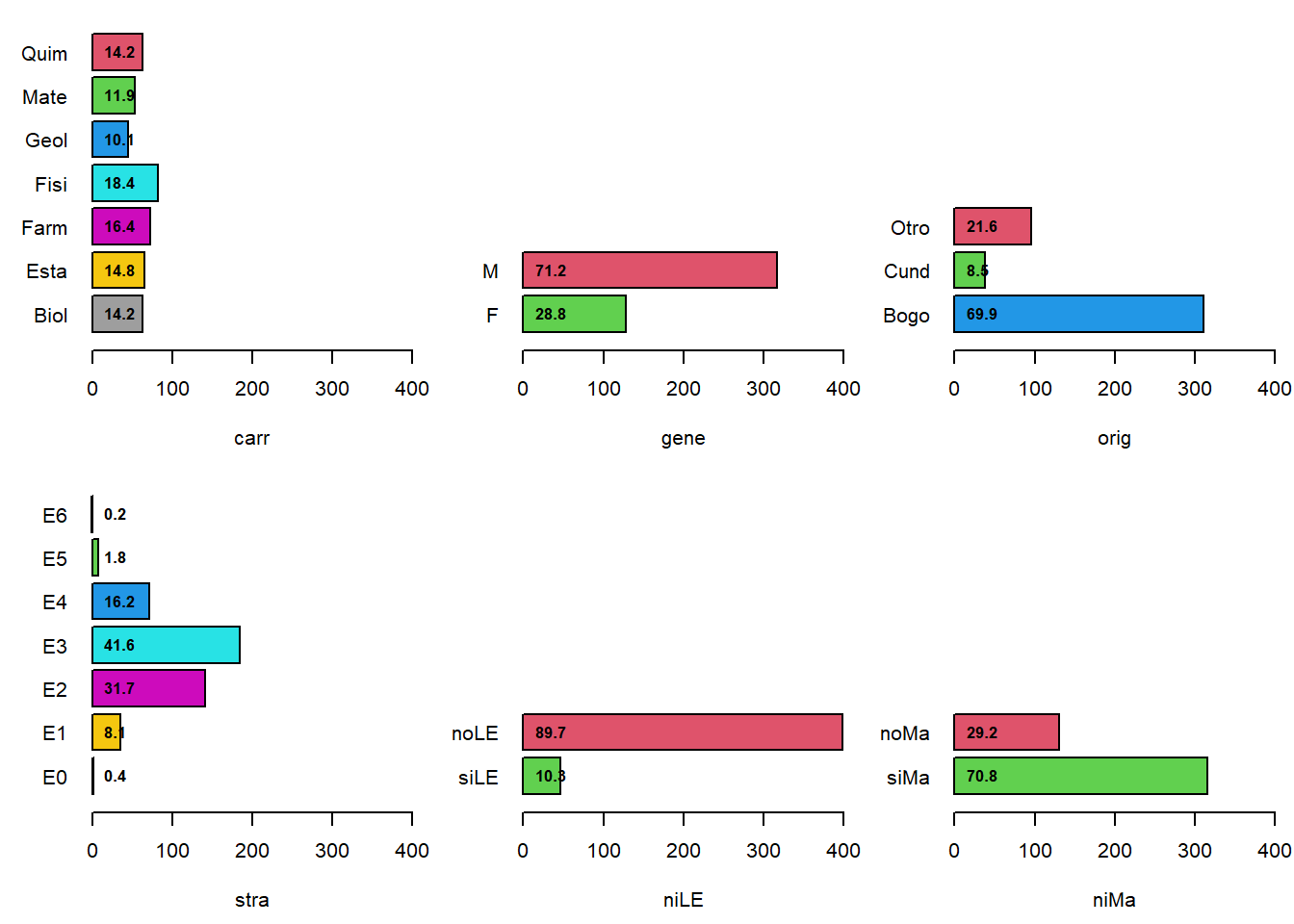
fig# 6 barplots y etiquetas de las categorias en forma horizontal
par(las=1, mfrow=c(2,3), mai=c(0.6,0.5,0.2,0.1))
for(i in c(1,8,10,14,12,13)){
cat <- attributes(admi[,i])$levels
per <- tabulate(admi[,i])/n*100
pl <- plot( admi[,i], horiz=TRUE,
#col=gray(seq(1.0,0.9,length=length(cat))),
col=length(cat):1+1,
ylim=c(0,8), xlim=c(0,400),
xlab=colnames(admi)[i] )
text(0, pl, round(per,1), cex=0.8, font=2, pos=4)
}
# dev.print(device=pdf) # grabar la grafica como Rplots.pdf# Histogramas y dos diagramas de caja
par(mfrow=c(3,3), mai=c(0.3,0.4,0.3,0.1), las=1, bty="n")
for(i in c(2:6)) hist(admi[,i], main=names(admi)[i], col=i,
xlim=c(8,18), ylim=c(0,200))
for(i in c(7,15)) hist(admi[,i], main=names(admi)[i], col=7)
boxplot(admi$age, main="age", horizontal=TRUE, col=7)
boxplot(admi$exam, main="exam", horizontal=TRUE, col=15)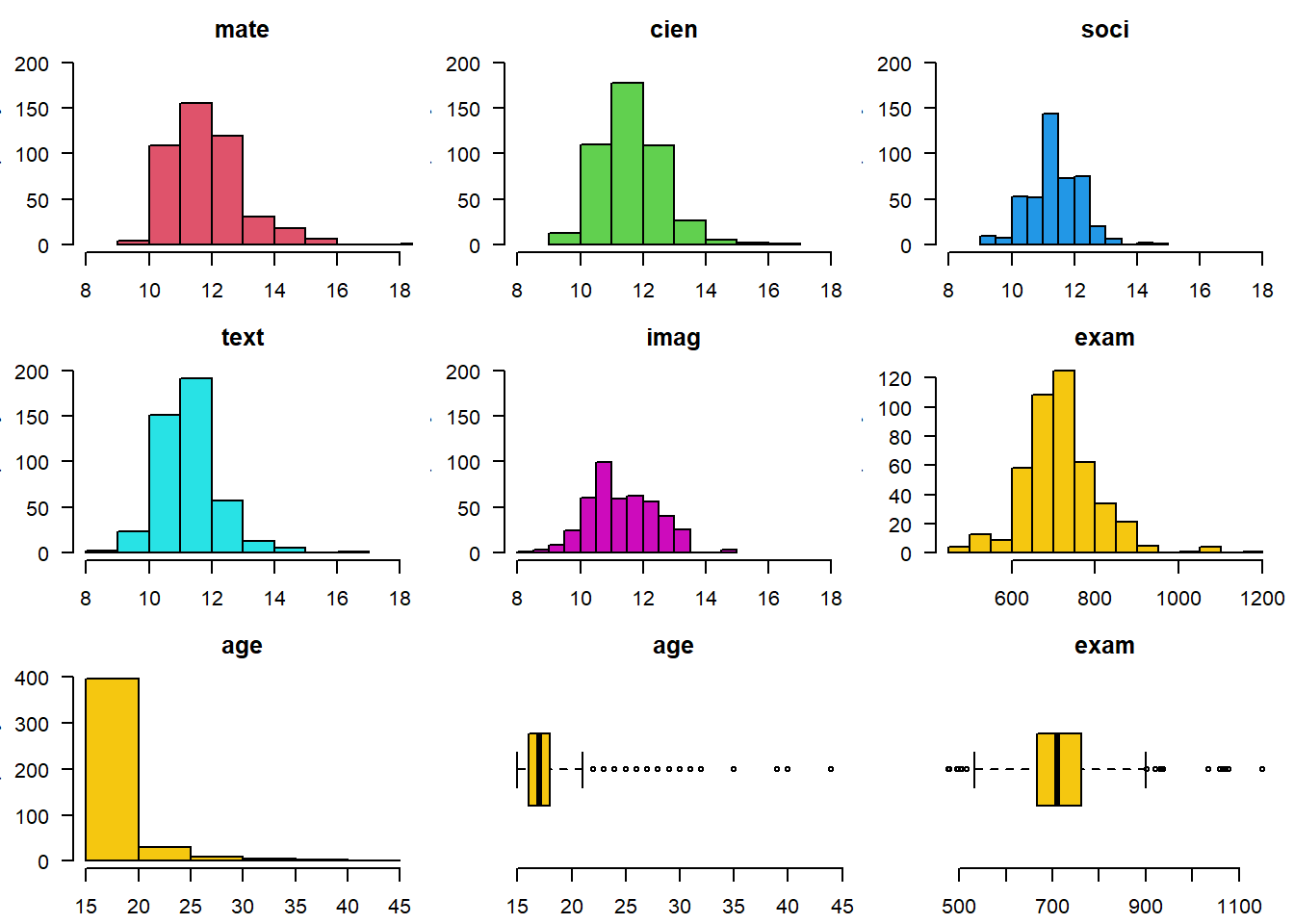
Transformación de variables cualitativas
Los valores faltantes pueden considerarse como una categoría en sí misma.
Es deseable que las variables cualitativas tengan un número similar o cercano de categorías.
Es deseable que no hayan categorías con frecuencias relativamente muy bajas.
# Nueva variable para estrato
estr <- as.integer(admi$stra)-1
estr[estr<3] <- 1; estr[estr==3] <- 2; estr[estr>3] <- 3
estr <- factor(estr, labels=c("bajo","medio","alto"))
summary(estr) bajo medio alto
179 185 81 Codificación en clases de variables continuas
- Es posible que por alguna razón (alguna razón de peso) se requiera una variable categórica en representación de los datos de una variable continua. En ese caso, la variable categórica debe obtenerse siguiendo los objetivos del análisis, el contexto de los datos, y las mencionadas características deseables para una variable cualitativa (más categorías con frecuencias no tan disimiles).