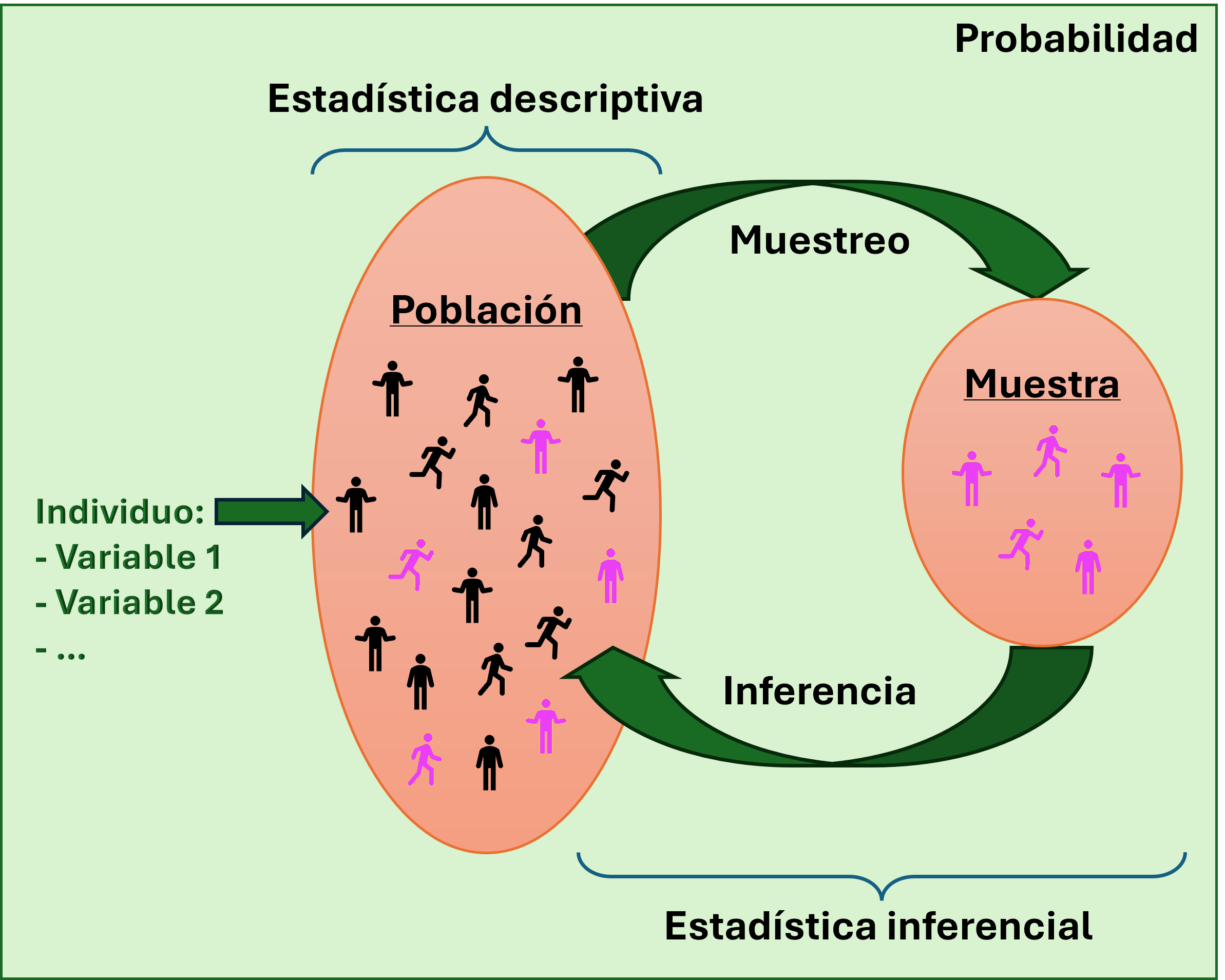
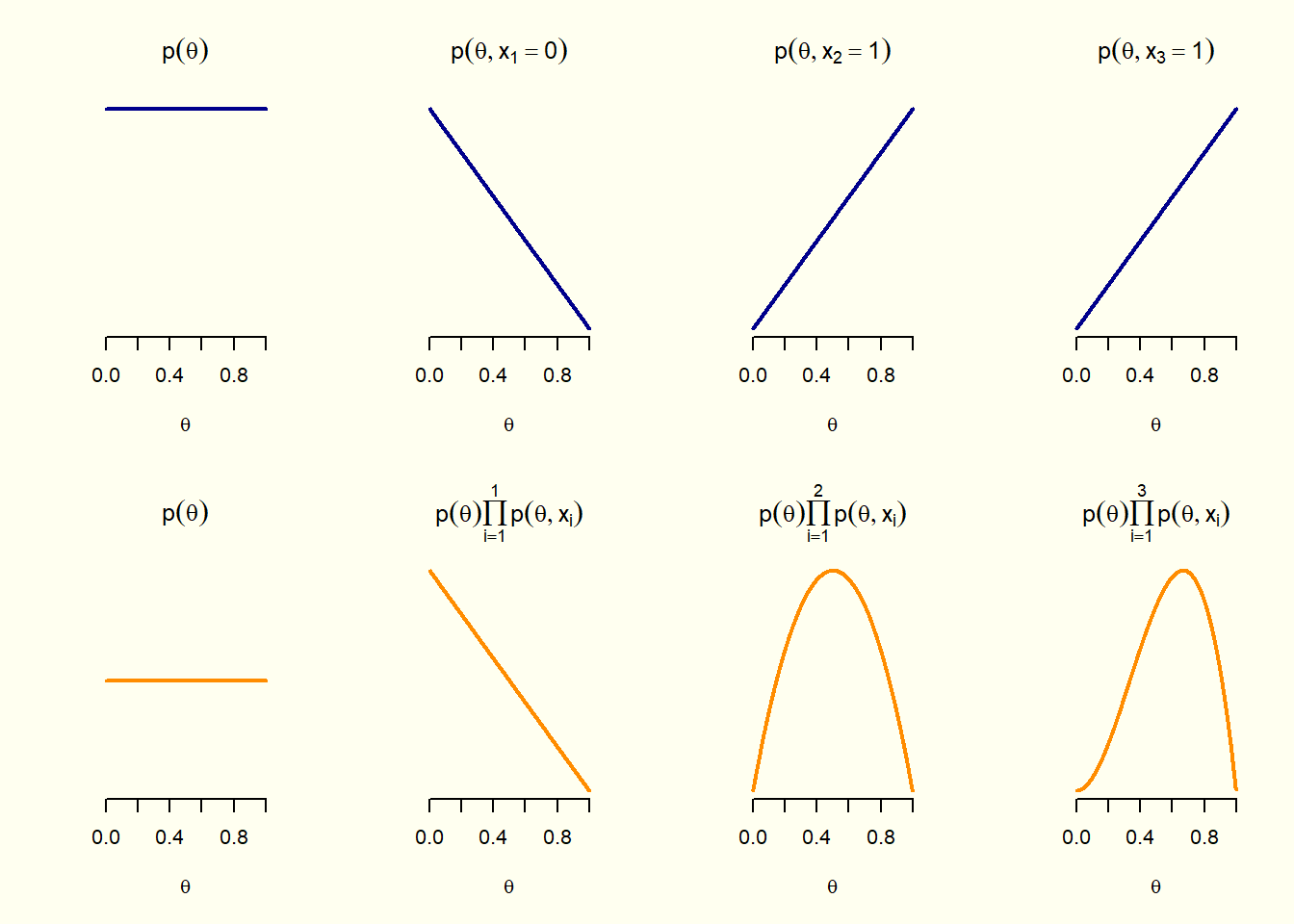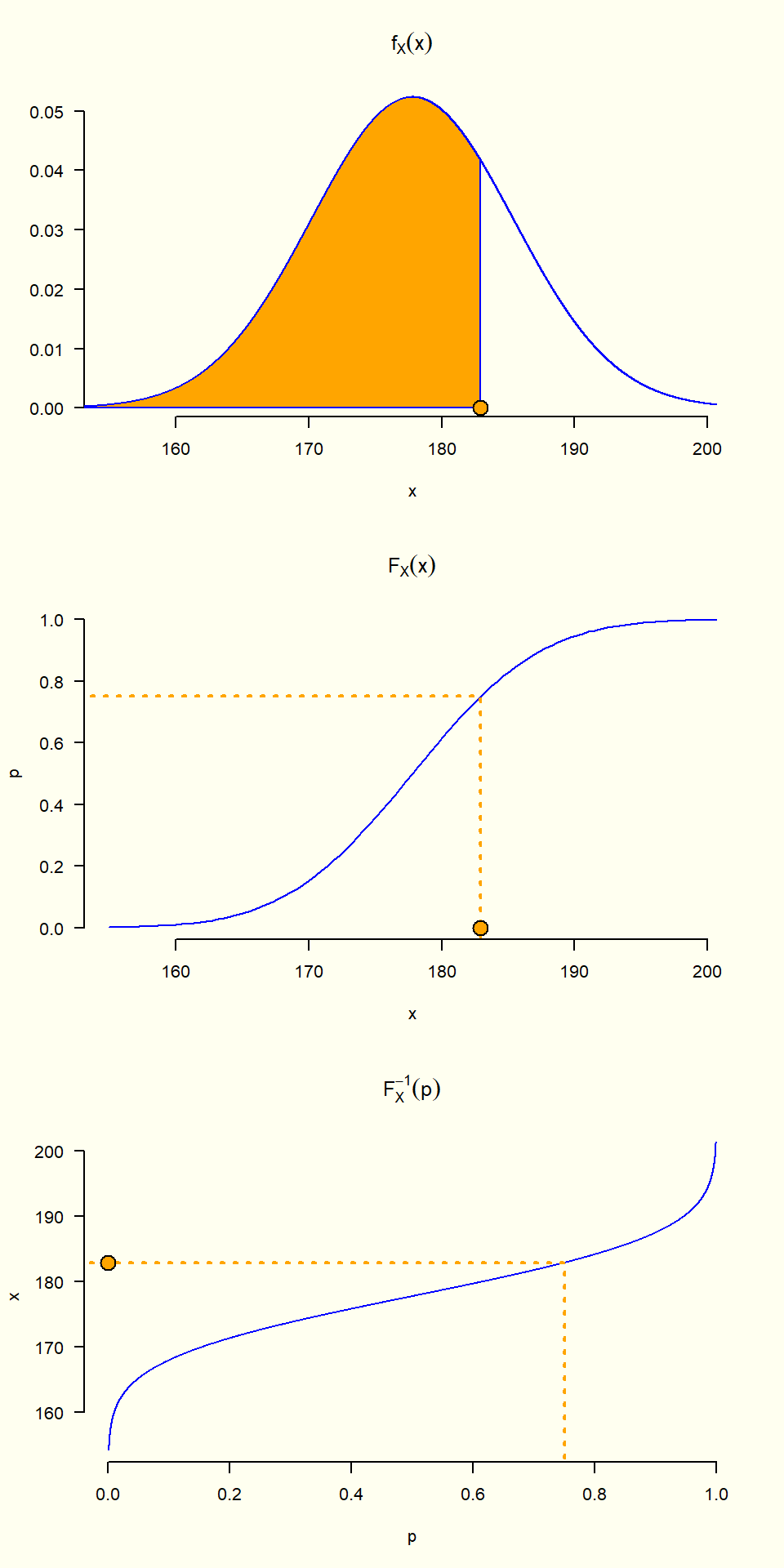Preliminares en relación al aprendizaje supervisado
El aprendizaje supervisado constituye el eje del análisis predictivo en el campo del aprendizaje automático.
Su rasgo esencial es la presencia de una variable de salida o respuesta, cuya información orienta el proceso de modelado y permite evaluar la capacidad de generalización del modelo.
Desde una perspectiva estadística, este enfoque busca caracterizar la relación entre una variable objetivo y un conjunto de variables explicativas, asumiendo que dicha relación está sujeta a variabilidad y que solo puede conocerse parcialmente a partir de los datos observados.
El conjunto de observaciones disponibles conforma la base de entrenamiento, que contiene tanto los predictores como las respuestas conocidas. A partir de ella, el objetivo es “aprender” un patrón estable que permita predecir o estimar la respuesta correspondiente a nuevas observaciones.
El aprendizaje supervisado se apoya en los principios de la probabilidad y la inferencia estadística.
La probabilidad ofrece un marco formal para describir la incertidumbre asociada a los fenómenos aleatorios
La inferencia proporciona los métodos necesarios para extrapolar conclusiones más allá de los datos muestrales.
Comprender este marco implica reconocer que todo modelo predictivo es una aproximación sujeta a error y que su validez depende de la solidez con que se aborden la incertidumbre, la variabilidad y las limitaciones propias de los datos observados.
Código a ejecutar para empezar (de clic en donde en dice “Code”, para desplegar el código, y luego copie y pegue en una sesión abierta de R):
8.1 Abordando la incertidumbre: Probabilidad y variables aleatorias
8.1.1 Conceptos básicos de probabilidad
La probabilidad surge como una herramienta para enfrentar la incertidumbre.
Desde la antigüedad, las personas se han enfrentado a situaciones cuyos resultados no podían preverse con certeza.
Para afrontar esa imprevisibilidad, recurrieron a la observación, la experiencia y la intuición.
De la repetición de hechos surgieron creencias empíricas sobre la frecuencia o la posibilidad de ciertos resultados.
Actividades como el lanzamiento de dados estuvieron presentes desde tiempos antiguos; sin embargo, en aquel momento no existía una formulación sistemática que explicara el comportamiento de sus resultados.
Durante el siglo XVII, en Europa, comenzó la formalización matemática de la probabilidad, precisamente a partir del estudio de los juegos de azar.
Con el tiempo, esas ideas se extendieron a otros ámbitos y dieron origen a métodos rigurosos para describir fenómenos de naturaleza aleatoria.
En el siglo XX, la probabilidad alcanzó una formalización axiomática, sustentada en la teoría de conjuntos y la teoría de la medida.
A partir de entonces, se consolidó como el lenguaje matemático fundamental para el análisis y la modelación de la incertidumbre.
Fuente: Generado por IA, Qwen
Probabilidad e Inteligencia Artificial:
Muchas herramientas y aplicaciones de IA, en lugar de operar con verdades lógicas absolutas, se fundamentan en el razonamiento probabilístico.
La representación del conocimiento en términos de distribuciones de probabilidad permite combinar evidencia parcial, actualizar creencias ante nueva información y tomar decisiones óptimas en entornos donde la información es incompleta, ambigua o contradictoria.
Esta forma de modelar la realidad refleja una idea central: el conocimiento es incertidumbre estructurada y la probabilidad ofrece el marco matemático para cuantificarla y gestionarla.
Sin una base probabilística, los sistemas de aprendizaje automático no podrían ajustarse a los datos, generalizar a nuevos casos ni mantener un funcionamiento estable y coherente frente a la variabilidad del entorno.
En este sentido, la probabilidad no solo proporciona un lenguaje formal para describir el azar, sino también una herramienta esencial para el aprendizaje y la toma de decisiones racionales.
El aprendizaje supervisado, en particular, depende de este enfoque para representar cualquier tipo de incertidumbre asociada a los datos y a las predicciones, y para evaluar la confianza en los modelos construidos.
8.1.1.1 Ejemplo de aplicación
Dado que ya conocemos bien los datos de admitidos, continuaremos trabajando con ellos:
Código
# cargar la tabla ejemplo admitidos:data("admi")# Base de datos admitidos ciencias n<-nrow(admi)# n: número de individuosdata(admi)
Si se selecciona un admitido “al azar” de la tabla de datos, ¿cuál es la probabilidad de que sea de género femenino?
8.1.2 Experimento Aleatorio
¿Seleccionar un admitido “al azar” de la tabla de datos y observar cuál es su género registrado allí es un experimento aleatorio?
Situación o experimento que cumple las siguientes condiciones:
Es posible determinar por extensión o por comprensión el conjunto de todos los resultados posibles del experimento.
No se sabe cuál de los resultados se obtendrá al realizar el experimento.
Idealmente, el experimento debería poder repetirse en “condiciones similares”.
8.1.3 Espacio muestral
Espacio muestral: Conjunto de todos los resultados posibles de un experimento aleatorio.
¿Cuáles serían los resultados posibles al seleccionar un admitido “al azar” de la tabla de datos y observar cuál es su respectivo género?
Genero
F
M
El espacio muestral, como conjunto que es, se podría escribir así:
\left\{F, M\right\}
8.1.4 Suceso o evento
Si se selecciona un admitido “al azar” de la tabla de datos, ¿cuál es la probabilidad de que tenga uno de los siguientes estratos: 4, 5, 6?
Un suceso o evento es un conjunto con resultados posibles del experimento aleatorio (un suceso o evento es cualquier subconjunto del espacio muestral).
Estrato
E0
E1
E2
E3
E4
E5
E6
8.1.5 ¿Calcular una probabilidad?
Si se selecciona un admitido “al azar” de la tabla de datos, ¿cuál es la probabilidad de que sea de género femenino?
Genero
frec.abs.
frec.rel.
F
128
0.29
M
317
0.71
TOTAL
445
1.00
Definición clásica:
Para un evento cualquiera (A), la probabilidad de dicho evento (P[A]) es igual al número de resultados posibles asociados al evento sobre el total de resultados posibles del experimento aleatorio (Siempre y cuando, el espacio muestral sea finito y todos los resultados sean igualmente probables).
Axiomas:
Los axiomas son unas premisas que se asumen, que no son una consecuencia de otras proposiciones, y que sirven de base para deducir y demostrar una serie de resultados dentro de una teoría.
Los siguientes axiomas se deben cumplir, para poder decir que P[\cdot] es una medida de probabilidad:
Hay certeza total de que ocurrirá alguno de los resultados posibles, por eso la probabilidad de todo el espacio muestral debería ser uno (P[\Omega] = 1).
Si para un evento, probabilidad cero significa imposible, no tendrían sentido probabilidades negativas (Para todo A \subset \Omega, P[A] \geq 0).
Si los eventos no tienen “traslapes”, la probabilidad al unirlos debería ser la misma que la suma de sus probabilidades por separado (Para todo A_1, A_2, \dots \subset \Omega con A_i \cap A_j = \emptyset para i \neq j se tiene que P\big[ \bigcup_{i=1}^\infty A_i \big] = \sum_{i=1}^{\infty} P\left[ A_i \right])
A partir de los axiomas se pueden deducir los siguientes resultados.
Si un evento contiene a otro, su probabilidad es al menos igual de grande, es decir, Cuando un evento está contenido en otro, la probabilidad del primero es siempre menor o igual que la del segundo (Para todo A \subset \Omega y B \subset \Omega, se tiene que, si A \subset B entonces P[A] \leq P[B])
Si un evento no tiene por lo menos uno de los resultados posibles, entonces su probabilidad tiene que ser cero (P[\emptyset] = 0)
Toda probabilidad está entre lo imposible y lo completamente seguro (Para todo A \subset \Omega, se tiene que 0 \leq P[A] \leq 1).
La probabilidad de toda unión se obtiene sumando, pero hay que evitar contar dos veces lo común (Para todo A \subset \Omega y B \subset \Omega, se tiene que P[A \cup B] = P[A] + P[B] - P[A \cap B])
La probabilidad de que no suceda un evento es exactamente lo que le hace falta a la probabilidad de que suceda para llegar a uno, es decir, la probabilidad de que un evento suceda y la de que no suceda siempre suman uno (Para todo A \subset \Omega, se tiene que P\left[A^C\right] = 1 - P[A])
Si se selecciona un admitido “al azar”, ¿cuál es la probabilidad de que: (a) sea de género masculino?, (b) sea de estrato 1?, (c) sea de género masculinoY de estrato 1?
Si se selecciona un admitido “al azar”, ¿cuál es la probabilidad de que: (a)NO sea de estrato 1?, (b) sea de género masculinoO de estrato 1?
Tabla de frecuencias absolutas:
F
M
TOT
E0
1
1
2
E1
8
28
36
E2
37
104
141
E3
59
126
185
E4
20
52
72
E5
2
6
8
E6
1
0
1
TOT
128
317
445
Tabla de frecuencias relativas:
F
M
TOT
E0
0.002
0.002
0.004
E1
0.018
0.063
0.081
E2
0.083
0.234
0.317
E3
0.133
0.283
0.416
E4
0.045
0.117
0.162
E5
0.004
0.013
0.018
E6
0.002
0.000
0.002
TOT
0.288
0.712
1.000
8.1.6 Probabilidad condicional
¿Cómo responderías a lo siguiente?
Si se selecciona un admitido “al azar”, ¿cuál es la probabilidad de que sea de género masculino, pero dado que (si se sabe que) es de estrato 1?
F
M
TOT
E0
1
1
2
E1
8
28
36
E2
37
104
141
E3
59
126
185
E4
20
52
72
E5
2
6
8
E6
1
0
1
TOT
128
317
445
Los valores al interior de una tabla de perfiles fila son probabilidades condicionales:
F
M
Sum
E0
0.50
0.50
1
E1
0.22
0.78
1
E2
0.26
0.74
1
E3
0.32
0.68
1
E4
0.28
0.72
1
E5
0.25
0.75
1
E6
1.00
0.00
1
marg.Genero
0.29
0.71
1
¿Que pareja (estrato, género) tiene la proporción más parecida a la proporción global del respectivo género (marg.Genero)?
¿Y si ahora cambiamos la pregunta?
Si se selecciona un admitido “al azar”, ¿cuál es la probabilidad de que sea de estrato 1, pero dado que (si se sabe que) es de género masculino?
F
M
TOT
E0
1
1
2
E1
8
28
36
E2
37
104
141
E3
59
126
185
E4
20
52
72
E5
2
6
8
E6
1
0
1
TOT
128
317
445
Los valores al interior de una tabla de perfiles columna son las otras posibles probabilidades condicionales:
F
M
marg.ESTADO
E0
0.008
0.003
0.004
E1
0.062
0.088
0.081
E2
0.289
0.328
0.317
E3
0.461
0.397
0.416
E4
0.156
0.164
0.162
E5
0.016
0.019
0.018
E6
0.008
0.000
0.002
Sum
1.000
1.000
1.000
¿Que pareja (estrato, género) tiene la proporción más parecida a la proporción global del respectivo estrato (marg.Estrato)?
8.1.7 Independencia
Dos eventos A y B son independientes si y sólo si cualquiera de las siguientes tres igualdades se cumple (si una se cumple, entonces ya se sabe que las otras dos también se van a cumplir):
“La probabilidad de A se mantiene igual, sin importar que ocurra B”
P[A|B] = P[A]
“La probabilidad de B se mantiene igual, sin importar que ocurra A”
P[B|A] = P[B]
“La probabilidad de la intersección de dos eventos coincide con el producto de las probabilidades de los dos eventos”
En un proceso de revisión de un examen nacional, cuatro evaluadores especializados revisan las respuestas de los estudiantes a una pregunta abierta. Laura revisa el 30\% de las respuestas y comete un error en su calificación en 1 de cada 250. Carlos revisa el 25\% y se equivoca en 1 de cada 400. Diana revisa el 35\% y se equivoca en 1 de cada 300. Jorge revisa el 10\% y se equivoca en 1 de cada 150.
Si alguien se da cuenta que un examen tiene un error en su calificación, ¿cuál es la probabilidad de que haya sido uno de los que revisó Diana?
A partir de unas condicionales conocidas, la regla de Bayes me permite obtener una condicional con los eventos “al contrario”.
Sería como obtener un valor de una tabla de perfiles fila a partir de los valores de una tabla de perfiles columna, o viceversa.
Esta relación matemática puede entenderse también como una forma general de usar la información para revisar lo que creemos.
En la vida cotidiana tomamos decisiones con base en lo que sabemos, pero ajustamos nuestras creencias cuando obtenemos nueva evidencia.
Si algo parecía poco probable y luego encontramos señales que lo respaldan, su probabilidad aumenta; si la evidencia lo contradice, disminuye.
En el ámbito de la inteligencia artificial, esta misma lógica permite que los sistemas “aprendan de la experiencia” y mejoren sus predicciones al incorporar nueva información.
La regla de Bayes, en última instancia, permite razonar bajo incertidumbre, combinando el conocimiento previo con los datos recientes para llegar a conclusiones más cercanas a la realidad.
Imaginemos que no sabemos si una moneda es justa, de tal manera que salga cara la mitad de las veces. Nuestro conocimiento previo es lo que supongamos inicialmente acerca de la moneda. Si empezamos a lanzarla y consideramos lo que vamos observando (por ejemplo, que en los primeros intentos aparece cara más veces de lo esperado), es posible que ajustemos nuestra creencia inicial sin reemplazarla por completo. Cada nuevo lanzamiento modifica ligeramente nuestra estimación sobre el equilibrio de la moneda, porque los datos recientes se integran con lo que creíamos inicialmente. Es precisamente la regla de Bayes quien nos permitiría realizar con precisión los cálculos matemáticos asociados.
8.1.9 Variables aleatorias
Cuando hablamos de estadística descriptiva mencionamos la idea, concepto o definición de variable. Después de ello, acabamos de hablar de probabilidad de un suceso o evento (es decir, probabilidad de un conjunto).
Mediante el concepto de variable aleatoria podemos unir esos dos elementos, y así poder hablar de la probabilidad de que una variable tome un cierto valor o conjunto de valores.
X : “¿El género del admitido es femenino? Si (1), No (0)”
flowchart LR
A(Masculino) --> A0(0)
B(Femenino) --> B1(1)
La probabilidad de que el género de un admitido seleccionado “al azar” sea femenino ahora se puede escribir como: P[X = 1]
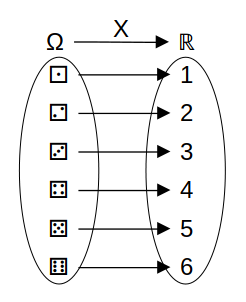
Una variable aleatoria es una representación o asociación numérica para los resultados de un experimento aleatorio.
Para la variables cualitativas / categóricas, es necesario indicar la asociación que usaremos.
Y : “El lugar de origen de un admitido. Bogotá (0), Cundinamarca (1), u Otro (2)”
Los posibles valores de la variable aleatoria Y son:
y = 0, 1, 2
¿Cómo podría escribir la probabilidad de que un admitido seleccionado “al azar” no sea de Bogotá, usando la variable aleatoria Y?
P[ \; Y \qquad ¿? \qquad ]
Para las variables numéricas, la asociación es obvia.
W : “Número de hospitales de primer nivel en el municipio”
w = 0, 1, 2, 3, \dots
¿Cuál es la probabilidad de que un municipio seleccionado “al azar” tenga más de un hospital de primer nivel?
P[ \; W \qquad ¿? \qquad ]
Z : “Área del territorio municipal”
z > 0
¿Cuál es la probabilidad de que un municipio seleccionado “al azar” tenga un área de menos de mil kilómetros cuadrados?
P[ \; Z \qquad ¿? \qquad ]
8.1.10 Clasificación de las v. a.
Las variables aleatorias se clasifican en dos grupos:
Discretas: Si el conjunto de posibles valores para la variable aleatoria es finito o infinito al estilo de los números enteros (infinito numerable).
Continuas: Si el conjunto de posibles valores para la variable aleatoria es infinito al estilo de los números reales (infinito no numerable).
8.1.11 Probabilidad para una v.a.
Sea X : “¿El género del admitido es femenino? Si (1), No (0)”
x = 0, 1
¿Cuál es la probabilidad de que el género del admitido seleccionado al azar sea femenino?
P[X = 1] = ¿?
Genero
frec.abs.
frec.rel.
F
128
0.29
M
317
0.71
TOTAL
445
1.00
Si selecciono un admitido al azar, luego selecciono otro dejando participar en la selección al que me salió antes, luego selecciono otro dejando participar en la selección a los dos que me salieron antes ¿cuál es la probabilidad de que haya seleccionado un total de tres admitidos de género femenino? ¿un total de dos? ¿un total de uno? ¿un total de cero?
. . .
X : “Número total de admitidos de género femenino en la selección realizada”
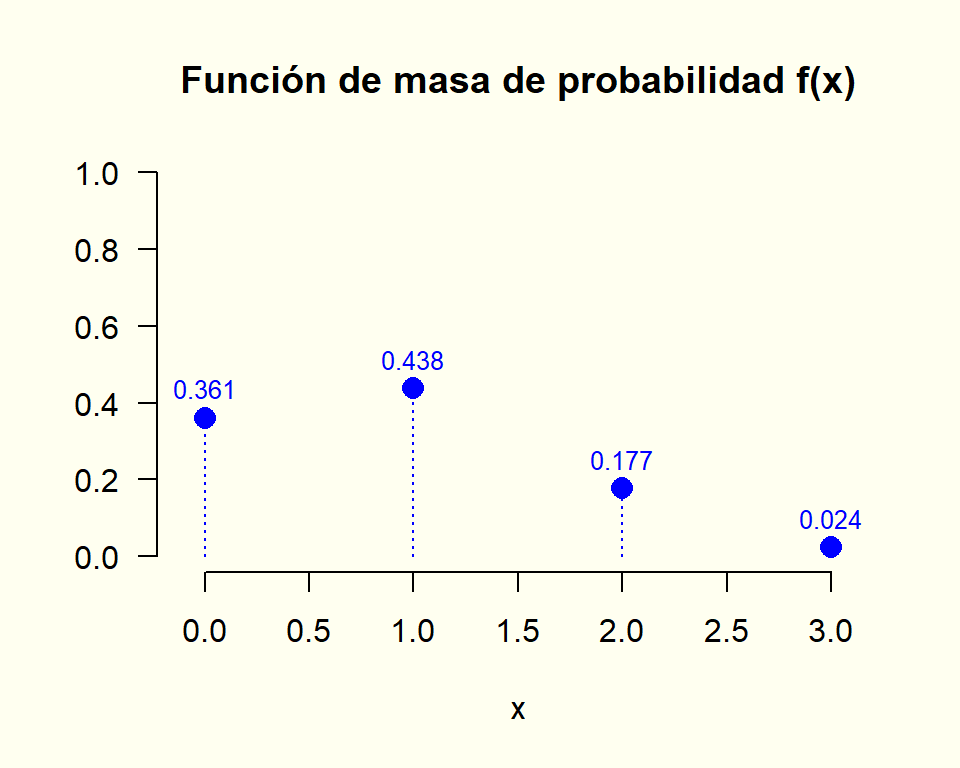
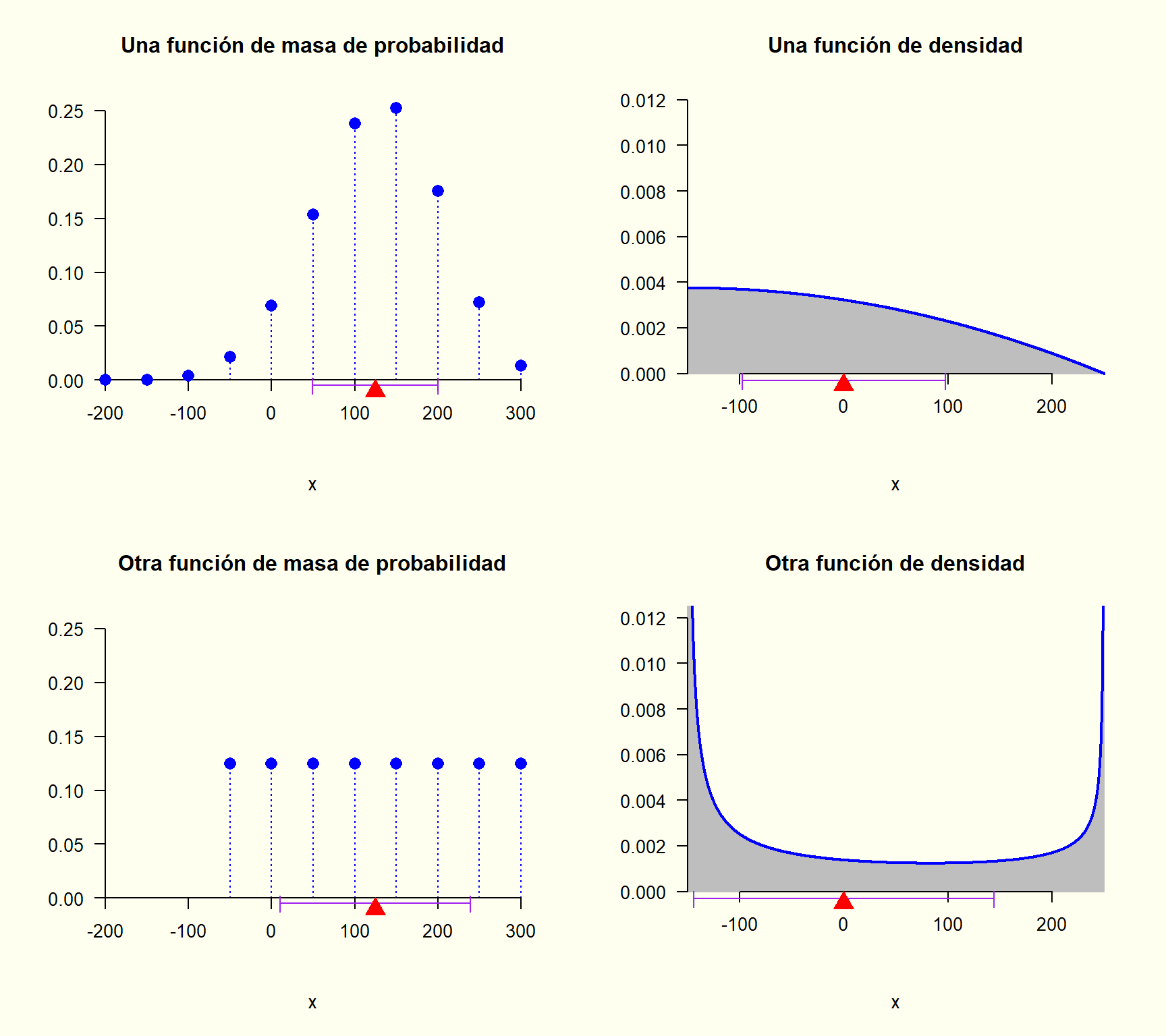
8.1.12 Función de masa de probabilidad (v.a. discreta)
La función de masa de probabilidad \left(f(x)\right) (de una variable aleatoria discreta) se puede ver como la tabulación de todas las probabilidades relevantes.
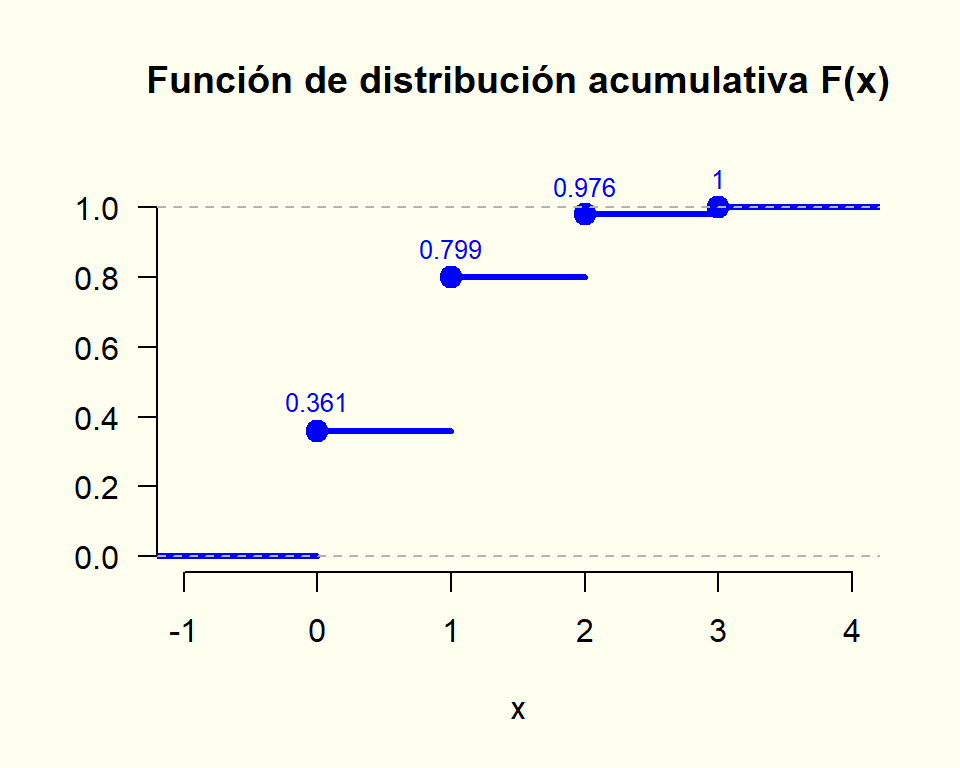
X : “Número total de admitidos de género femenino en la selección realizada”
valor (x)
probabilidad \left(f(x) = P[X = x]\right)
0
0.36
1
0.44
2
0.18
3
0.02
8.1.13 Función de distribución acumulativa (v.a. discreta)
La función de distribución acumulativa \left(F(x)\right) es la probabilidad que llevo acumulada hasta cierto valor sobre el eje x.
X : “Número total de admitidos de género femenino en la selección realizada”
Sea una variable aleatoria X definida como el tiempo que toca esperar para que ocurra un cierto evento (por ejemplo, el tiempo que una persona debe esperar a un familiar o amigo en un punto de encuentro).
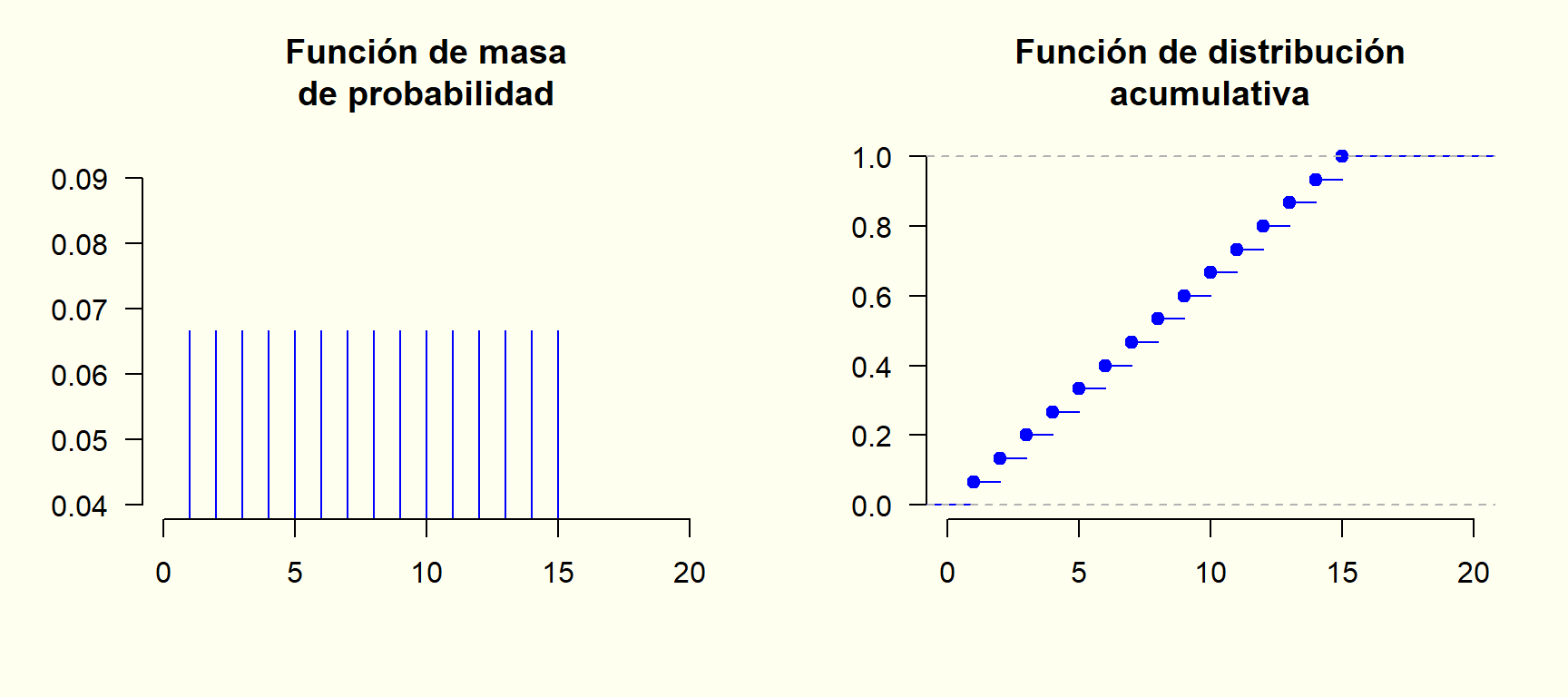
Supongamos que una persona errónea o incorrectamente considera la variable como discreta, con valores posibles x = 1, 2, \dots, 15 minutos, todos igualmente probables. En ese caso:
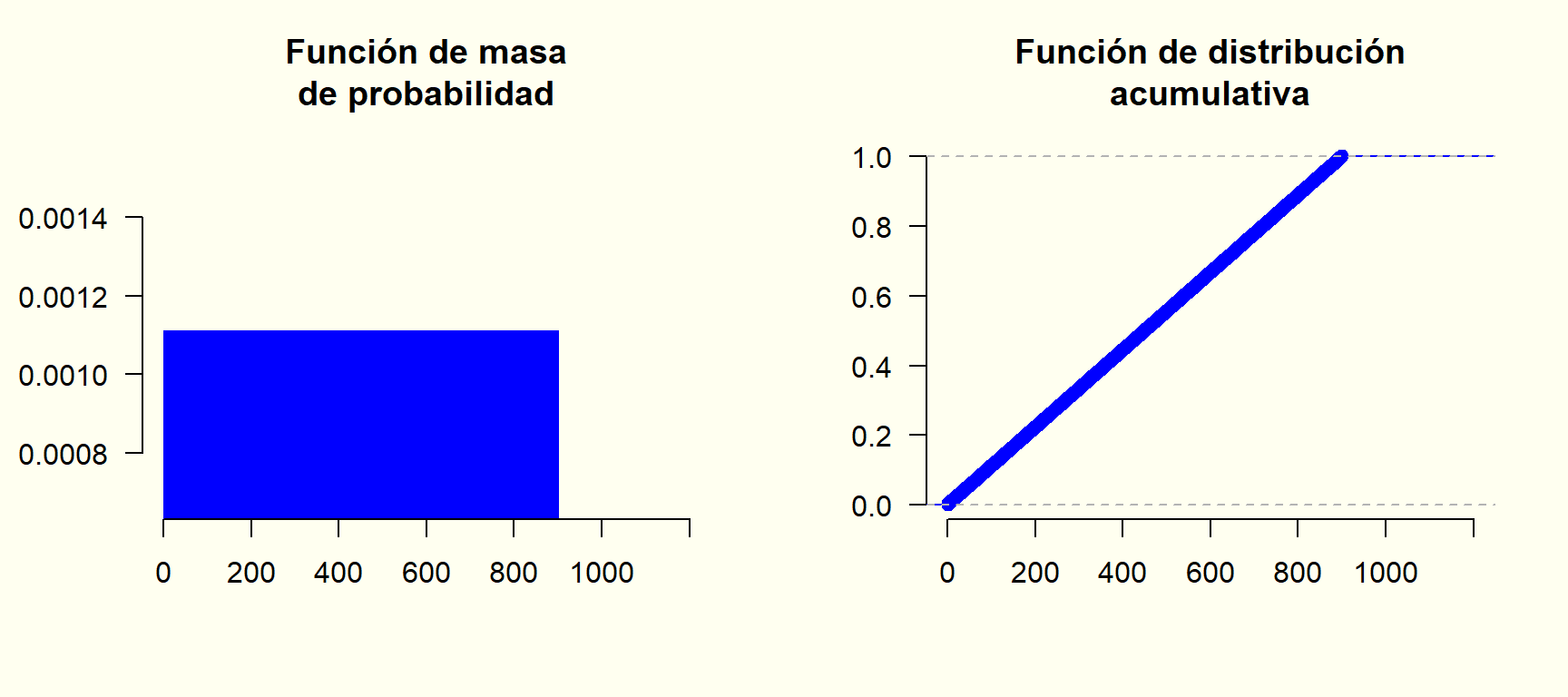
Ahora, supongamos que esta persona empieza a notar que algo no encaja, e intenta corregir el error pasando de minutos a segundos. Asume entonces, también de forma incorrecta, que la variable aleatoria es discreta con valores x=1,2,\dots,900 segundos, todos igualmente probables. En ese caso:
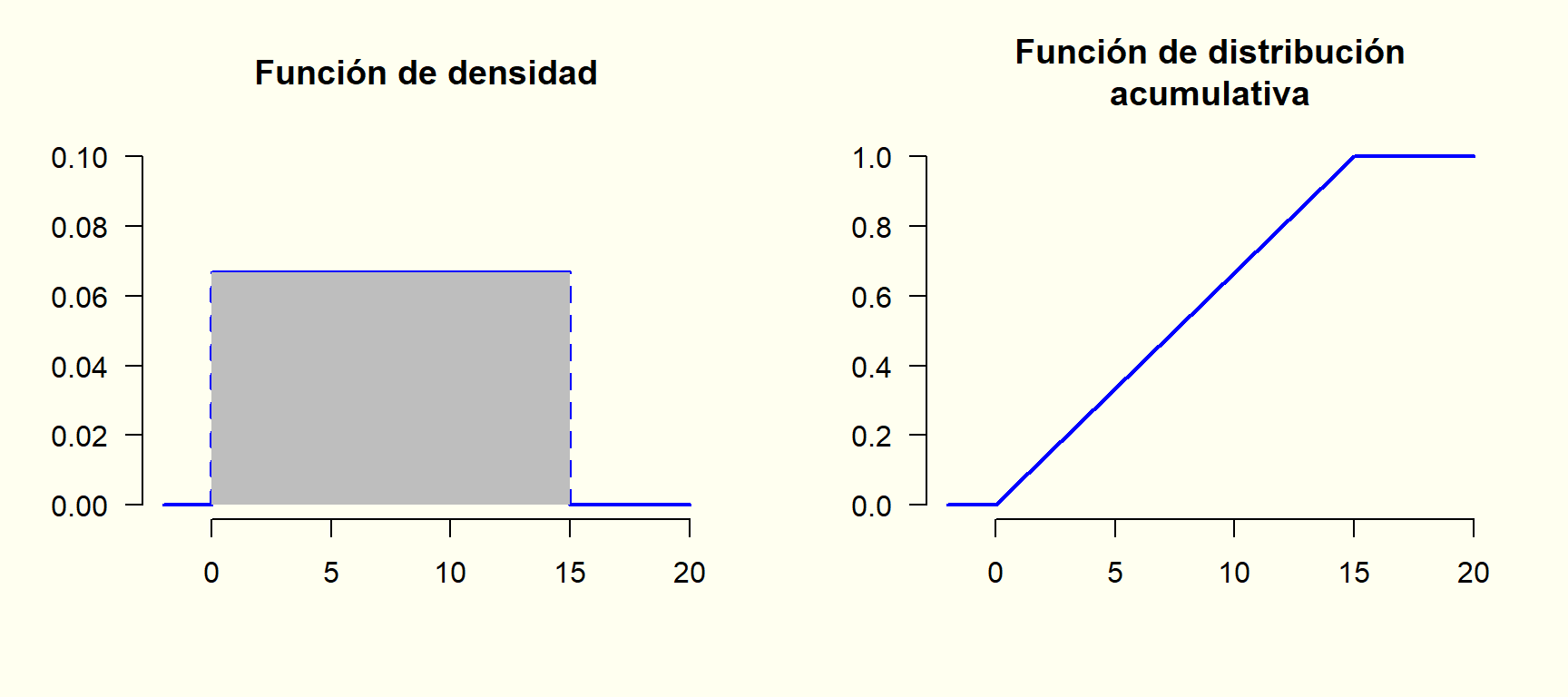
Finalmente, la persona se da cuenta de que el verdadero error es haber tratado como discreta una variable que en realidad es continua. Desde estadística descriptiva ya sabemos que una variable asociada al tiempo es cuantitativa continua, con escala de razón. No obstante, gracias al error cometido, podemos imaginar qué ocurre al dividir el tiempo en unidades cada vez más pequeñas, hasta llegar a valores infinitesimales. El tiempo de espera puede variar infinitesimalmente entre 0 y 15 minutos (0<x<15), con igual probabilidad. En ese caso:
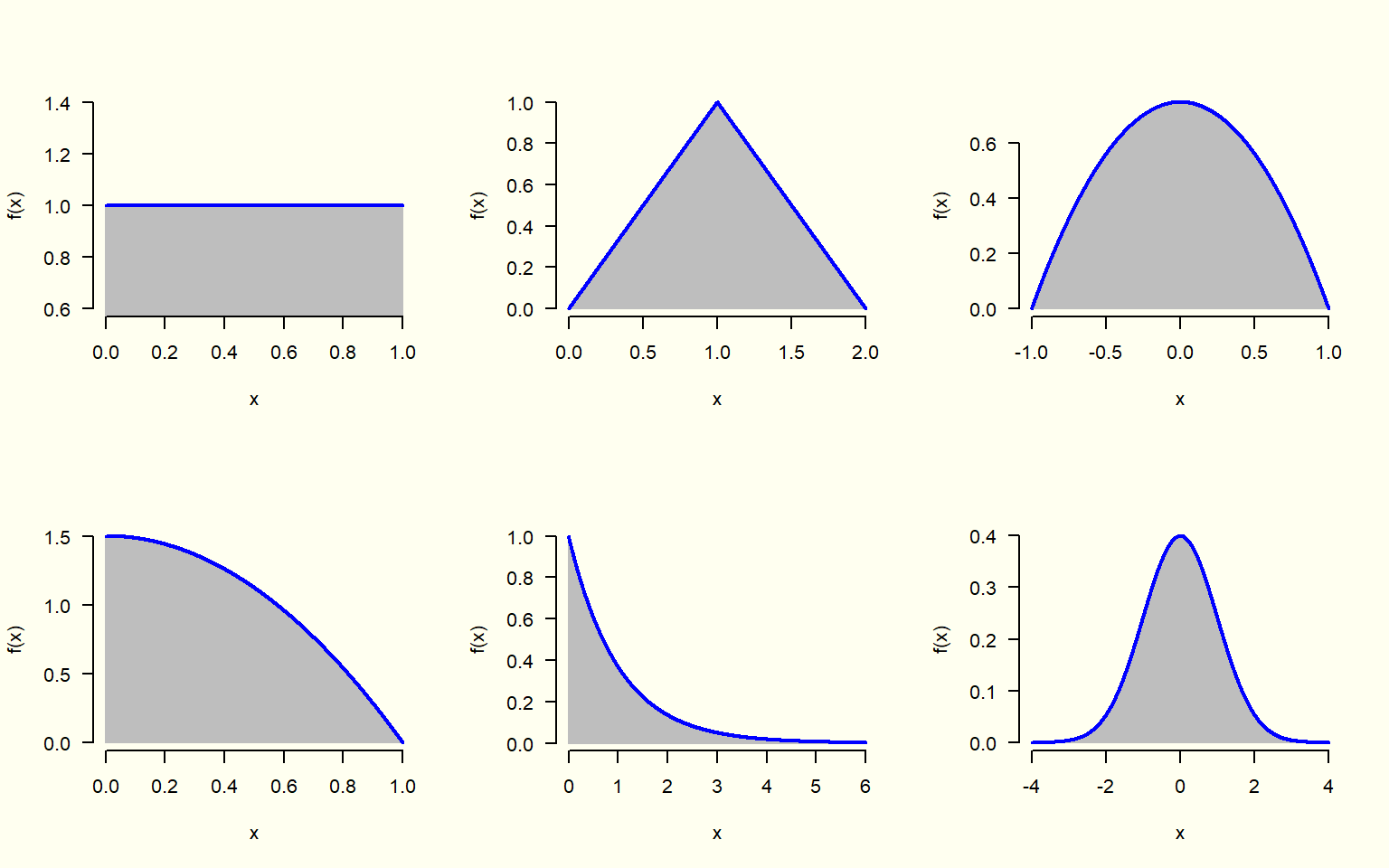
Cualquier función, que nunca tome valores negativos (es decir, f(x) \geq 0 para todo x \in \mathbb{R}), y cuya área total bajo la curva sea igual a 1 (es decir, \int_{\mathbb{R}} f(x) \, dx = 1), puede ser utilizada como una función de densidad de probabilidad.
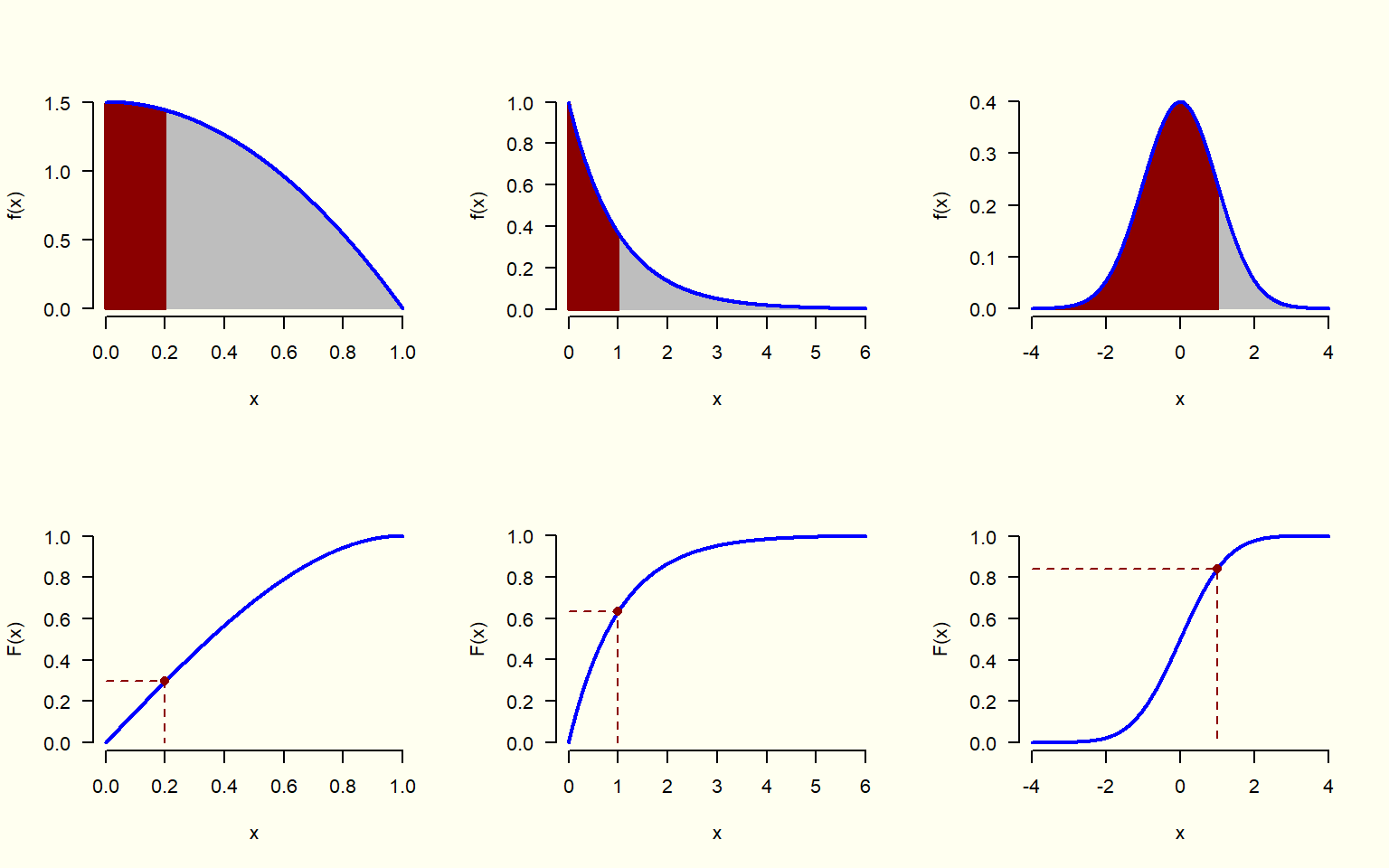
8.1.15 Función de distribución acumulativa (v.a. continua)
La función de distribución acumulativa \left(F(x)\right) es el área (es decir, la probabilidad) que llevo acumulada hasta cierto valor sobre el eje x.
8.1.16 Algunas conclusiones
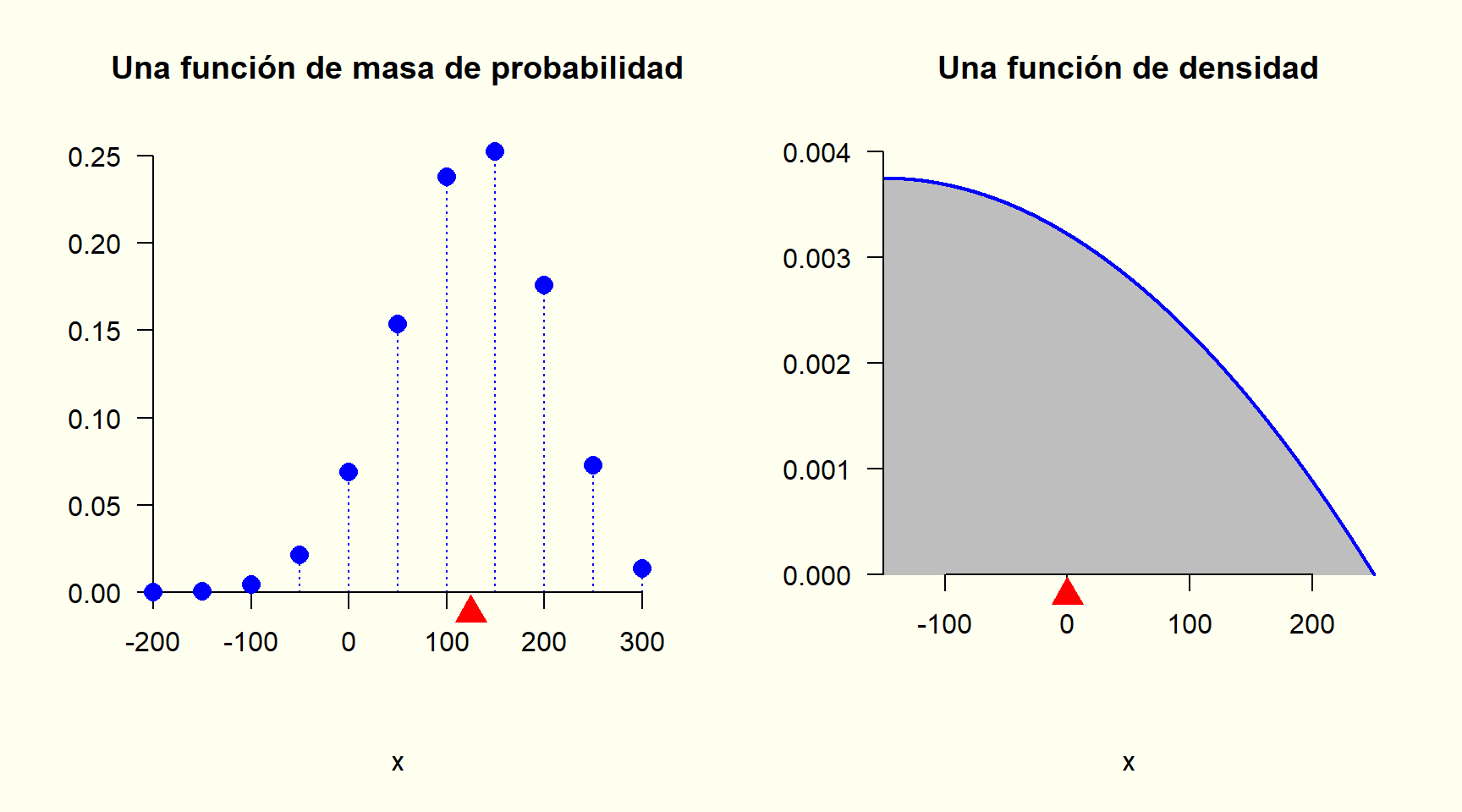
Basta con conocer la función de distribución acumulativa o la función de masa de probabilidad de una variable aleatoria discreta (la función de densidad en el caso de una variable aleatoria continua), para conocer por completo el mecanismo aleatorio que rige a la variable y a su correspondiente experimento aleatorio. Por lo tanto, si tengo cualquiera de estas dos funciones, entonces puedo calcular cualquier probabilidad que desee.
También podemos concluir que las tablas de frecuencias relativas y relativas acumuladas nos están dando la función de masa de probabilidad y la función de distribución acumulativa correspondiente a la variable aleatoria más simple de obtener a partir de una variable de interés de una tabla de datos (la v.a. asociada a la selección de un solo individuo al azar).
Para las variables aleatorias continuas, se “teorizará” acerca de las funciones que rigen la variable y se supondrá que la variable tiene una cierta función de densidad o de distribución acumulativa.
8.1.17 Promedio para una v.a.
Si una persona invierte en unas acciones en particular, en un año tiene una probabilidad de 0.3 de obtener una ganancia de $4000 o una probabilidad de 0.7 de tener una pérdida de $1000. ¿Cuál es la ganancia esperada de esta persona? Tomado de: Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 4.7.
Suponga que un distribuidor de joyería antigua está interesado en comprar un collar de oro para el que tiene 0.22 de probabilidades de venderlo con $250 de utilidad; 0.36 de venderlo con $150 de utilidad; 0.28 de venderlo al costo y 0.14 de venderlo con una pérdida de $150. ¿Cuál es su utilidad esperada? Tomado de: Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 4.8.
En ambos casos debemos obtener el promedio, también llamado valor esperado o esperanza, de una variable aleatoria adecuada para la situación.
Si una persona invierte en unas acciones en particular, en un año tiene una probabilidad de 0.3 de obtener una ganancia de $4000 o una probabilidad de 0.7 de tener una pérdida de $1000. ¿Cuál es la ganancia esperada de esta persona? Tomado de: Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 4.7.
X : “¿Obtiene ganancia? Si (1), No (0)”
Y : “Cantidad que gana la persona (valores negativos indican pérdida)”
valores de x
probabilidades
valores de y
0
0.7
-1000
1
0.3
4000
El promedio de la v.a. Y (la ganancia esperada) es, \mu_Y = E[Y] = (-1000)(0.7) + (4000)(0.3) = \$ 500
Suponga que un distribuidor de joyería antigua está interesado en comprar un collar de oro para el que tiene 0.22 de probabilidades de venderlo con $250 de utilidad; 0.36 de venderlo con $150 de utilidad; 0.28 de venderlo al costo y 0.14 de venderlo con una pérdida de $150. ¿Cuál es su utilidad esperada? Tomado de: Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 4.8.
Z : “Monto de la utilidad”
valores de z
probabilidades
-150
0.14
0
0.28
150
0.36
250
0.22
El promedio de la v.a. Z (la utilidad esperada) es, \mu_Z = E[Z] = ¿?
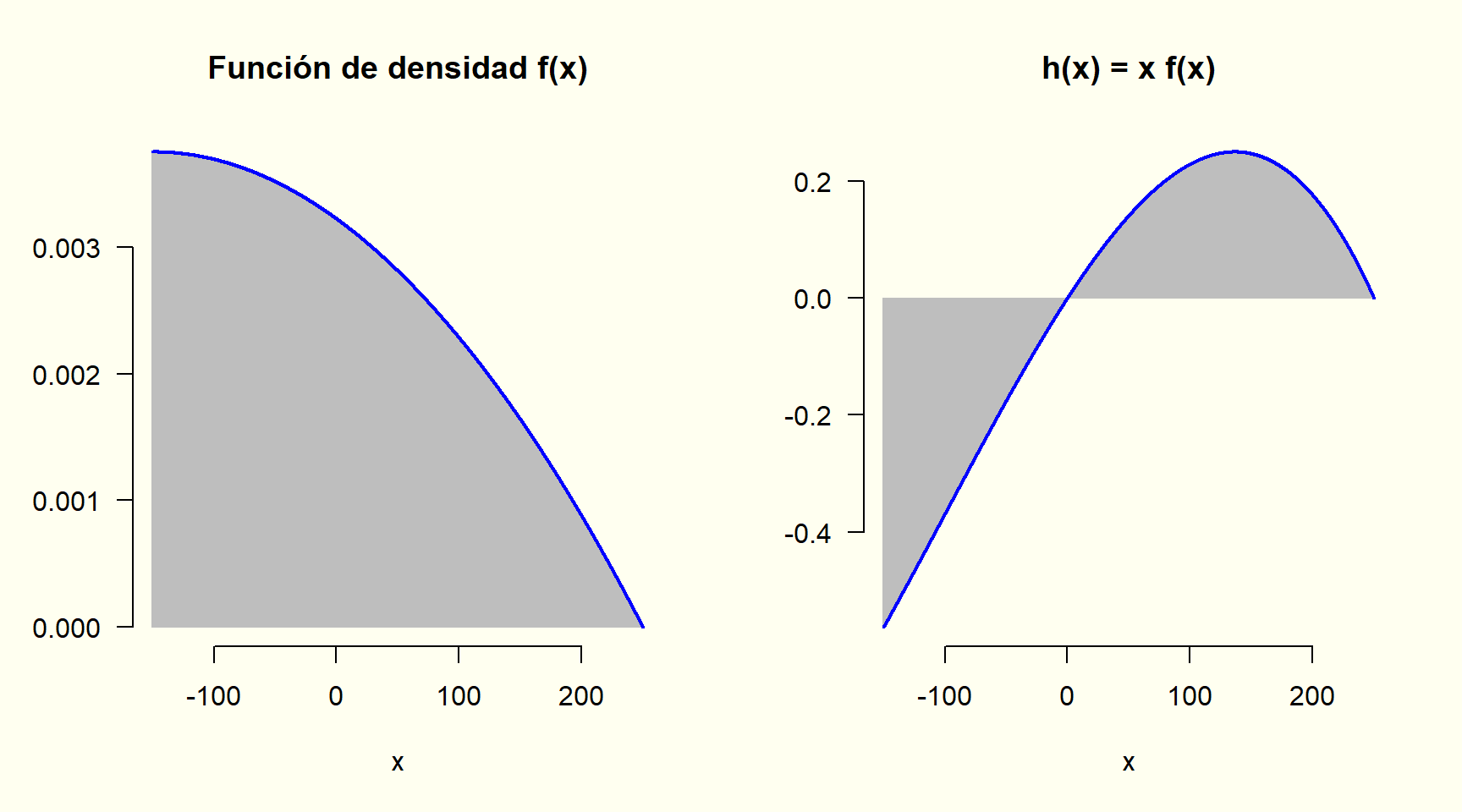
Supongamos que la utilidad en la compra del collar de oro esta dada por los valores continuos que puede tomar un x (por ejemplo, -150 < x < 250) y que las probabilidades asociadas a esos valores continuos de x están asociadas a una función de densidad f(x), entonces el promedio (media, valor esperado o esperanza) de la utilidad sería el área total bajo la curva de la función h(x) = (x) \big( f(x) \big) (al área por debajo del eje x tiene signo negativo).
El promedio (media, valor esperado o esperanza) de una variable aleatoria se puede interpretar como punto de equilibrio.
8.1.18 Varianza para una v.a.
Así como se puede calcular el promedio para una variable aleatoria, también se puede obtener su varianza, y por ende su desviación estándar. Estas medidas dan cuenta de la variabilidad, con respecto a la media, de los valores que puede tomar la variable aleatoria (teniendo en cuenta adecuadamente las diferentes probabilidades / ponderaciones de los valores que toma la v.a.).
8.1.19 Cuantiles para una v.a.
Encuentre el tercer cuartil (cuantil 0.75).
Para una variable aleatoria continua:
En este caso el tercer cuartil es igual a 182.94.
8.1.20 Distribuciones discretas
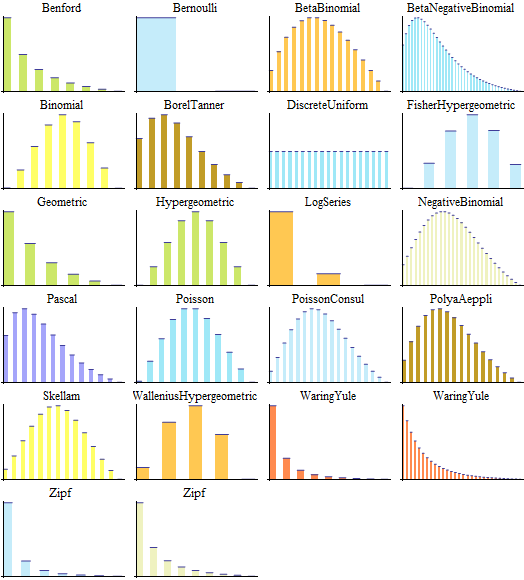
Dentro de las distribuciones discretas existen modelos particulares que representan distintos tipos de situaciones aleatorias.
Cada uno surge de condiciones específicas del experimento —como la forma en que se repiten los intentos o si hay o no reemplazo en las extracciones— y permite describir con precisión cómo se distribuyen los resultados posibles.
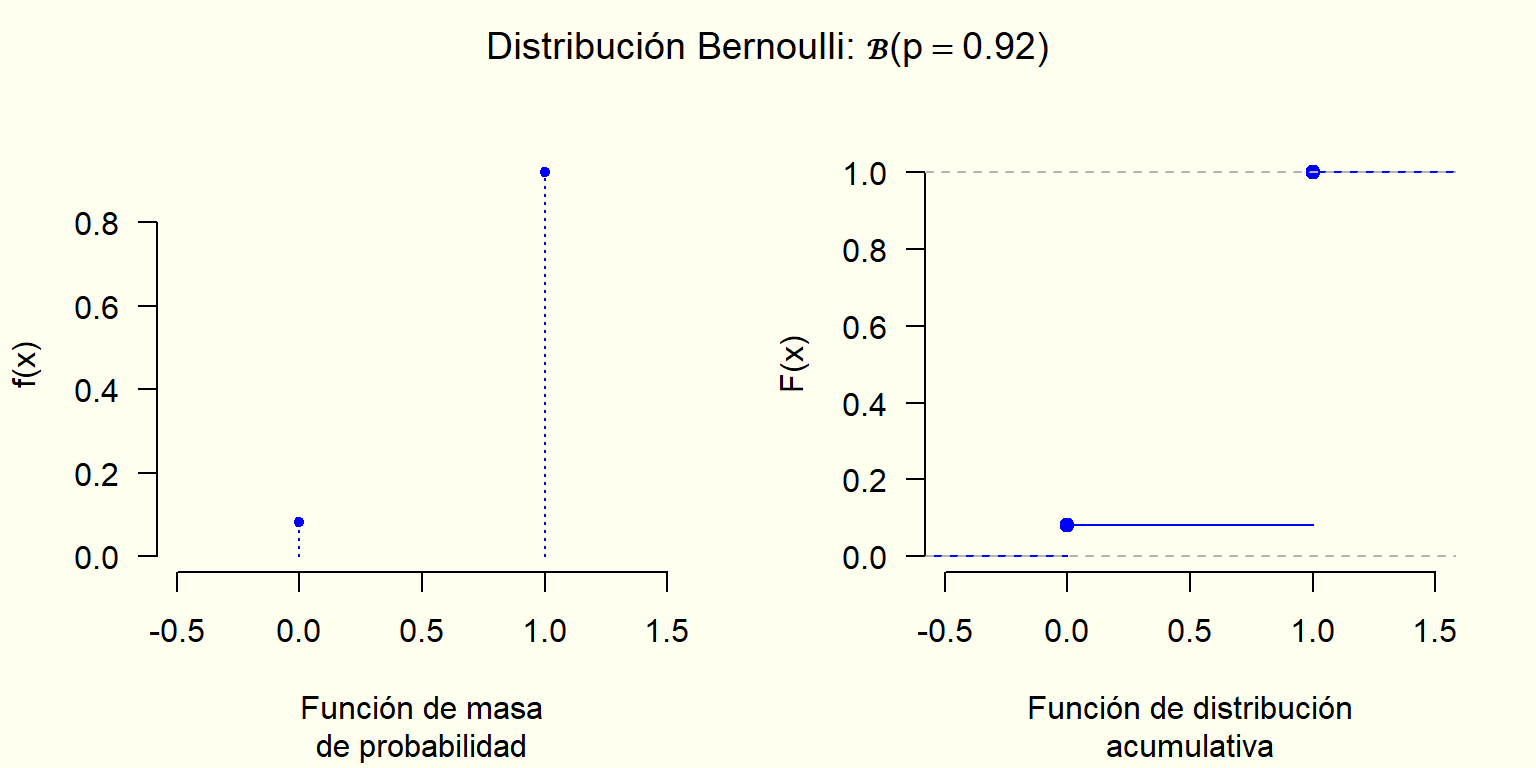
8.1.20.1 Distribución Bernoulli
Algunas situaciones en donde aplica:
Variables de: Si - No, Falso - Verdadero, Presencia - Ausencia, etc.
Seleccionar un individuo, elemento, o registro y ver si tiene o no una característica de interés, o si su valor está o no en un intervalo de interés.
Características: La variable aleatoria sólo toma dos posibles valores.
Valores que puede tomar la variable:x=0,1
Parámetro: probabilidad del uno (1), considerada la “probabilidad de éxito” \left(p \in [0,1]\right)
¿Cuál es la probabilidad de que el género de un admitido seleccionado al azar sea femenino? ¿Cuál es la probabilidad de que no lo sea? X : “¿El género del admitido seleccionado es femenino? Si (1), No (0)” x = 0, 1
Si selecciono un admitido al azar, luego selecciono otro dejando participar en la selección al que me salió antes, luego selecciono otro dejando participar en la selección a los dos que me salieron antes ¿cuál es la probabilidad de que haya seleccionado un total de tres admitidos de género femenino? ¿un total de dos?… X : “Número total de admitidos de género femenino en la selección realizada” x = 0, 1, 2, 3
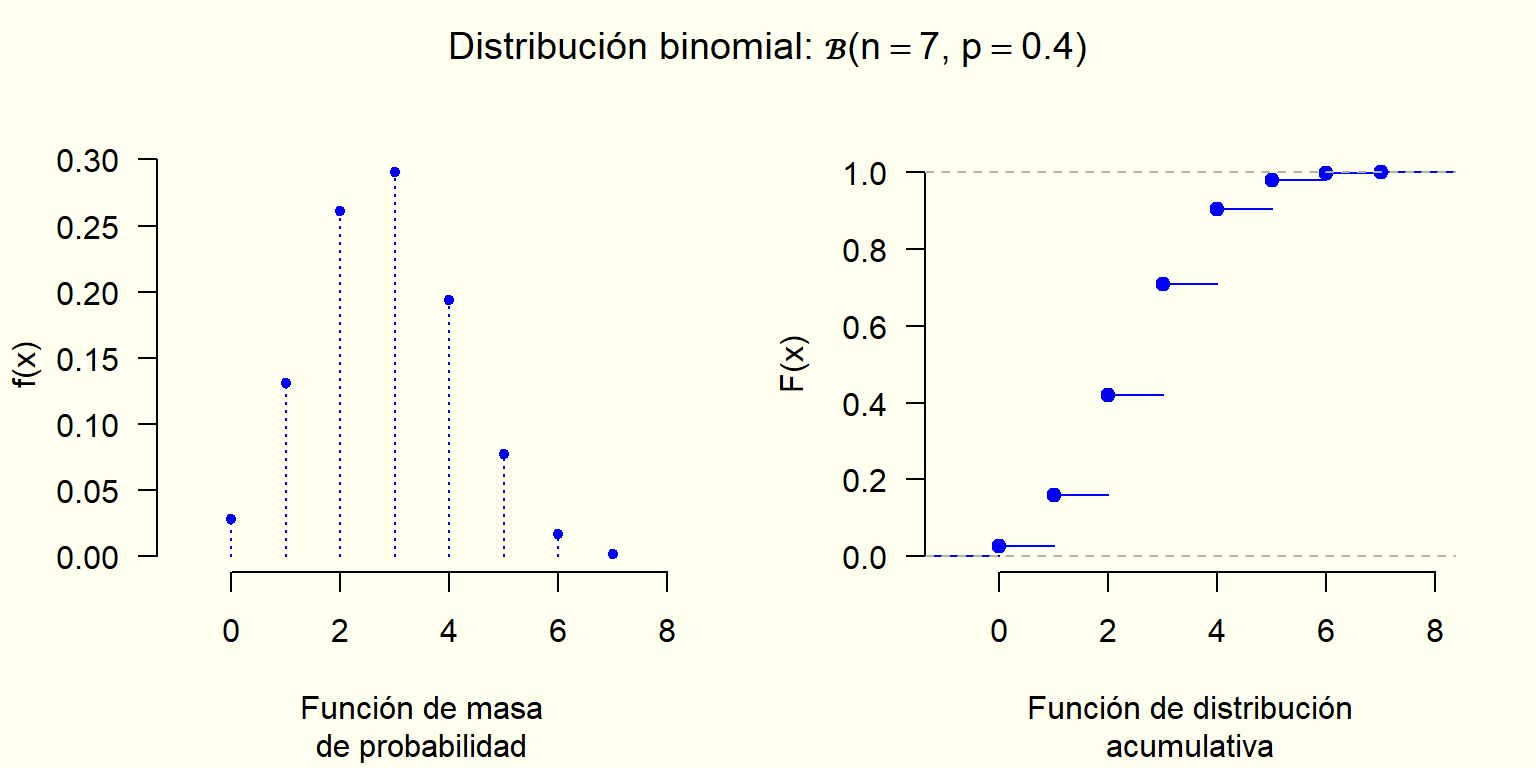
Características: La variable aleatoria corresponde al número de “aciertos” de un experimento Bernoulli que se repite exactamente un número de veces y donde la probabilidad del resultado de cada repetición no depende del resultado de las otras repeticiones, es decir, los resultados de cada repetición son independientes entre sí.
Valores que puede tomar la variable:x=0,1,...,n
Parámetros: Número de repeticiones y “probabilidad de éxito” de cada repetición.
En una hoja de cálculo: DISTR.BINOM.N(núm_éxito; ensayos; prob_éxito; acumulado)
Valor esperado:\mu_X=E[X]=np
Desviación estándar:\sigma_X=SD[X]=\sqrt{np(1-p)}
La distribución Bernoulli se puede ver como un caso particular de la distribución binomial, caso en el que se realiza una única repetición \left(n = 1\right).
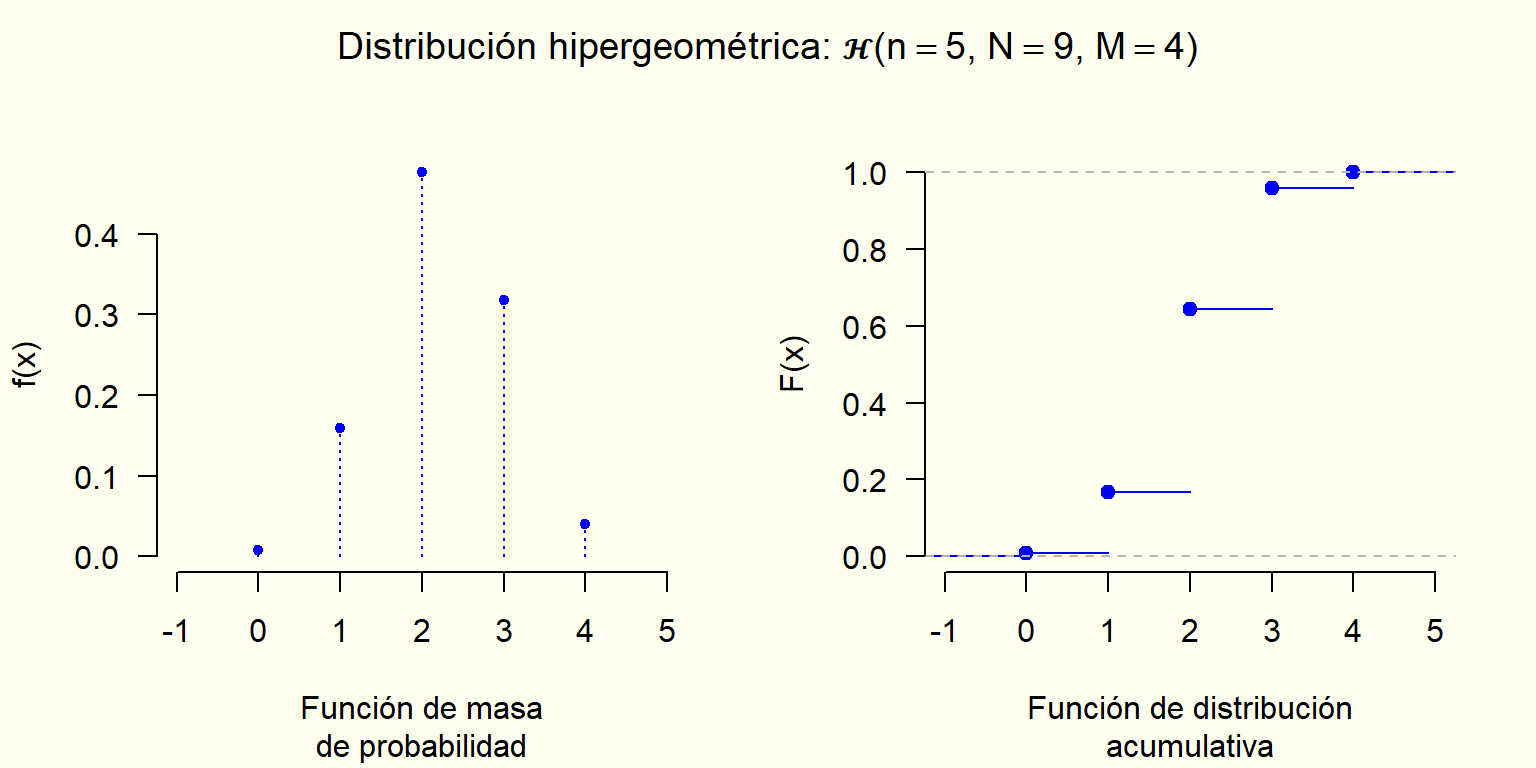
8.1.20.3 Distribución hipergeométrica
Si selecciono un admitido al azar, luego selecciono otro SIN dejar participar en la selección al que me salió antes, luego selecciono otro dejando SIN dejar participar en la selección a los dos que me salieron antes ¿cuál es la probabilidad de que haya selecionado un total de tres admitidos de género femenino? ¿un total de dos?… X : “Número total de admitidos de género femenino en la selección realizada” x = 0, 1, 2, 3
Características: Similar a las características de la variable binomial pero seleccionando sin reemplazamiento o simultáneamente, es decir, sin independencia.
Valores que puede tomar la variable: Depende de los parámetros, pero en todo caso enteros no negativos.
Parámetros: Número de seleccionados \left(n\right), número en total con la característica de interés \left(M\right) y número total de donde se hizo la selección \left(N\right).
En una hoja de cálculo: DISTR.HIPERGEOM.N(...)
X : “Número de individuos, registros, elementos con cierta característica obtenidos al extraer, simultáneamente o sin reemplazamiento, n de un lote de N, donde se sabe que M de los N tienen una cierta característica”.
Entre las distribuciones continuas se encuentran modelos fundamentales que describen distintos comportamientos de variables aleatorias en dominios continuos.
Cada modelo se define por una función de densidad con propiedades particulares que reflejan la forma en que (teóricamente) se concentraría o dispersaría las probabilidades a lo largo del eje real.
8.1.21.1 Distribución gaussiana (normal)
Algunas situaciones en donde aplica:
Características morfológicas de individuos como la estatura.
Características fisiológicas como el efecto de un fármaco.
Características sociológicas como el consumo de cierto producto por un mismo grupo de individuos.
Características psicológicas como el cociente intelectual.
Nivel de ruido en telecomunicaciones.
Errores cometidos al medir ciertas magnitudes.
En aspectos teóricos y aplicados propios de la estadística y la ciencia de datos.
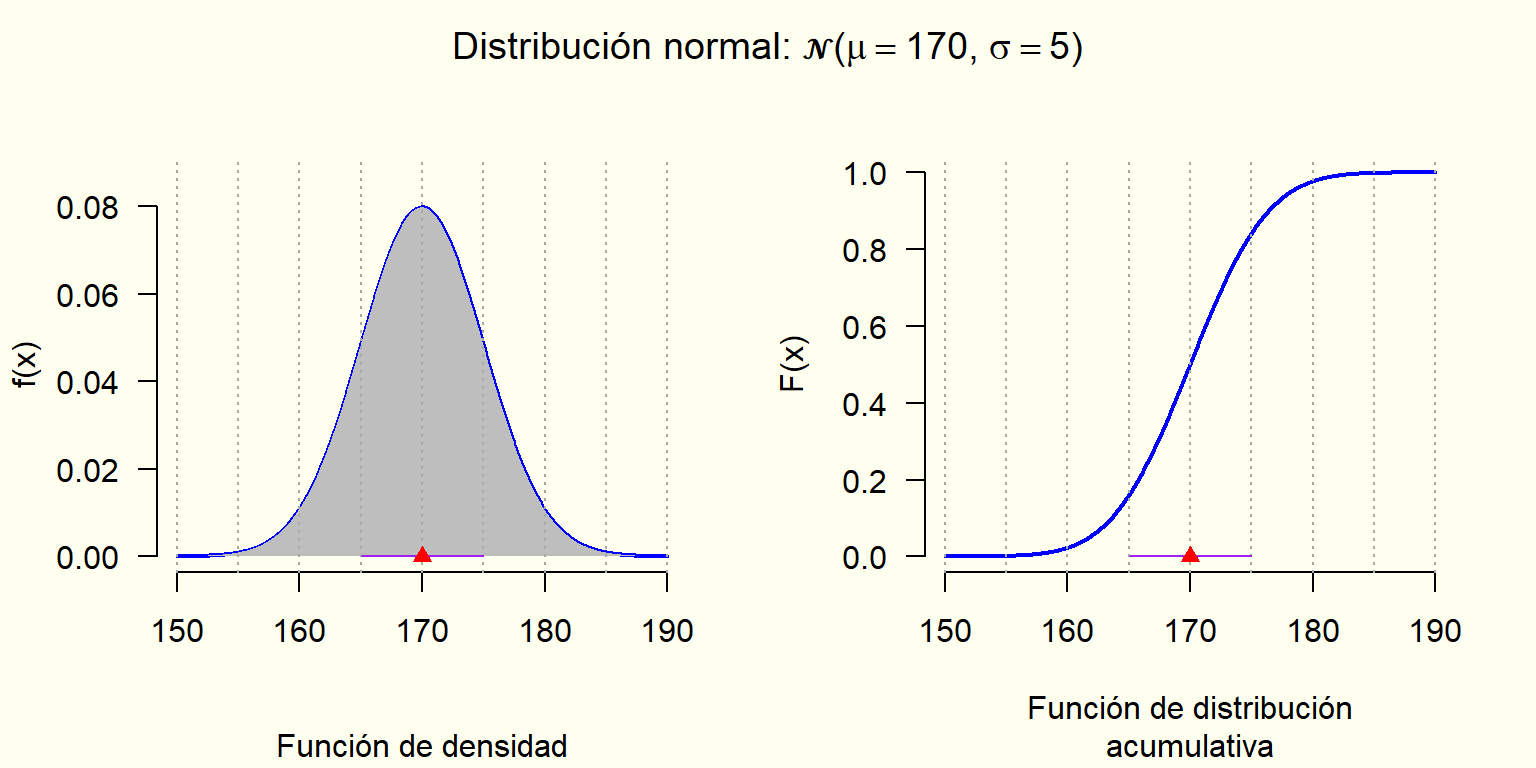
Características: La gráfica de su función de densidad tiene una forma acampanada (campana de Gauss) y es simétrica con respecto a la media.
Valores que puede tomar la variable: Todos los números reales, pero con muy baja probabilidad al alejarse lo suficiente de la media.
Parámetros: media \left(\mu\right) y desviación estándar \left(\sigma\right)
Cuando la media es igual a cero (0) y la desviación estándar igual a uno (1), se dice que la distribución es normal estándar.
En una hoja de cálculo:
DISTR.NORM.N(x; media; desv_estándar; acum)
INV.NORM(probabilidad; media; desv_estándar)
Supongamos que la estatura media de los hombres adultos en cierto país es de aproximadamente 177.8 cm, con una desviación estándar de alrededor de 7.62 cm.
Si asumo que la estatura tiene distribución gaussiana,
¿qué porcentaje de los hombres adultos de ese país tendrán una estatura entre 162.56 y 193.04 cm?
¿entre qué estaturas estaría el 90\% central de las estaturas de los hombres adultos de ese país?
8.1.22 Ampliar o complementar
El contenido de esta subsección se puede ampliar o complementar con lo que se encuentra en las siguientes páginas:
En R:
Para consultar la ayuda acerca de las distribuciones incorporadas en la instalación base de R, dar la instrucción: ?distributions.
Para una referencia más amplia, que va más allá de la instalación base en R, ir a:
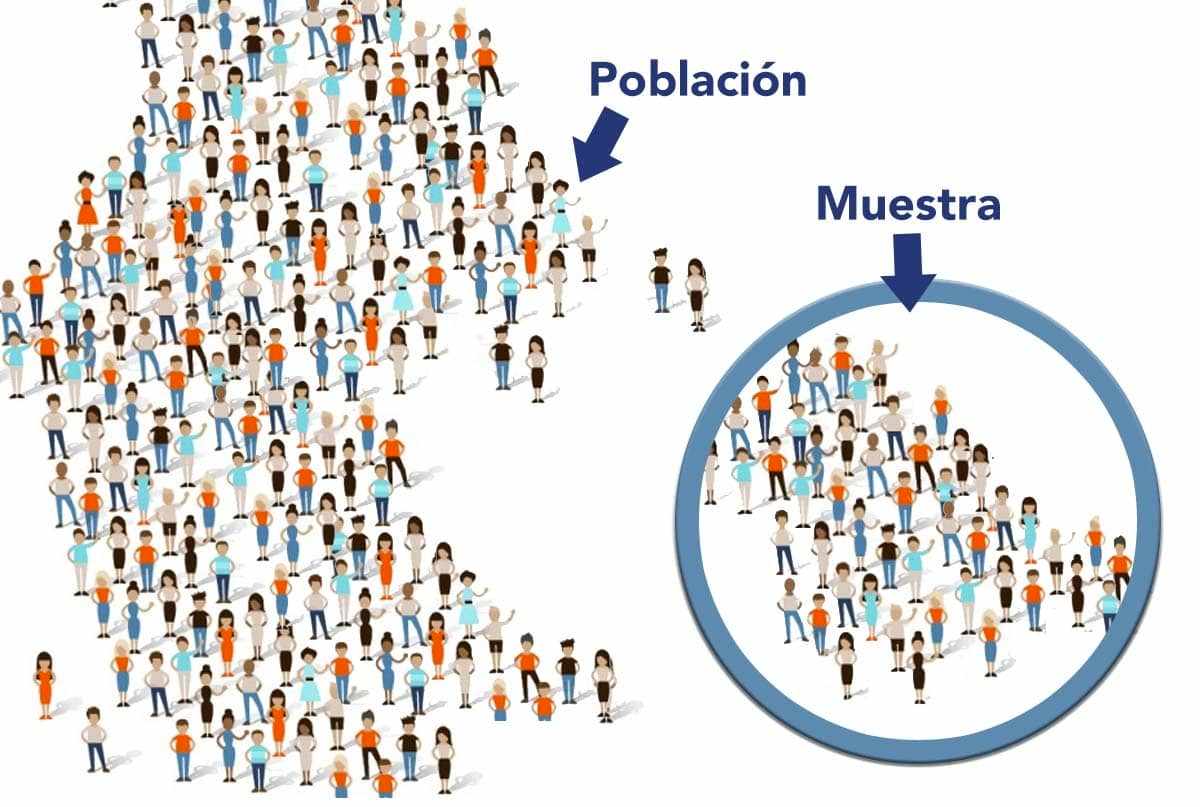
8.2 De lo muestral inferir lo poblacional: Inferencia Estadística
Recordemos la relación entre conceptos y definiciones:
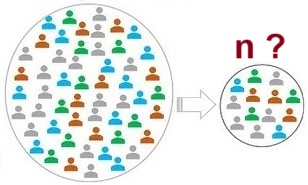
8.2.1 Muestreo
8.2.1.1 Muestreo aleatorio simple
Seleccione una muestra aleatoria simple de 10 individuos.
En Excel: ALEATORIO() y ALEATORIO.ENTRE(inferior, superior).
En R: sample(x, size, replace = FALSE, prob = NULL).
8.2.1.2 Otros tipos de muestreo
Muestreo estratificado: En este caso los individuos de la población se pueden dividir en grupos (homogéneos en su interior y heterogéneos entre ellos) y se desea que en la muestra se tenga una representación adecuada de cada uno de estos grupos. Es así que se toma una muestra aleatoria simple de individuos de cada grupo, de tal manera que en la muestra se conserve la proporción de los tamaños de los grupos.
Muestreo por conglomerados: En este caso los individuos de la población están divididos en segmentos que no necesariamente son homogéneos, cada segmento es una buena representación en menor escala del comportamiento de toda la población y por lo tanto no es necesario tomar individuos de todos los segmentos. Es así que se toma una muestra aleatoria simple de los segmentos y luego para cada segmento seleccionado se toma una muestra aleatoria simple de individuos.
Muestreo sistemático: En este caso, los elementos de la población son seleccionados de manera sistemática a través de la población. La idea es tomar aleatoriamente un individuo por cada cierto número de individuos, es decir, tomo aleatoriamente un individuo de los primeros k, luego uno de los siguientes k y así sucesivamente.
8.2.2 Conceptos básicos
Utilicemos el siguiente ejercicio para imaginar todas las situaciones en las que NO tendremos datos poblacionales sino únicamente datos muestrales.
En un estudio de USA Today/CNN/Gallup realizado con 369 padres que trabajan, se encontró que 200 consideran que pasan muy poco tiempo con sus hijos debido a sus compromisos laborales (supongan que también les preguntan el tiempo al día que pasan con sus hijos, entre otras preguntas).
¿Cuál sería la población en esta situación?
¿Cuáles serían las variables?
¿Cuál sería la distribución de cada variable?
¿Cuál sería el parámetro o los parámetros de la distribución de cada variable?
Adaptado de: Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Capítulo 8. Ejercicio 54.
Estadístico: Cualquier cálculo o cómputo (fórmula) a partir de la muestra. Función de la muestra.
Estimador: Estadístico que es usado para estimar un parámetro de una población.
Estimación: Valor que toma un estimador a partir de los datos de la muestra.
En un estudio de USA Today/CNN/Gallup realizado con 369 padres que trabajan, se encontró que 200 consideran que pasan muy poco tiempo con sus hijos debido a sus compromisos laborales (supongan que también les preguntan el tiempo al día que pasan con sus hijos, entre otras preguntas).
¿Cuál sería una buena fórmula a utilizar para estimar el o los parámetros de la distribución de cada variable?
Suponga que todos tomamos una muestra, ¿todos obtenemos las mismas estimaciones?
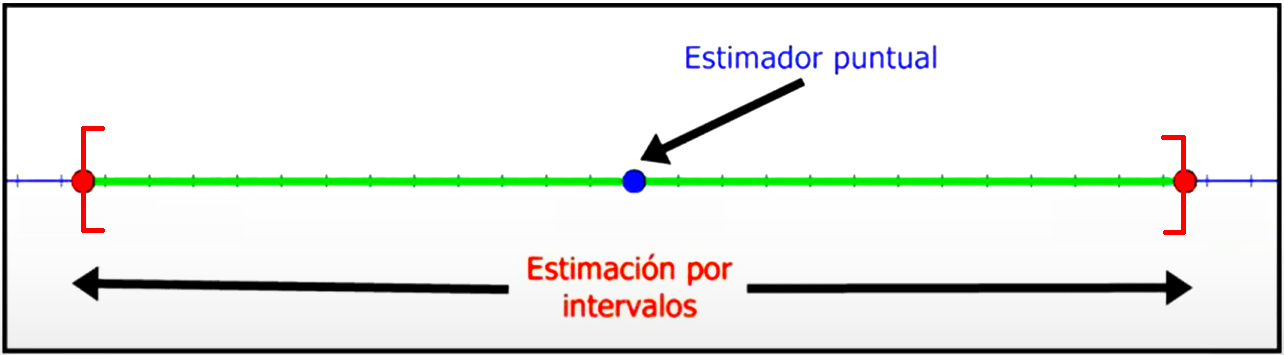
8.2.3 Estimación puntual
8.2.3.1 Métodos para encontrar estimadores
Existen varios métodos para encontrar estimadores, como el método de momentos (solución de sistema de ecuaciones), el de máxima verosimilitud o el de mínimos cuadrados (problemas de optimización), entre otros.
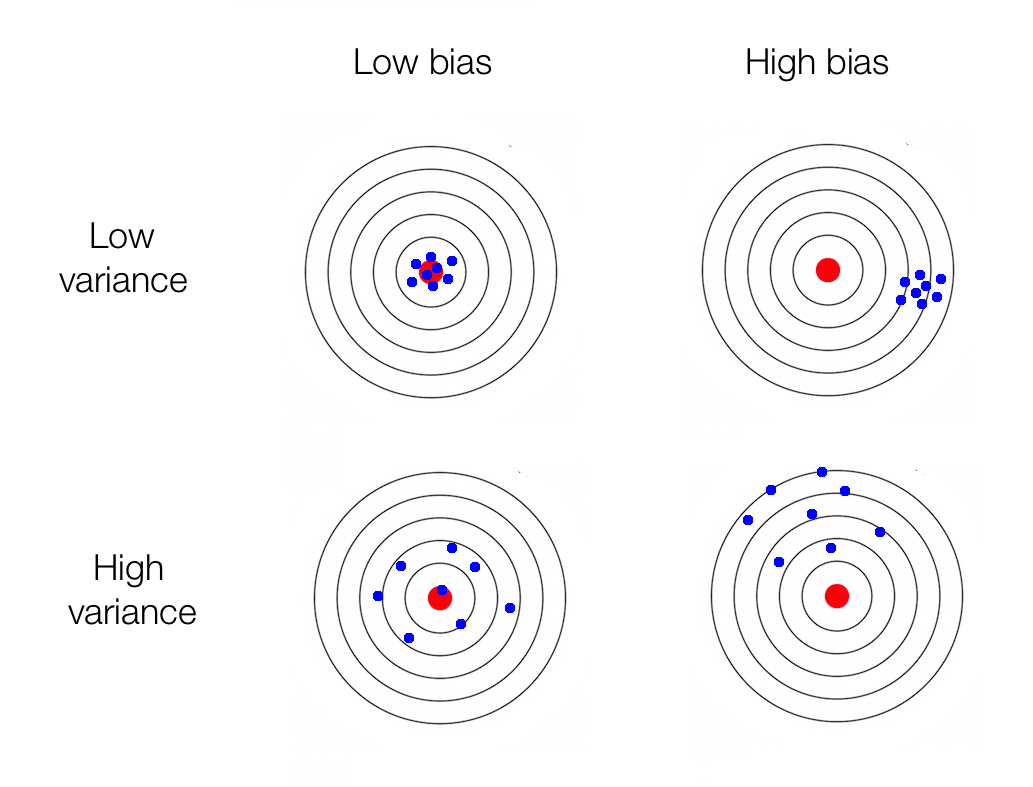
8.2.3.2 Calidad de los estimadores
Queremos estimadores ojalá insesgados y de mínima varianza
Para el parámetro proporción \left(\theta = p\right) de una población con una distribución Bernoulli, se sabe que el mejor estimador es la proporción muestral \left(T = \hat{P}\right).
Para el parámetro media \left(\theta = \mu\right) de una población con una distribución normal (con varianza conocida), se sabe que el mejor estimador es la media muestral media muestral \left(T = \bar{X}\right).
Para el parámetro varianza \left(\theta = \sigma^2\right) de una población con una distribución normal, se sabe que la misma fórmula poblacional pero con los datos muestrales (dividiendo por la cantidad de datos n) es sesgada, mientras que si divido por n-1 entonces es insesgada y es la denominada varianza muestral\left(T = S^2 = \frac{1}{n-1} \sum_{i=1}^{n} \left(X_i - \bar{X}\right)^2\right)
8.2.3.3 Error Estándar
El error estándar de un estimador es su desviación estándar.
El error estándar estimado de la proporción muestral sería \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}.
El error estándar de la media muestral (suponiendo que la varianza poblacional es conocida) sería \frac{\sigma}{\sqrt{n}}.
8.2.3.4 Error cuadrático medio
El error cuadrático medio de un estimador es su varianza más el cuadrado de su sesgo (también es el promedio / valor esperado de las distancias al cuadrado entre el estimador y el parámetro).
\begin{aligned}
MSE[T] &= E\left[ \left( T - \theta \right)^2 \right] = Var\left[ T \right] + SESGO[T]^2
\end{aligned}
En un estudio de USA Today/CNN/Gallup realizado con 369 padres que trabajan, se encontró que 200 consideran que pasan muy poco tiempo con sus hijos debido a sus compromisos laborales.
Proporcione una estimación puntual de la proporción poblacional de padres que trabajan y piensan que pasan muy poco tiempo con sus hijos debido a sus compromisos laborales.
¿Cuál es el error estándar de la estimación puntual anterior?
Tomado de: Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Capítulo 8. Ejercicio 54.
8.2.4 Intervalos de confianza
¿Cuál es el intervalo de confianza de 95\% para la proporción poblacional de padres que trabajan y piensan que pasan muy poco tiempo con sus hijos debido a sus compromisos ocupacionales?
Para un tamaño de muestra (n) suficientemente grande (np > 10 y n(1-p) > 10), un intervalo de confianza para la proporción poblacional (p) podría ser: \left( \hat{p} - \left( z \left[ \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \right] \right) \; , \; \hat{p} + \left( z \left[\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\right] \right) \right)
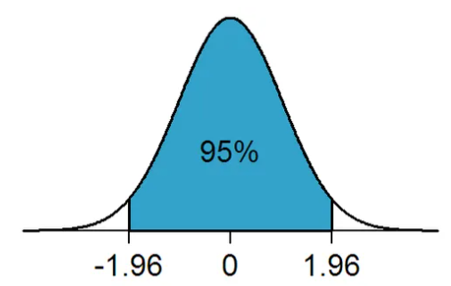
de tal manera que entre -z y z está un porcentaje central dado de la distribución normal estándar. Para encontrar z use INV.NORM.ESTAND(probabilidad), en Excel, o qnorm(p), en R.
En general:
El intervalo \left(T_1, T_2 \right) es llamado intervalo de confianza del 100(1-\alpha)\% y se tiene que P\left[ T_1 < \theta < T_2 \right] = 1 - \alpha
1-\alpha es el grado de confianza.
T_1 es el límite de confianza inferior.
T_2 es el límite de confianza superior.
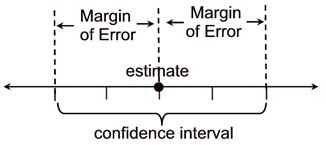
8.2.4.1 Margen de error
¿Cuál es el margen de error para 95\% de confianza?
\left( \hat{p} - \underbrace{ \left( z \left[ \sqrt{\tfrac{\hat{p}(1-\hat{p})}{n}} \right] \right) }_\text{margen de error} \; , \; \hat{p} + \underbrace{ \left( z \left[ \sqrt{\tfrac{\hat{p}(1-\hat{p})}{n}} \right] \right) }_\text{margen de error} \right)
8.2.4.2 Tamaño de muestra
Una firma de tarjetas de crédito de un conocido banco desea estimar la proporción de tarjetahabientes que al final del mes tienen un saldo distinto de cero que ocasiona cargos. Suponga que el margen de error deseado es 0.03 con 98\% de confianza.
¿De qué tamaño deberá tomarse la muestra si se cree que 70\% de los tarjetahabientes de la firma tienen un saldo distinto de cero al final del mes?
¿De qué tamaño deberá tomarse la muestra si no se puede especificar ningún valor planeado para la proporción?
Tomado de: Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Capítulo 8. Ejercicio 58.
Se tiene un 100(1-\alpha)\% de confianza de que el error no va a exceder un valor fijo dado e, cuando el tamaño de muestra es: n \geq \left( \frac{z \, \sqrt{p^*(1-p^*)}}{e} \right)^2 = \frac{z^2 \, p^*(1-p^*)}{e^2}
Así como se puede obtener un intervalo de confianza para la proporción poblacional, con frecuencia se suelen obtener intervalos de confianza para:
la media poblacional.
la varianza (o la desviación estándar) poblacional.
la diferencia entre las proporciones de dos poblaciones.
la diferencia entre las medias de dos poblaciones.
el cociente entre las varianzas (a las desviaciones estándar) de dos poblaciones.
El archivo “ResumenFormulasInferencia.pdf”, intenta resumir las fórmulas básicas para inferencia de los anteriores escenarios.
Por ejemplo, para la diferencia de proporciones de dos poblaciones:
En una encuesta una de las preguntas era: ¿Piensa usted que en los próximos 12 meses aumentará en su empresa el número de empleados de tiempo completo? En la encuesta actual, 220 de 400 ejecutivos respondieron Sí, mientras que en la realizada el año anterior, 192 de 400 respondieron en el mismo sentido.
Calcule la proporción muestral de los que respondieron Sí en la encuesta actual y la proporción de los que respondieron Sí en la encuesta anterior. ¿Cuál es la estimación puntual de la diferencia entre las proporciones de las dos poblaciones? ¿Qué indica tal estimación? ¿Cuál es el error estándar de dicha estimación puntual?
Encuentre el margen de error y un intervalo de 90% de confianza para estimar la diferencia entre las proporciones en estas dos encuestas. ¿Cuál es su interpretación de la estimación por intervalo?
Adaptado de: Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Capítulo 10. Ejercicio 30.
La siguiente fórmula me sirve para resolver el anterior ejercicio:
Una prueba de hipótesis es un procedimiento estadístico que se usa para tomar una decisión, con respecto a una conjetura acerca de la población, a partir de la evidencia que se tiene en la muestra (es decir, a partir de la información que nos da la muestra).
Tengamos en cuenta la siguiente situación:
En una planta de producción, los recipientes deben quedar llenos con 16 onzas de producto. No está bien que se llenen de más ni de menos: a veces se desperdicia producto, otras veces los paquetes no cumplen con lo que se promete al cliente. Para evitar que eso ocurra, se revisa el sistema de llenado cada hora. Lo que se hace es tomar una muestra de 30 recipientes y revisar si el contenido sigue siendo cercano a 16 onzas, como debe ser. Si se aleja de 16, se interpreta como señal de que el sistema se desajustó y el operario debe parar la línea de producción para hacer la corrección. Se trabaja con un nivel de significancia de \alpha = 0.05 y se sabe, por datos históricos, que la desviación estándar del proceso es de 0.8 onzas.
Establezca la prueba de hipótesis para esta aplicación al control de calidad.
Adaptado de: Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Capítulo 9. Ejercicio 60.
8.2.5.1 Hipótesis nula H_0 e hipótesis alternativa H_a
Suponga que se está en un juicio. Bajo la idea de que un acusado es inocente hasta que se demuestre lo contrario (el jurado debe encontrarlo culpable “más allá de la duda razonable”), entonces,
\begin{aligned}
H_0 &: \text{ El acusado es inocente} \\
H_a &: \text{ El acusado es culpable}
\end{aligned}
La evidencia tiene que ser suficiente para condenar al acusado (rechazar H_0). En caso contrario, se dice que no hay suficiente evidencia para declararlo culpable (no se rechaza H_0).
8.2.5.2 Tipo de error
\,
H_0 es verdadera
H_a es verdadera
Se rechaza H_0
Error Tipo I
\checkmark
No se rechaza H_0
\checkmark
Error Tipo II
Sea
\alpha = P[\text{ Error Tipo I }]
y
\beta = P[\text{ Error Tipo II }]
entonces \alpha se denomina el nivel de significancia y 1 - \beta la potencia de la prueba (que se usa para rechazar o no rechazar la hipótesis nula).
¿es posible que \alpha y \beta sean simultáneamente tan pequeños como uno quiera?
8.2.5.3 Sistemas de hipótesis
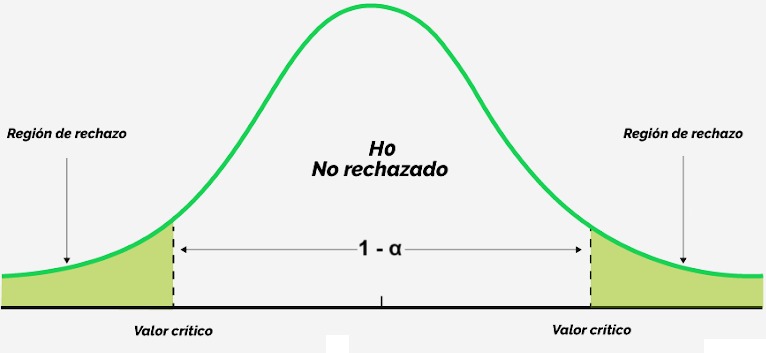
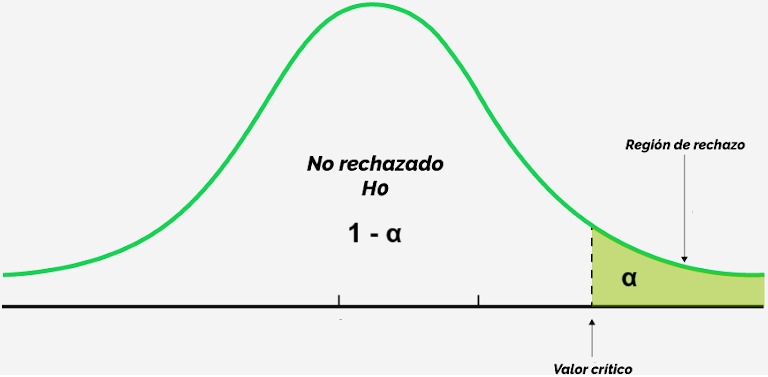
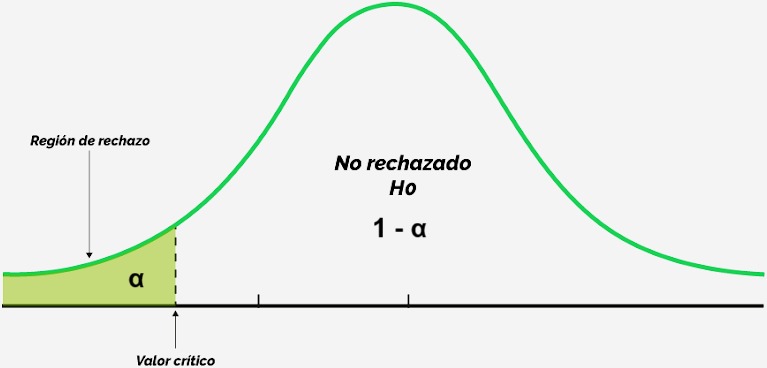
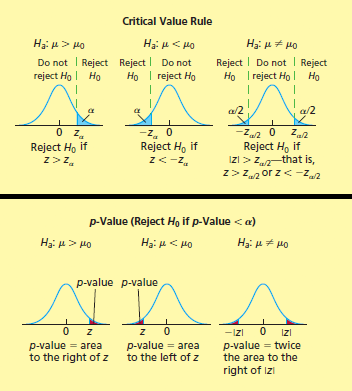
El parámetro de interés es igual a cierto número versus es diferente a dicho número (prueba a dos colas):
Determine la hipótesis nula H_0 y la hipótesis alternativa H_a (sistema de hipótesis).
Seleccione el estadístico de prueba apropiado y calcule el valor que tomaría a partir de los datos muestrales.
3a. (Alternativa 1) Usando el o los valores críticos:
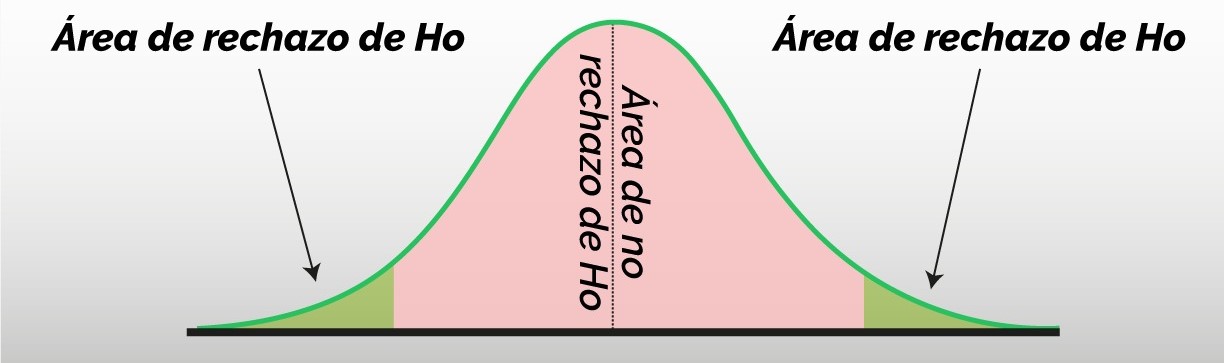
Determine el o los valores críticos y la regla de rechazo a partir de la distribución muestral del estadístico de prueba.
Si el valor del estadístico de prueba está en la zona de rechazo entonces rechace H_0, en caso contrario no rechace H_0.
3b. (Alternativa 2) Usando el p-valor:
Calcule el p-valor correspondiente al valor del estadístico de prueba a partir de su distribución muestral.
Si el p-valor es menor que \alpha entonces rechace H_0, en caso contrario no rechace H_0.
Existen múltiples pruebas de hipótesis. Para cada parámetro de interés debe haber al menos una prueba disponible. Además, según los supuestos adoptados sobre el problema y las consideraciones estadísticas que se tengan en cuenta, pueden existir varias pruebas distintas para un mismo parámetro.
El archivo “ResumenFormulasInferencia.pdf” intenta resumir las fórmulas básicas para inferencia, incluyendo las de algunas pruebas de hipótesis.
En una planta de producción, los recipientes deben quedar llenos con 16 onzas de producto. No está bien que se llenen de más ni de menos: a veces se desperdicia producto, otras veces los paquetes no cumplen con lo que se promete al cliente. Para evitar que eso ocurra, se revisa el sistema de llenado cada hora. Lo que se hace es tomar una muestra de 30 recipientes y revisar si el contenido sigue siendo cercano a 16 onzas, como debe ser. Si se aleja de 16, se interpreta como señal de que el sistema se desajustó y el operario debe parar la línea de producción para hacer la corrección. Se trabaja con un nivel de significancia de \alpha = 0.05 y se sabe, por datos históricos, que la desviación estándar del proceso es de 0.8 onzas.
Plantee la prueba de hipótesis que permita decidir si es necesario detener la producción.
Si en una cierta hora el promedio de la muestra resulta ser 16.32 onzas, ¿cuál es el valor-p?, ¿qué acción se debería tomar con base en ese resultado? (y para 15.82 onzas)
Si se desea hacer un juzgamiento (prueba de hipótesis) acerca de la media de una población, es decir, en el caso en el cual el parámetro de interés \theta es la media \mu(H_0: \mu = \mu_0)
Si \sigma es conocida, entonces, para n suficientemente grande o bajo el supuesto de que la variable de interés de la población tiene distribución normal, el valor del estadístico de prueba está dado por, \frac{\bar{x} - \mu_0}{\sigma/\sqrt{n}} y la distribución muestral es \mathcal{N}(0,1)
8.2.5.5 Relación entre pruebas de hipótesis e intervalos de confianza
En general, la región de “no rechazo” es equivalente a un intervalo de confianza del parámetro de interés. Mediante una transformación adecuada puedo pasar de un intervalo de confianza a una región de rechazo, y viceversa.
Una prueba de hipótesis a dos colas (H_a: \theta \neq \theta_0) con un nivel de significancia \alpha es equivalente a calcular un intervalo de confianza bilateral del 100(1-\alpha)\% para \theta y rechazar H_0 si \theta_0 está por fuera del intervalo.
Listado de funciones dentro del paquete stats que dentro de su nombre incluyen la palabra “test”:
ls("package:stats", pattern = "test")
Ejercicio:
En una universidad se quiso averiguar si los estudiantes que asisten con frecuencia a las tutorías de una asignatura realmente obtienen mejores notas que quienes no asisten. Para ello, se utilizarán los resultados de dos muestras: una de 40 estudiantes que fueron a tutorías, con un promedio de nota de 3.95 y una desviación estándar de 0.22072, y otra de 50 estudiantes que no fueron, con un promedio de 3.4 y desviación estándar de 0.2. Con base en estos datos muestrales, se quiere saber si se podría afirmar que poblacionalmente la diferencia efectivamente superaría, en promedio, los 0.5 puntos en favor de quienes asisten a tutorías. Utilice un nivel de significancia de 0.05 y verifique si puede suponerse que las dos poblaciones tienen la misma variabilidad en las notas.
En otras palabras:
Se quiere saber si los estudiantes que asisten regularmente a tutorías obtienen notas al menos medio punto más altas que quienes no lo hacen. ¿La asistencia a tutorías incrementa significativamente el promedio de calificaciones en más de 0.5 puntos respecto a los estudiantes que no asisten?
Se desea determinar si existe evidencia estadísticamente significativa de que el promedio poblacional de las calificaciones de los estudiantes que asisten a tutorías supera en más de 0.5 puntos al de quienes no asisten. ¿Existe una diferencia estadísticamente significativa superior a 0.5 puntos en el rendimiento promedio entre estudiantes asistentes y no asistentes a tutorías?
8.2.6 Ampliar o complementar
El contenido de esta subsección se puede ampliar o complementar con lo que se encuentra en las siguientes páginas:
Probabilidad y Estadística Fundamental (PyEF), Secciones 9 a 13 (Inferencia):