3 Fund. estadísticos
Definiciones iniciales y fundamentos estadísticos
Se recomienda leer el Capítulo 1: La imaginación estadística del libro: Estadística para las ciencias sociales. Ferris J. Ritchey (2008). (2a Ed.) McGraw-Hill.
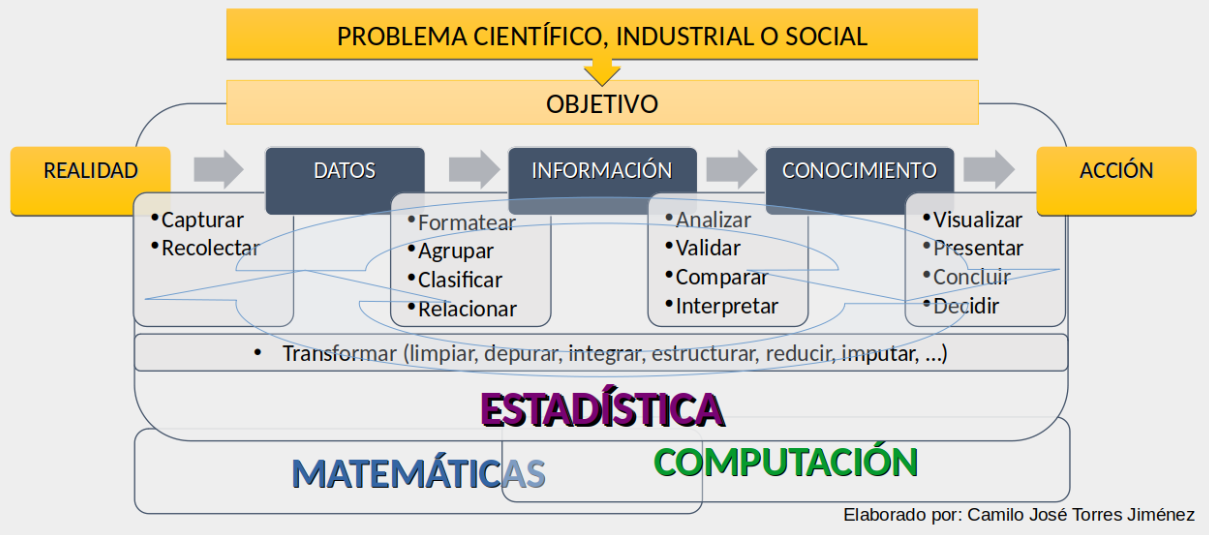
3.1 ¿El método científico y los datos?
Objetivo: Resolver problemas de interés en un área mediante la aplicación eficiente de principios científicos.
- Describir el problema o fenómeno.
- Identificar factores importantes alrededor del problema y de la posible solución.
- Postular una tesis (proponer un modelo) usando el conocimiento del fenómeno y estableciendo supuestos y limitaciones.
- Realizar experimentos apropiados y recolectar los datos asociados.
- Validar o rechazar la tesis planteada (validar o rechazar el modelo planteado).
- Establecer conclusiones y recomendaciones, así como posiblemente proponer una nueva tesis (lo que llevaría a un nuevo paso 3. en adelante).
Esto quiere decir que todo el trabajo con los datos, desde su adecuada recolección hasta el poder sacar conclusiones o tomar decisiones a partir de ellos, es de suma importancia
3.2 ¿Estadística, Analítica de Datos, Ciencia de Datos?
You said:
Dame un resumen de toda nuestra conversación acerca de ¿cuál es la diferencia entre Analítica de Datos, Ciencia de Datos y Estadística?
ChatGPT said:
Aquí tienes un resumen lineal y claro de lo que discutimos:
Preguntaste por la diferencia entre analítica de datos, ciencia de datos y estadística. Te expliqué que la estadística es la base teórica, la analítica se enfoca en resolver problemas concretos y la ciencia de datos combina estadística con programación y escalabilidad.
Señalaste que todo es estadística. Te respondí que, en efecto, la estadística es el núcleo y que las etiquetas “analítica” y “ciencia de datos” surgen más por diferenciación práctica y laboral.
Observaste que la estadística siempre ha sido aplicada, por lo que no tenía sentido mi distinción entre teoría y aplicación. Ajusté la explicación: la estadística no deja de ser aplicada, la diferencia está en énfasis distintos y en las expectativas de los contextos modernos.
Propusiste que estas etiquetas podrían ser solo nombres de moda. Te confirmé que hay un fuerte componente de mercadeo, pero también señalé que han cambiado las condiciones de trabajo con datos (volumen, velocidad, integración tecnológica, escalabilidad), lo cual llevó a crear nuevas denominaciones.
Criticaste la justificación tecnológica, porque la estadística siempre ha usado las herramientas de su tiempo. Acepté ese punto y precisé que la diferencia actual no es el instrumento en sí, sino la forma en que el trabajo con datos se volvió sistemático, automatizado y ligado a productos en producción, con responsabilidades distintas a las de la investigación estadística clásica.
Finalmente preguntaste si la separación es solo una cuestión de mercado. La conclusión fue que sí: en esencia todo es estadística, y las etiquetas “analítica” y “ciencia de datos” responden sobre todo a dinámicas de mercado laboral, educativas y de organización profesional, no a una ruptura epistemológica.
You said (al final de la conversación y antes de pedir el resumen):
O sea que la única razón para separarlos es simplemente una cuestión de mercado.
ChatGPT said:
En el fondo sí: la principal razón de la separación es de mercado, no epistemológica. No apareció una nueva “ciencia” que contradiga o reemplace a la estadística. Lo que ocurrió fue que, a medida que las empresas necesitaron perfiles con mezcla de estadística, programación, gestión de bases de datos y despliegue de modelos, surgió la etiqueta “ciencia de datos” para vender formación, contratar profesionales y organizar equipos.
En otras palabras:
La estadística sigue siendo la base conceptual.
La analítica de datos y la ciencia de datos son marcas profesionales y comerciales que delimitan roles y expectativas en la práctica.
La separación no responde a una ruptura intelectual, sino a una reconfiguración laboral y educativa.
Si mañana se vuelve más rentable hablar de “inteligencia aumentada de datos”, probablemente veas otra etiqueta más encima de lo mismo.
¿Quieres que te haga un análisis histórico-crítico mostrando cómo han ido cambiando estas etiquetas en diferentes momentos (estadística → investigación operativa → minería de datos → ciencia de datos) para que se vea claro el patrón de “rebautizar lo mismo” según la época?
You said (después de pedir el resumen):
lo que al final no cuadra es que la práctica profesional de una estadística hoy en día implicaría dominar la teoría estadística, las matemáticas detrás, la programación, el manejo de bases de datos, la implementación de algoritmos y el deployment de soluciones; una práctica profesional estadística hoy en día no tendría sentido sin eso. No tiene sentido un profesional dedicado a el quehacer relacionado con desde la captura hasta el sacar conclusiones o tomar decisiones a partir de datos que no sepa usar las herramientas de hoy en día del caso en cierta medida, al menos para una delegación informada de tareas y la capacidad de verificar si se hicieron bien o no
ChatGPT said:
Exacto, y ahí es donde se revela la contradicción de fondo: lo que hoy en el mercado llaman “científico de datos” coincide casi punto por punto con lo que debería ser un estadístico contemporáneo bien formado.
Un profesional de estadística en 2025 no puede limitarse a hacer cálculos en papel ni a usar software cerrado como si fueran cajas negras. Su práctica profesional, para ser completa, incluye:
dominio de teoría estadística e inferencia,
competencias matemáticas que sustenten la modelación,
habilidades de programación para implementar y adaptar métodos,
manejo de bases de datos y flujos de datos,
conocimiento de algoritmos y aprendizaje automático,
nociones de despliegue y validación de soluciones en entornos reales.
Si un “estadístico” no tiene eso, queda desactualizado. Pero, en vez de actualizar la idea de lo que significa ser estadístico, la industria y la academia optaron por acuñar “ciencia de datos” como una especie de etiqueta renovada que da la impresión de novedad.
La consecuencia es que hoy muchos programas de estadística han tenido que rebautizarse o reformarse para no parecer obsoletos, aunque lo que enseñan siga siendo, en el núcleo, estadística aplicada con herramientas modernas.
La conclusión cruda es esta: no hay una diferencia epistemológica entre “estadística” y “ciencia de datos”. Lo que hay es un desajuste entre lo que debería ser un estadístico actualizado y la imagen social/mercantil de lo que se vende como ciencia de datos.
3.3 ¿Estadística?
Cuerpo de conceptos y métodos empleados para la recolección e interpretación de datos acerca de un área particular de investigación y, a partir de ellos, obtener conclusiones en situaciones donde la incertidumbre y variación están presentes.
El objetivo de la estadística moderna abarca la recolección, presentación y caracterización de información para ayudar tanto en el análisis de datos como en el proceso de toma de decisiones.
La estadística está al servicio de todas las áreas de conocimiento, en su búsqueda de entender la realidad por medio del análisis de datos y en donde la incertidumbre y variabilidad hacen parte de la naturaleza de dicha realidad/datos.
La estadística gira alrededor de la incertidumbre (describir, entender, medir, controlar, establecer, explicar). Si no hay incertidumbre (aleatoriedad) entonces no hay estadística.
3.4 ¿Datos?
Los conjuntos de datos más sencillos son los denominados datos estructurados, los cuales podemos encontrar en una tabla de datos simple como la siguiente:
3.5 ¿Definiciones Iniciales?
Individuo o unidad estadística: Es la unidad básica de observación y análisis en un estudio estadístico.
Por ejemplo: Persona, Animal, Empresa, País, Año.
Variable: Característica, propiedad o atributo de cada individuo o unidad estadística, que puede tomar distintos valores entre ellos.
Por ejemplo: Estatura, Edad, Ingresos, Transacciones.
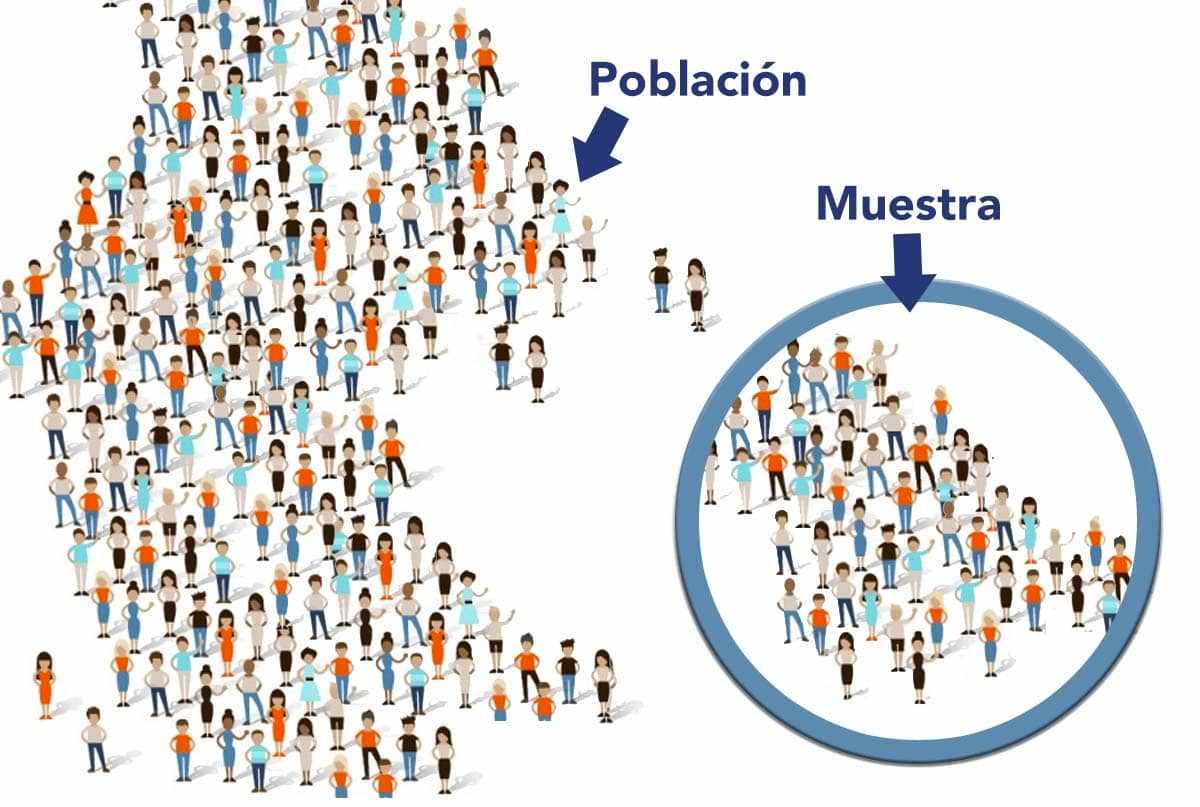
Población: Conjunto de todos los individuos o unidades estadísticas sobre los cuales se desea estudiar una o más variables. Se define en función del objetivo del estudio.
Por ejemplo: Estudiantes de la asignatura 1000013-B para el presente semestre académico, Toros de lidia llevados a la Santamaría en las últimas dos décadas, Empresas textiles que tuvieron exportaciones en los últimos cinco años, Años que tuvieron vigente el programa “Bogotá Despierta” el día del amor y la amistad.
Censo: Procedimiento mediante el cual se recopila información de interés sobre todos los elementos de una población.
- Ventaja: Se dispone de información completa, por lo que no hay incertidumbre asociada al desconocimiento de datos.
- Desventaja: Suele implicar altos costos en términos de tiempo, recursos humanos y dinero.
Muestra: Subconjunto de individuos o unidades estadísticas de la población, seleccionados mediante un procedimiento definido, para los cuales se recopilan datos con el propósito de realizar inferencias estadísticas válidas sobre la población de origen.
- Ventaja: Permite obtener información útil a menor costo y en menor tiempo que un censo.
- Desventaja: Al no incluir toda la población, las conclusiones están sujetas a incertidumbre, y la validez de las inferencias depende de la calidad del diseño muestral y del análisis estadístico.
Constructo o variable latente: Variable que no puede observarse ni medirse directamente, y cuyo estudio requiere recurrir a otras variables observables relacionadas con ella. Suele corresponder a propiedades o conceptos intangibles, abstractos o complejos que no se manifiestan de forma directa.
Por ejemplo: Inteligencia, Felicidad, Inflación, PIB.
Guillermo Briones en Metodología de la investigación cuantitativa en las ciencias sociales dice:
Un constructo es una propiedad que se supone posee una persona, la cual permite explicar su conducta en determinadas ocasiones. Como tal, el constructo es un concepto teórico, hipotético… Los constructos se definen como propiedades subyacentes, que no pueden medirse en forma directa, sino mediante manifestaciones externas de su existencia, es decir, mediante indicadores. En otras palabras, los constructos son variables subyacentes, por lo cual, habitualmente, caen en la denominación común de variables.”
3.6 ¿Áreas iniciales?
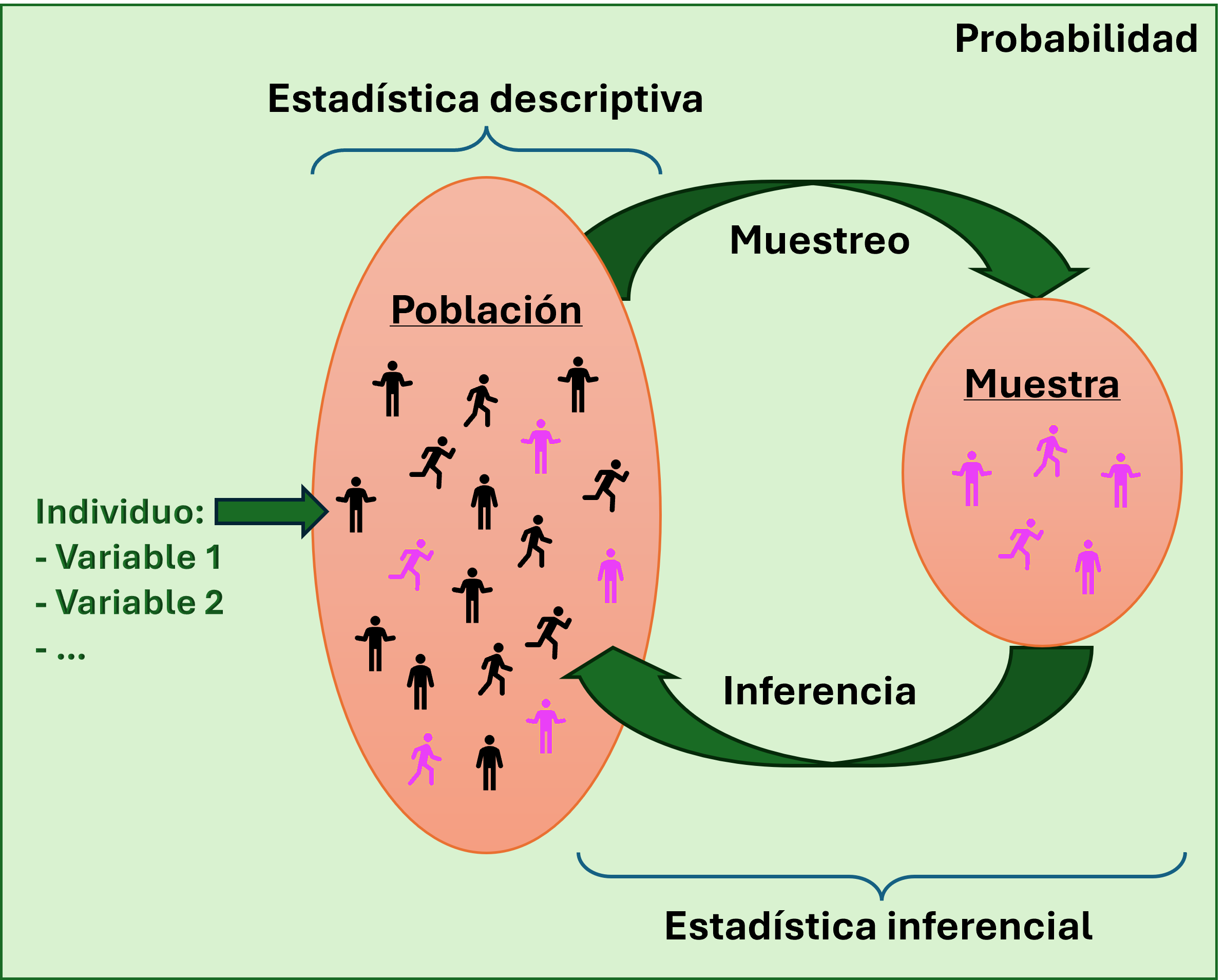
3.6.1 ¿Estadística Descriptiva?
Describir, presentar, resumir un conjunto de datos (al menos por el momento, no queremos sacar conclusiones con respecto a un conjunto de individuos más allá de aquellos para los que tenemos sus datos).
3.6.2 ¿Estadística inferencial?
Sacar conclusiones sobre la población a partir de lo que se observa en la muestra (conclusiones, toma de decisiones, predicciones, …).
3.6.3 ¿Probabilidad?
Formalización matemática que busca definir y medir la incertidumbre (aleatoriedad).
3.7 ¿Relaciones?
3.8 ¿Dependiendo del número de variables analizadas a la vez?
3.8.1 ¿Estadística univariada?
3.8.2 ¿Estadística bivariada?
3.8.3 ¿Estadística multivariada?
3.9 ¿Clasificación de variables?
Retomando la tabla de datos, ahora sabemos que cada fila corresponde a un individuo y cada columna corresponde a una variable. Evidentemente, no todas las variables son del mismo tipo.
3.10 ¿Clasificación de variables?
flowchart LR A(Clasificar en:) --> D(Cualitativa o categórica) A --> E(Cuantitativa o numérica)
Variable cualitativa o categórica: Los valores que toma la variable describen un atributo o característica de los individuos (los valores NO tienen un sentido numérico).
Variable cuantitativa o numérica: Los valores que toma la variable cuantifican o miden un atributo o característica de los individuos (los valores tienen un sentido numérico).
Ejercicio 3.1 Un grupo de investigadores desea aplicar una encuesta para caracterizar a los estudiantes de una universidad. A continuación se describen algunas variables incluidas en el formulario. Para cada una identifique si la variable es cualitativa o cuantitativa.
- Color favorito declarado por el estudiante
- Número de hermanos del estudiante
- Marca de teléfono móvil que utiliza el estudiante
- Altura del estudiante en metros
- Estrato socioeconómico del estudiante
- Estado civil actual del estudiante
¿Alguna de las anteriores variables podría clasificarse de manera diferente si cambiara el contexto o la forma en que se solicitan los datos? ¿Puede dar un ejemplo concreto en el que la clasificación de una variable cambie debido por ejemplo al contexto?
3.11 ¿Escalas de medida?
La escala de medida de una variable determina las “posibilidades operativas o matemáticas” de los valores que ésta toma; Por ende, también determinará qué tratamiento y qué tipo de análisis serían los adecuados para la respectiva variable.
flowchart LR A(Clasificar en:) --> B(Cualitativa o categórica) A --> C(Cuantitativa o numérica) B --> B1(Nominal) B --> B2(Ordinal) C --> C1(De intervalo) C --> C2(De razón)
3.11.1 ¿Nominal?
Los valores que toma la variable son descriptivos, es decir, etiquetas o nombres. Lo único que se puede hacer es clasificar o agrupar los individuos de acuerdo al valor que toma la variable para cada uno.
Por ejemplo:
- Género (F, M).
- Grupo sanguíneo (A, B, AB, O).
3.11.2 ¿Ordinal?
Los valores que toma la variable son descriptivos, es decir, etiquetas o nombres pero estos, además de permitir clasificar, tienen una relación de orden.
Por ejemplo:
- Estrato socieconómico (1, 2, 3, …, 6)
- Nivel de estudios (Primaria, secundaria, universitario, postgrado)
- Nivel de inglés (A1, A2, B1, B2, C1, C2)
Note que los posibles valores de cada una de las variables tienen un orden intrínseco.
3.11.3 ¿De intervalo?
Incluye las características de una variable con escala de medida ordinal, pero adicionalmente tiene sentido tanto la suma como la resta de valores (las distancias entre los valores tienen sentido).
Por ejemplo:
- Número de hijos.
- Número de estudiantes.
- Número de materias.
3.11.4 ¿De razón?
Incluye las características de una variable con escala de medida de intervalo, pero adicionalmente tienen sentido la multiplicación y división de valores de la variable (la razón entre los valores tiene sentido) y el valor cero representa la ausencia de lo que mide la variable (el cero es significativo).
Por ejemplo:
- Tiempo en horas, minutos, segundos
- Medidas físicas como longitud, peso, área, etc.
- Cantidades en unidades monetarias como ingresos, tasa de cambio, etc..
En conclusión, las “posibilidades operativas o matemáticas” de cada escala de medida se resumen en la siguiente tabla:
| Escalas de medida | =, \neq | <, \leq, >, \geq | +, - | \times, \div, 0 |
|---|---|---|---|---|
| Nominal | \checkmark | |||
| Ordinal | \checkmark | \checkmark | ||
| De intervalo | \checkmark | \checkmark | \checkmark | |
| De razón | \checkmark | \checkmark | \checkmark | \checkmark |
Ejercicio 3.2 Clasifique las variables según si son cualitativas (nominal u ordinal) o cuantitativas (de intervalo o de razón).
- Género:
- Rangos del ejército (oficial, suboficial, etc):
- Marca de automóvil:
- Nivel de satisfacción (alto, medio, bajo):
- Altura en centímetros:
- Distancia en kilómetros: