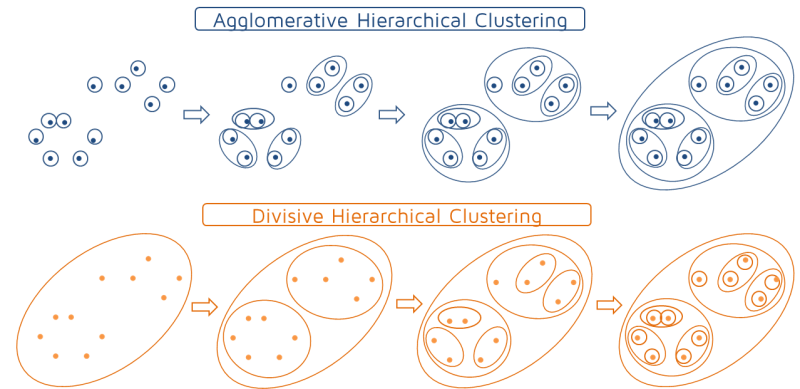
Fundamentos aplicados de aprendizaje no supervisado básico
En aprendizaje no supervisado, NO hay variable(s) “privilegiada(s)” de especial interés, es decir variable(s) respuesta / target a estimar o predecir, eso corresponde al modelado matemático-estadístico y al aprendizaje supervisado.
El aprendizaje no supervisado abarca diversas tareas centrales, entre las que destacan:
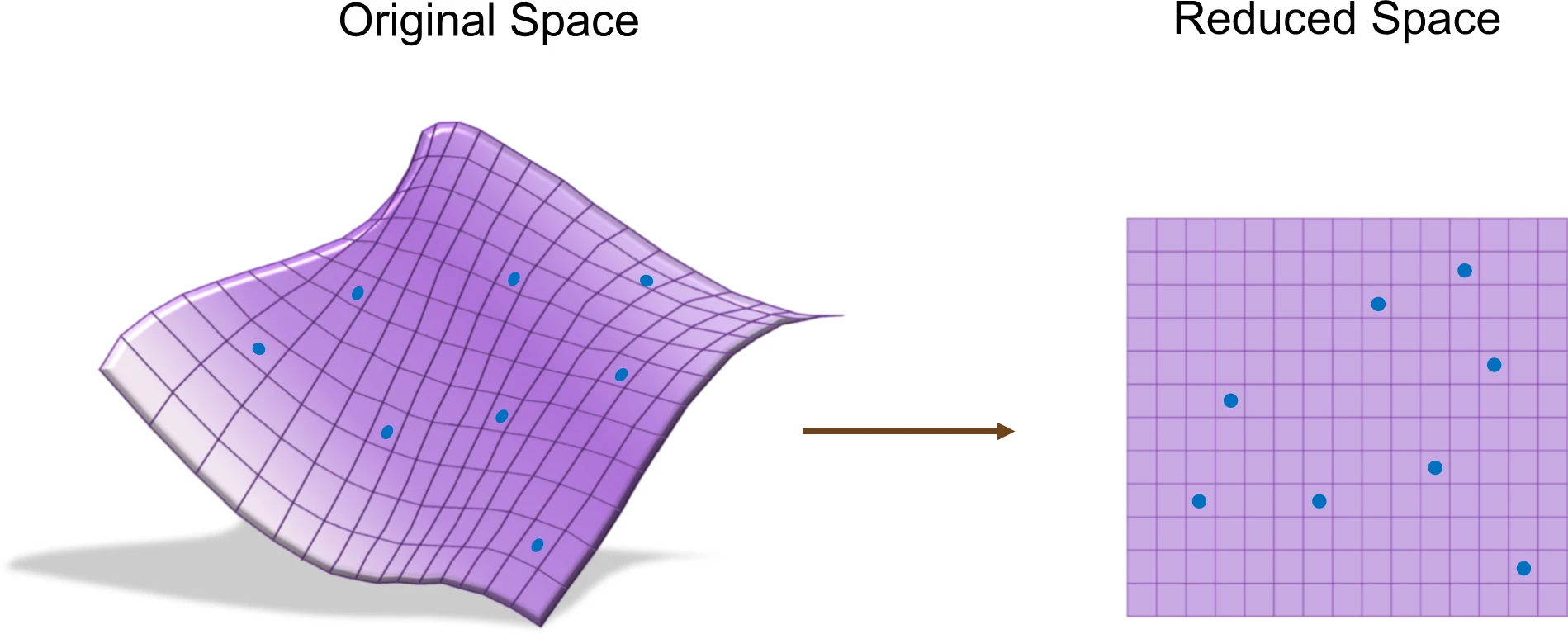
Reducción de dimensionalidad: busca transformar los datos a un espacio de menor dimensión, conservando la información relevante y eliminando el ruido o la redundancia. Esto facilita la visualización y el procesamiento de datos complejos.
Agrupamiento (clustering): tiene como objetivo particionar el conjunto de datos en grupos o clusters, de modo que las observaciones dentro de un mismo grupo sean más similares entre sí que respecto a las de otros grupos.
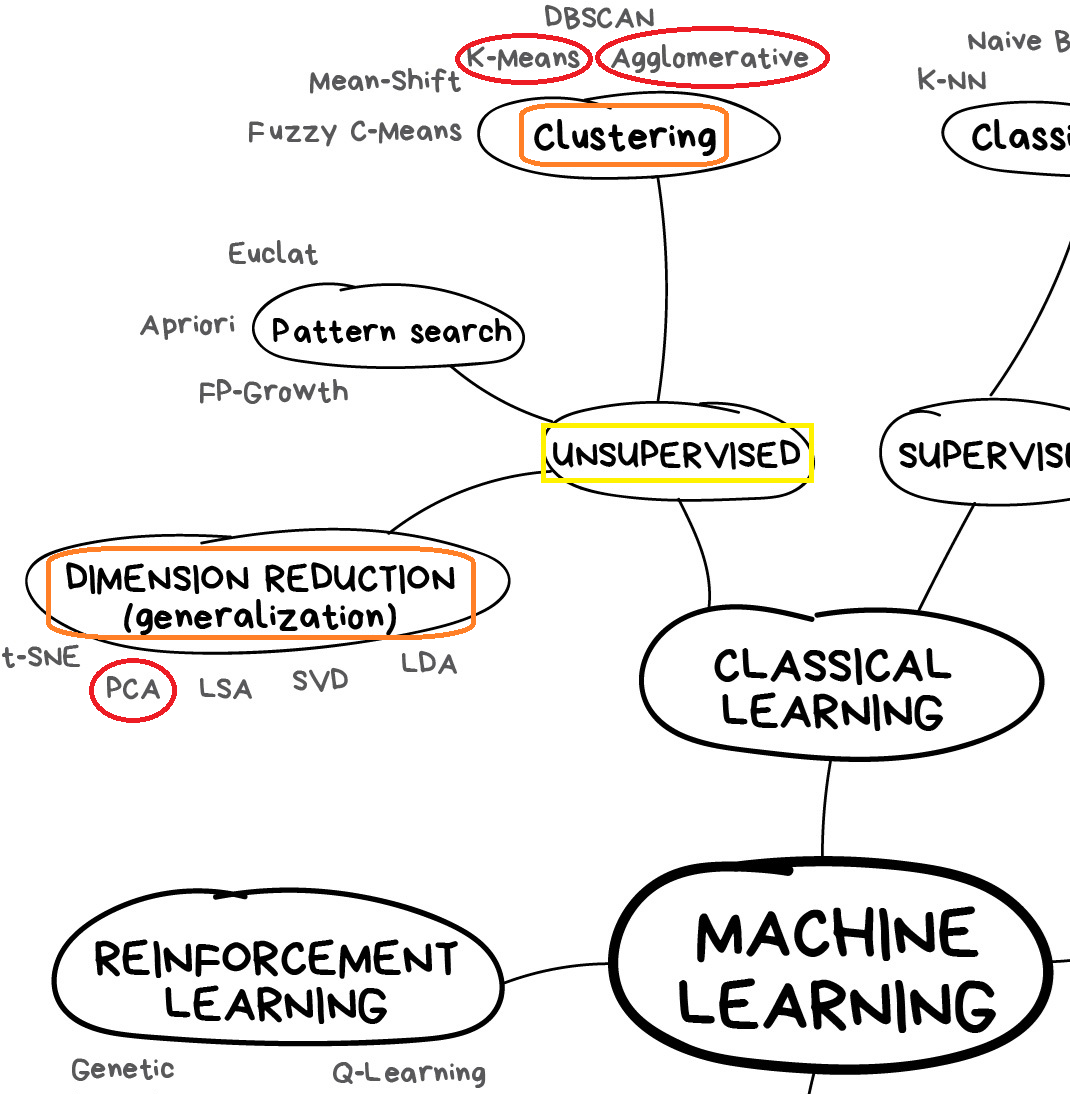
Extracto de: Un mapa acerca del aprendizaje automático (machine learning map). Tomado de: https://vas3k.com/blog/machine_learning
Un desafío importante del aprendizaje no supervisado es la interpretación de los resultados, ya que no existe una “respuesta o resultado correcto” (una variable respuesta / target) contra la cual validar los modelos.
Las técnicas de visualización y el análisis exploratorio resultan esenciales para interpretar los patrones descubiertos y evaluar la calidad de los modelos.
7.1 Herramientas computacionales
Para este módulo se trabajará principalmente con R como software estadístico, es decir como herramienta de cálculo y análisis de datos.
Además de utilizar los elementos de la instalación base de R, se trabajará principalmente con dos paquetes (incluyendo todas sus dependencias):
FactoClass para la aplicación de métodos factoriales y de agrupamiento (clustering).
plotly para la producción de algunos gráficos dinámicos.
Adicionalmente, en la medida de que sea posible se explorará el uso de otros paquetes alternativos o complementarios, como por ejemplo Factoshiny y factoextra.
Código a ejecutar para empezar (de clic en donde en dice “Code”, para desplegar el código, y luego copie y pegue en una sesión abierta de R):
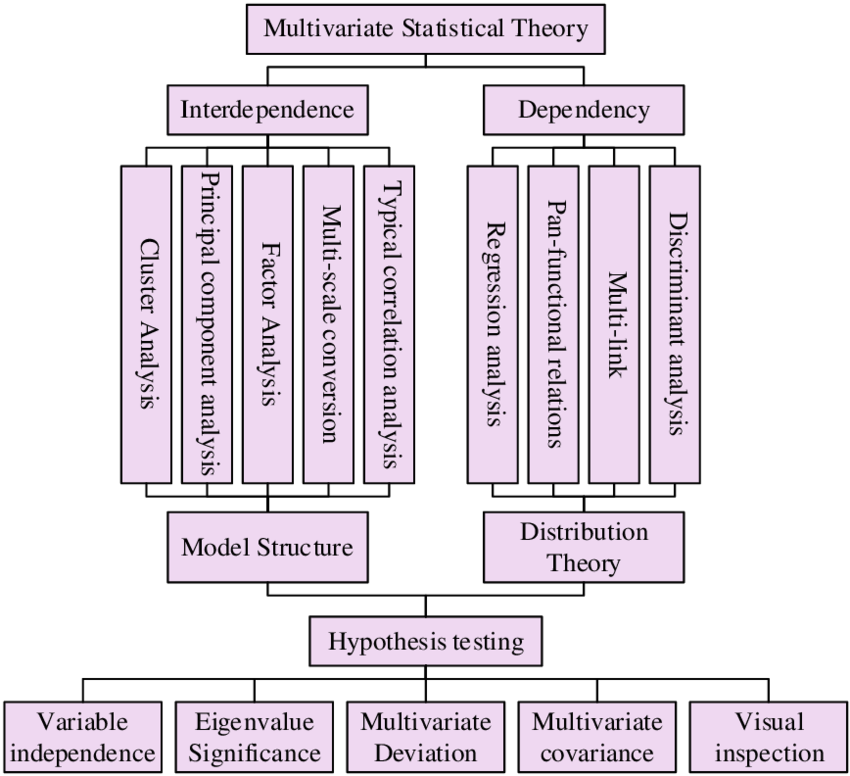
La estadística multivariada se enfoca en el análisis simultáneo de múltiples variables.
Tomado de: https://doi.org/10.2478/amns.2023.2.00849
7.2.1 Estadística Descriptiva Multivariada
La teoría, la práctica, las técnicas y los métodos de la estadística descriptiva multivariada (EDM) pueden considerarse como elementos fundamentales del aprendizaje no supervisado.
La Estadística Descriptiva Multivariada proporciona herramientas para explorar, entender y simplificar los datos antes de aplicar métodos más complejos.
Los métodos descriptivos y exploratorios multivariados pretenden encontrar significado en grandes tablas de datos.
A través de técnicas derivadas del análisis de componentes principales generalizado se facilita la comprensión de las estructuras subyacentes, permitiendo identificar patrones y relaciones que podrían pasar inadvertidos en espacios de alta dimensionalidad.
Este enfoque es fundamental en ciencia de datos, donde los conjuntos de datos suelen ser complejos y multivariantes, y la reducción de la dimensión contribuye a lidiar con la “maldición de la dimensión” (curse of dimensionality), mejorar la eficiencia computacional y la interpretación de los modelos.
“En matemáticas y estadística, la maldición de la dimensión, también conocida como efecto Hughes, se refiere a los diversos fenómenos que surgen al analizar y organizar datos de espacios de cientos y miles de dimensiones que no suceden en el espacio físico descrito generalmente con solo tres dimensiones.”
Además, la estadística descriptiva multivariada no solo se aplica a la reducción de la dimensión, sino que también integra el “análisis de agrupamiento” (cluster analysis), que permite identificar y caracterizar grupos dentro de los datos.
Métodos como k-means y el agrupamiento jerárquico aglomerativo de Ward, al combinarse, ofrecen una base sólida para segmentar los datos y descubrir estructuras ocultas, lo cual resulta clave tanto en la ciencia de datos como en el aprendizaje automático.
La estadística descriptiva multivariada es esencial en áreas como exploratory data analysis (EDA), data mining, pattern recognition, knowledge discovery y el aprendizaje no supervisado, porque permite analizar y resumir la interrelación entre múltiples variables de forma simultánea.
Su importancia radica en que facilita la comprensión de la estructura y las dependencias de los datos, proporcionando una visión general que ayuda a identificar patrones, detectar anomalías y descubrir relaciones ocultas.
En todos estos campos, la estadística descriptiva multivariada ofrece un marco inicial sólido para la aplicación de técnicas más avanzadas de modelado o análisis.
“Las descripciones multivariadas que recurren a las gráficas para comprender los datos son mucho más difíciles que las univariadas, porque su interpretación correcta depende del conocimiento de los procedimientos y conceptos para su construcción. Los usuarios de diferentes áreas del conocimiento necesitan al menos una comprensión intuitiva de la lógica de los métodos con el fin de lograr la interpretación correcta de las salidas gráficas y de los índices numéricos que las acompañan. Los científicos y profesionales responsables de la metodología estadística deben conocer los fundamentos de la geometría multidimensional, basados en los conceptos del álgebra lineal que tienen que ver con espacios vectoriales en los reales con producto interno.”
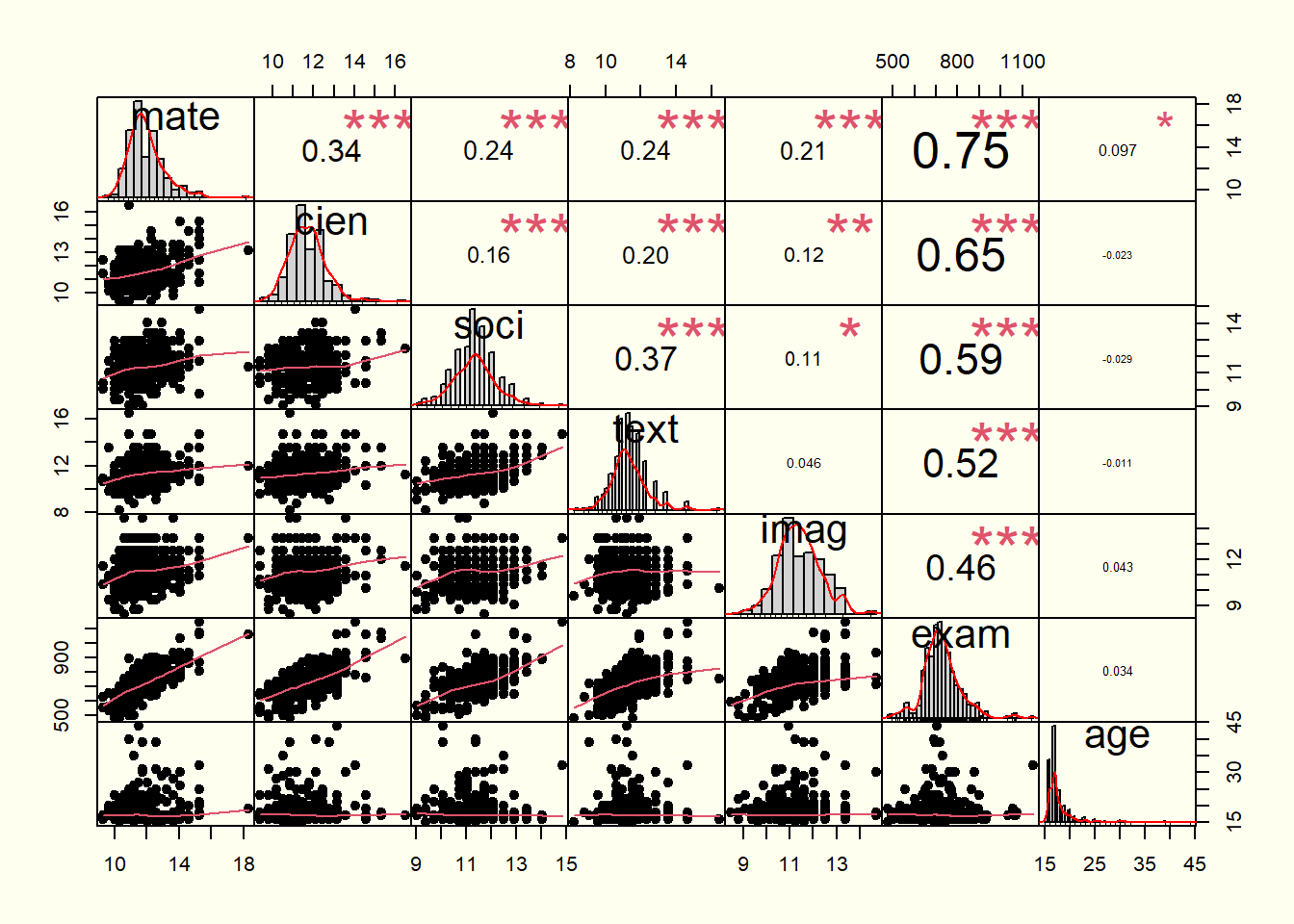
Tomando solamente algunas de las variables cuantitativas de los datos de admitidos, la situación planteada es una de las más sencillas y más pequeñas que uno se puede encontrar.
Código
# Si no está cargado, cargar paquete FactoClassif(!require(FactoClass)){install.packages("FactoClass"); library(FactoClass)}data(admi)# cargar admitidos de FactoClass
Sin embargo, ¿qué problemas imaginas que surgen al querer analizar 10, 50, 100 o más variables simultáneamente?
7.3 Dimensión
7.3.1 ¿Dimensión?
Empecemos preguntándonos sobre el concepto mismo de dimensión.
Discusión: ¿qué nos dice nuestra intuición? ¿cuántas dimensiones cree que tienen los siguientes objetos?
¿y en estos casos?
Existen: dimensión de un espacio vectorial, dimensión topológica, dimensión de Krull, dimensiones fractales (p.ej. la dimensión de Hausdorff), etc.
¿y la dimensión de nuestros datos?
Ejemplo / Caso 1:
Ejemplo / Caso 2:
En ambos casos tenemos un conjunto de datos con tres variables (tres dimensiones). Sin embargo, si se “miran adecuadamente”, puede que los datos “vivan” o queden “bien representados” en una dimensión menor.
¿Y si tenemos muchas más de tres variables?
7.3.2 Maldición de la dimensión
La maldición de la dimensión (Curse of Dimensionality) hace referencia a los problemas que surgen cuando se trabaja con datos en espacios de alta dimensionalidad.
Este fenómeno es especialmente relevante en áreas como el aprendizaje automático, el análisis numérico, el muestreo, la combinatoria, la minería de datos y las bases de datos.
A medida que se agregan más variables a un conjunto de datos, el número de dimensiones del espacio en el que estos se representan aumenta (a medida que tenemos más variables, tenemos más dimensiones, por ejemplo, 50, 100, 1000, etc.).
Con el incremento de las dimensiones, los volúmenes / hipervolúmenes del espacio crecen de manera exponencial.
Esto provoca que los datos se distribuyan de forma mucho más dispersa.
La consecuencia principal de esta dispersión es que los métodos que requieren significación estadística se vuelven menos efectivos, ya que la densidad de los datos disminuye considerablemente.
Para obtener resultados estadísticamente sólidos, la cantidad de datos necesarios también debería aumentar de forma exponencial en relación con el número de dimensiones.
Muchas técnicas se basan en identificar áreas donde los objetos presentan propiedades similares, se encuentran relativamente cerca y se pueden agrupar.
Sin embargo, en espacios de alta dimensionalidad, los objetos tienden a estar tan dispersos que parecen únicos en muchos aspectos, lo que dificulta la aplicación de estrategias convencionales de manera efectiva y eficiente.
En resumen,
Complicaciones:
Desafíos en la visualización
Alto costo computacional
Datos escasos y dispersos
Las distancias pierden significado
Algoritmos se degradan
Modelos reducen su capacidad de generalizar
7.3.3 Reducción de la dimensión
La principal solución a la maldición de la dimensión es la reducción de la dimensión.
Tomado de: https://doi.org/10.1038/s41524-020-0276-y
Al reducir la dimensión, podemos conservar la información más importante en los datos mientras descartamos las características redundantes o menos importantes.
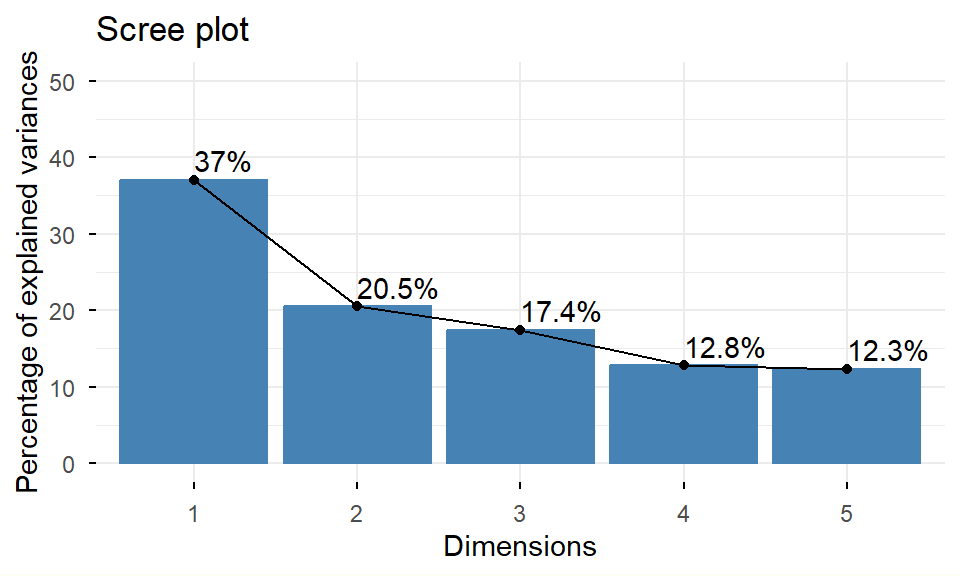
7.4 Análisis de componentes principales (ACP)
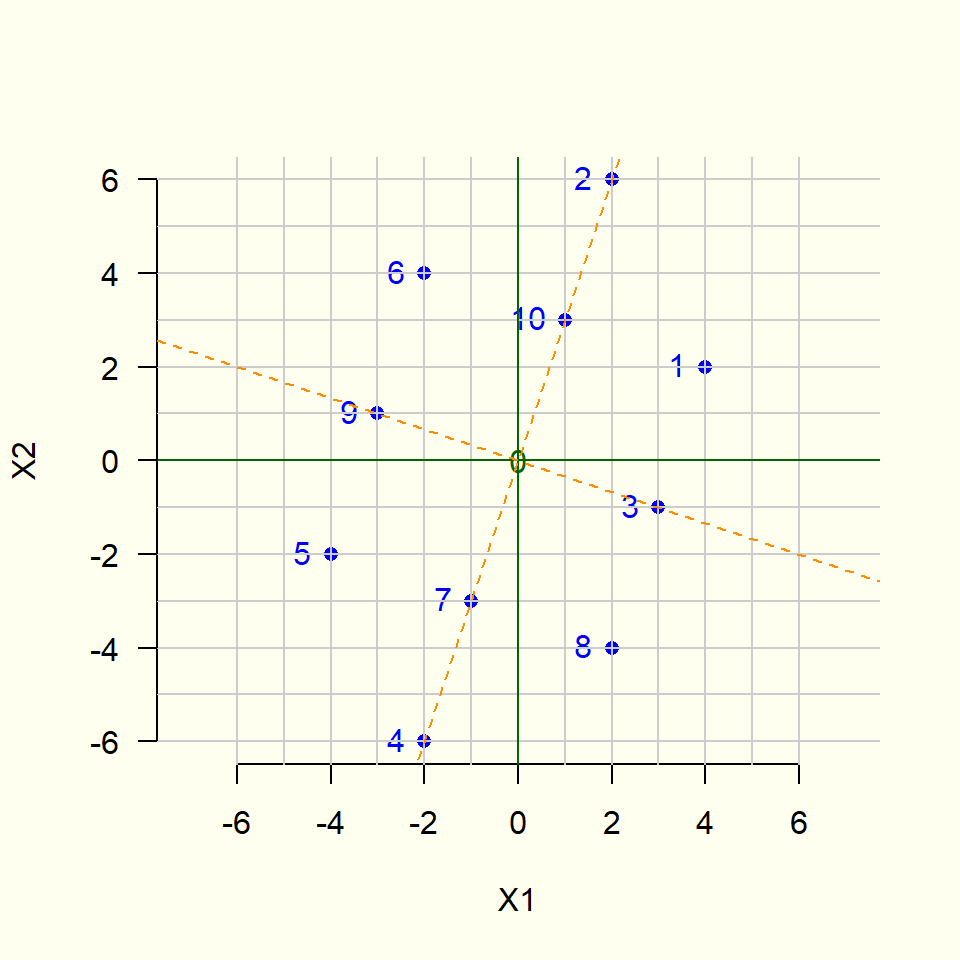
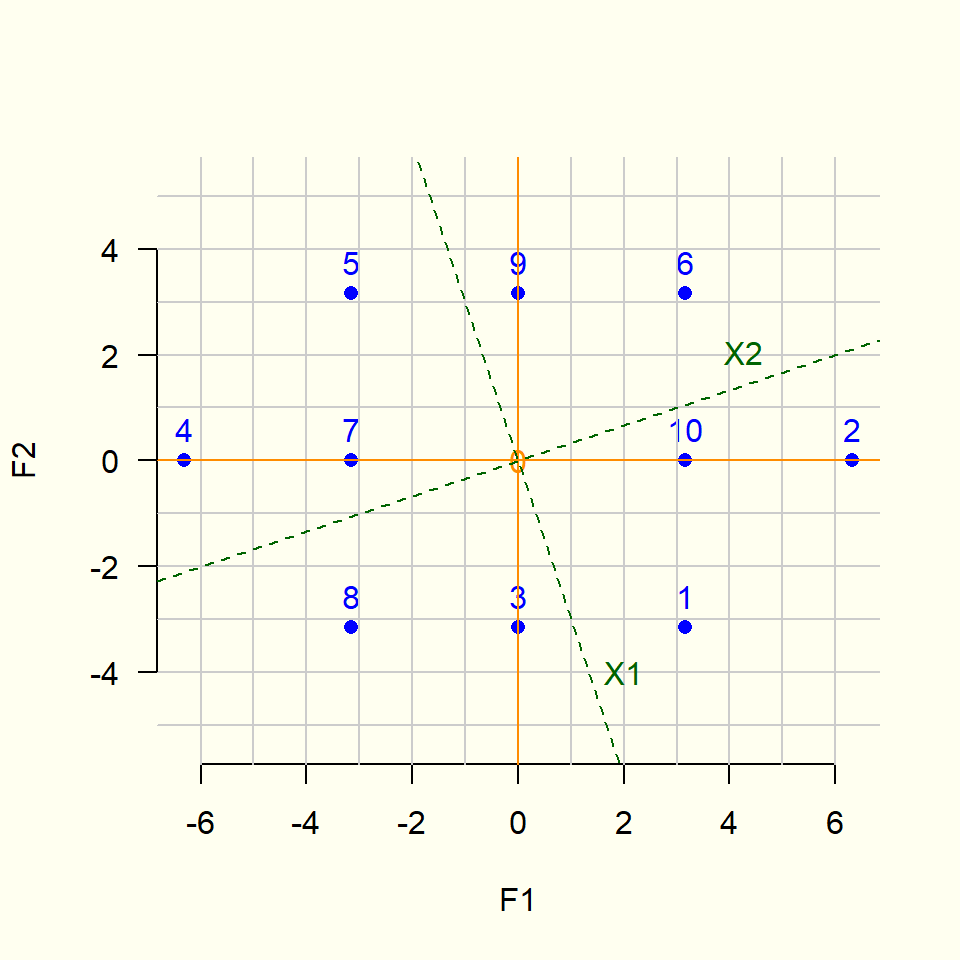
El análisis de componentes principales (ACP) es un procedimiento estadístico que utiliza una transformación para convertir un conjunto de observaciones de variables numéricas posiblemente correlacionadas en un conjunto de valores de variables no correlacionadas linealmente llamadas componentes principales.
Las componentes principales son una suma ponderada (una combinación lineal) de las variables originales.
El ACP permite reducir la dimensión (de manera lineal), describir relaciones lineales entre variables y comparar individuos a partir de la distancia entre ellos.
Esta transformación se define de tal manera que el primer componente principal tiene la mayor variabilidad posible, es decir, representa la mayor cantidad posible de variabilidad en los datos).
Cada componente subsiguiente, a su vez, tiene la mayor variabilidad posible bajo la restricción de ser perpendicular (ortogonal) a las componentes anteriores.
A continuación se muestra un ejemplo o ilustración (sobresimplificada) de la transformación correspondiente al análisis de componentes principales:
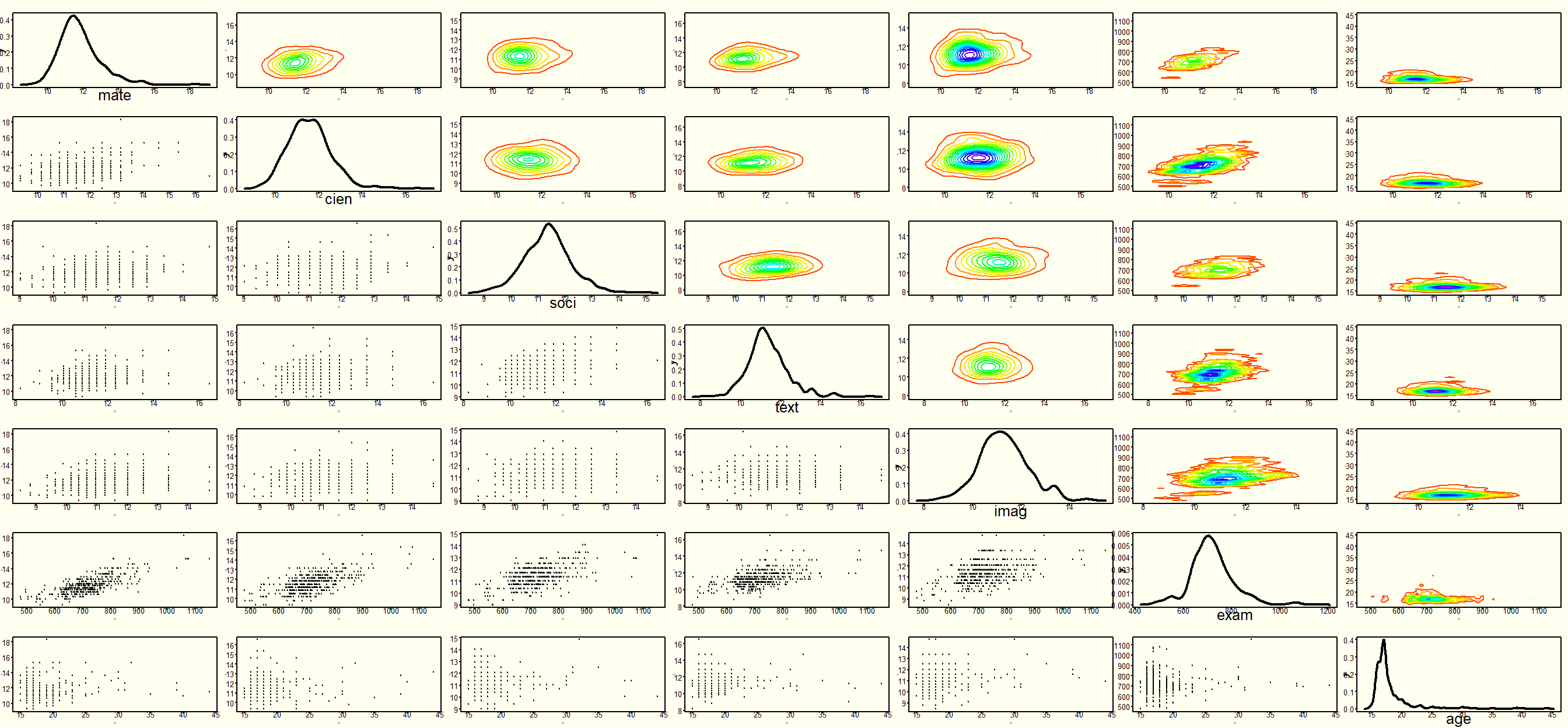
# Si no está cargado, cargar paquete FactoClass:if(!require(FactoClass)){install.packages("FactoClass"); library(FactoClass)}data(admi)# cargar admitidos de FactoClassY<-admi[, c(2:6,7,15)]plotpairs(Y, 7)
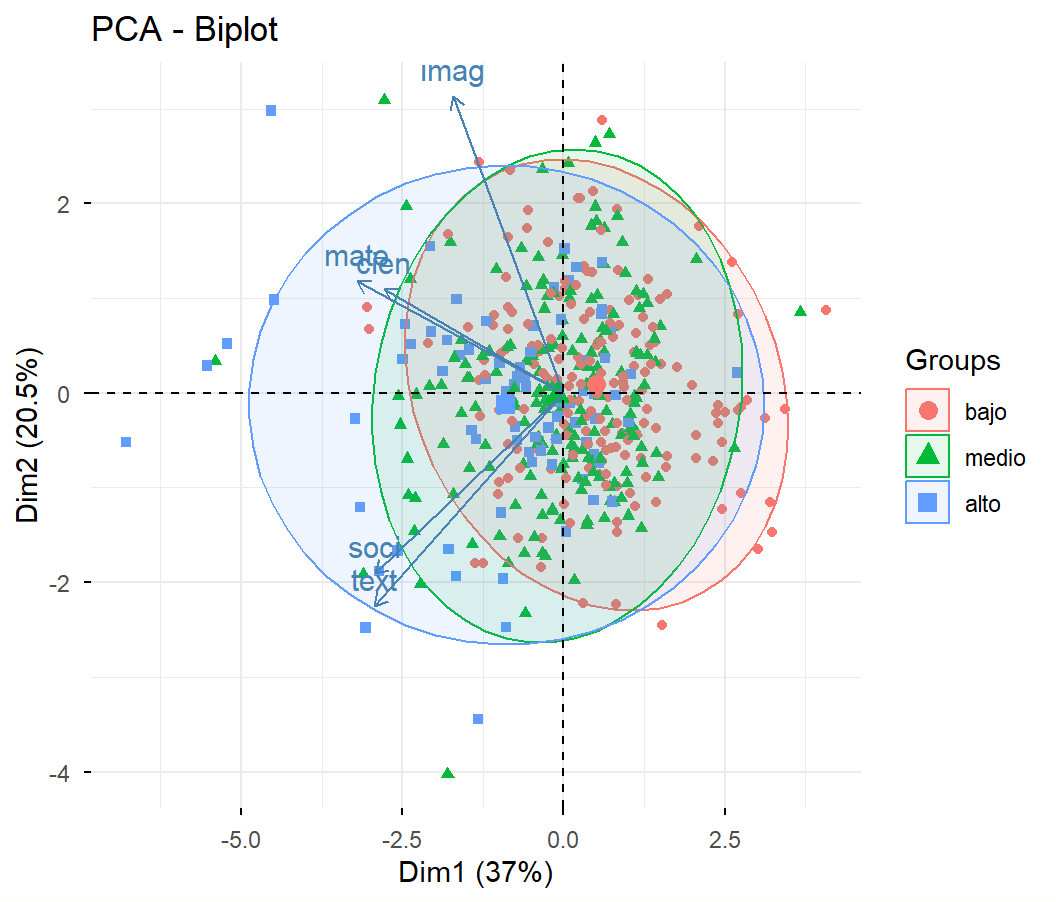
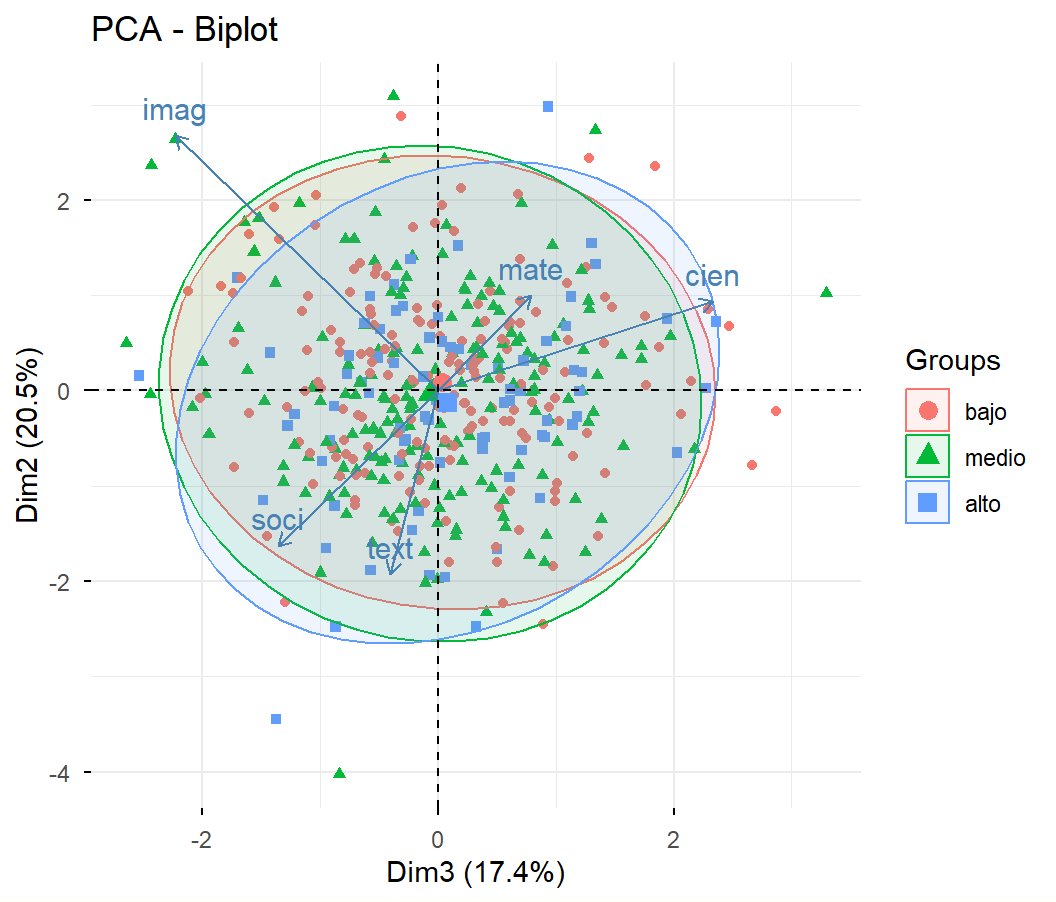
# Si no está cargado, cargar paquete FactoClass:if(!require(FactoClass)){install.packages("FactoClass"); library(FactoClass)}acp<-dudi.pca(admi[, 2:6], scannf=FALSE, nf=5)# col 2 a 6 son: mate, cien, soci, text, imag
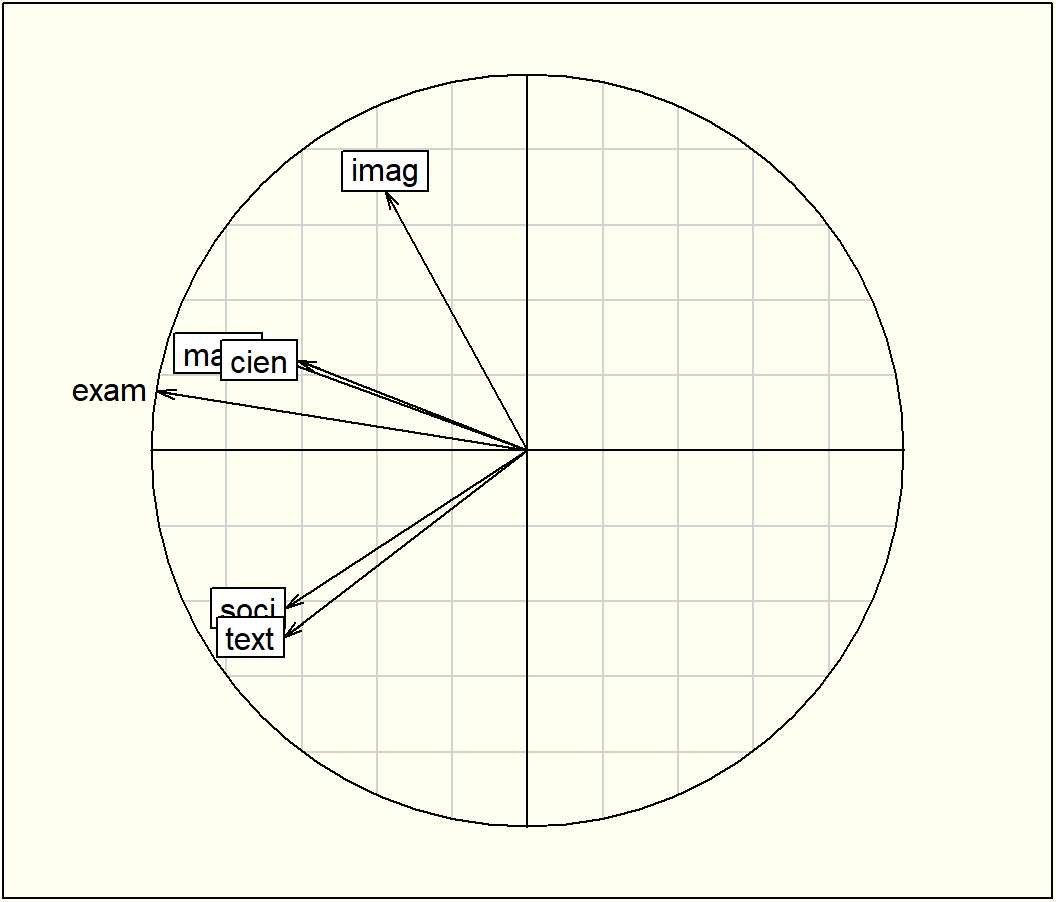
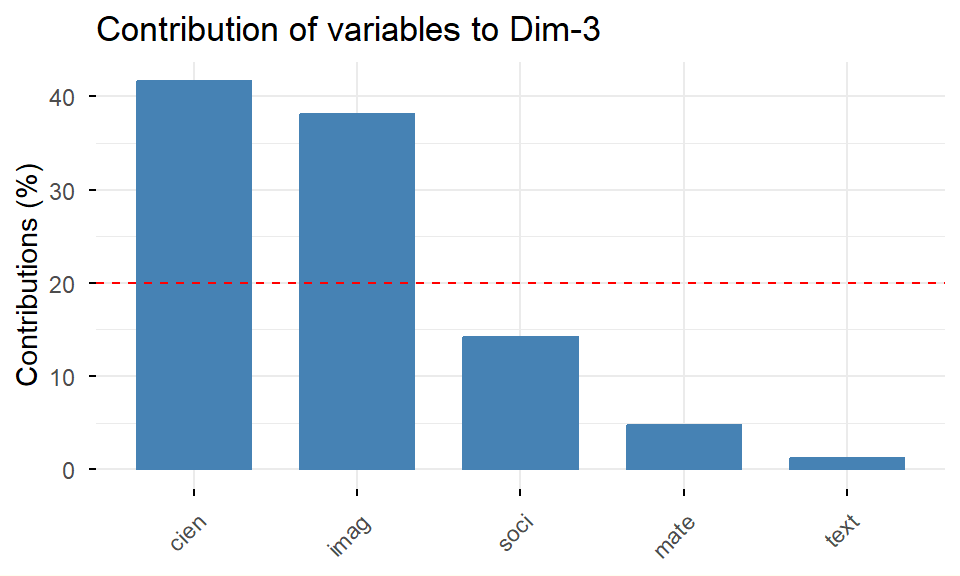
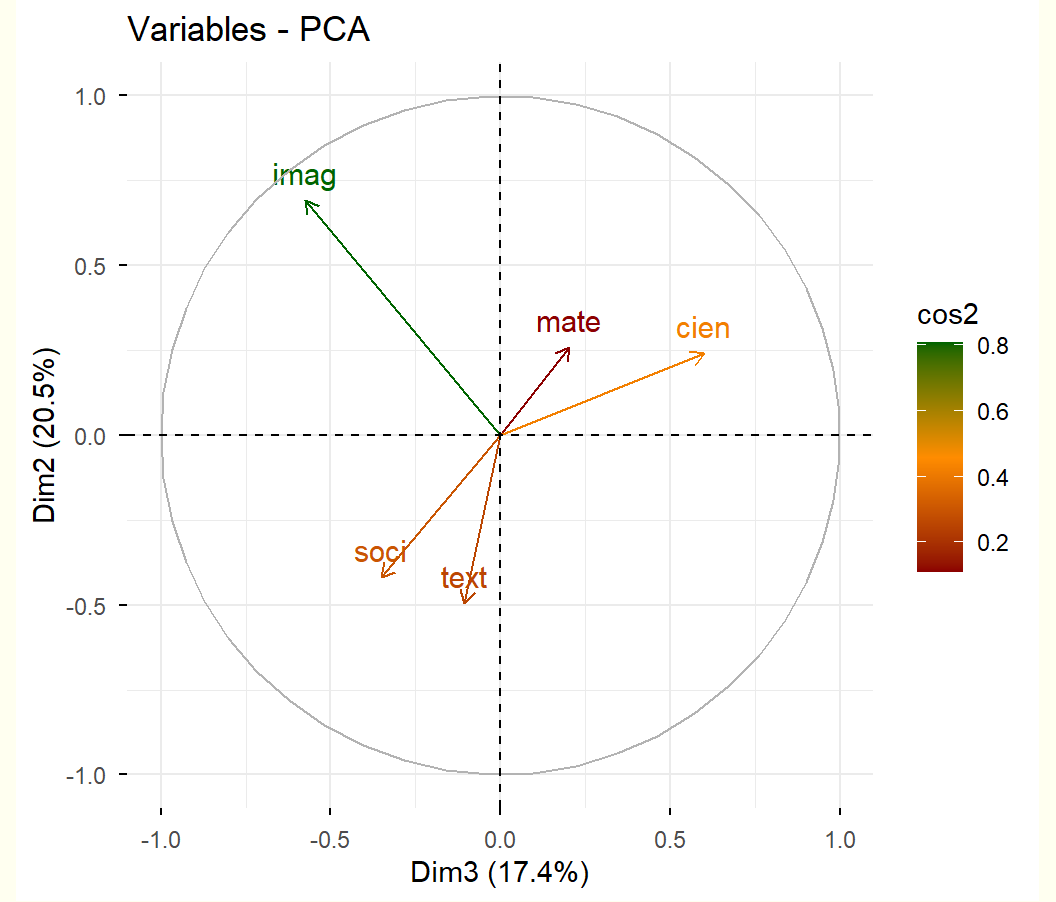
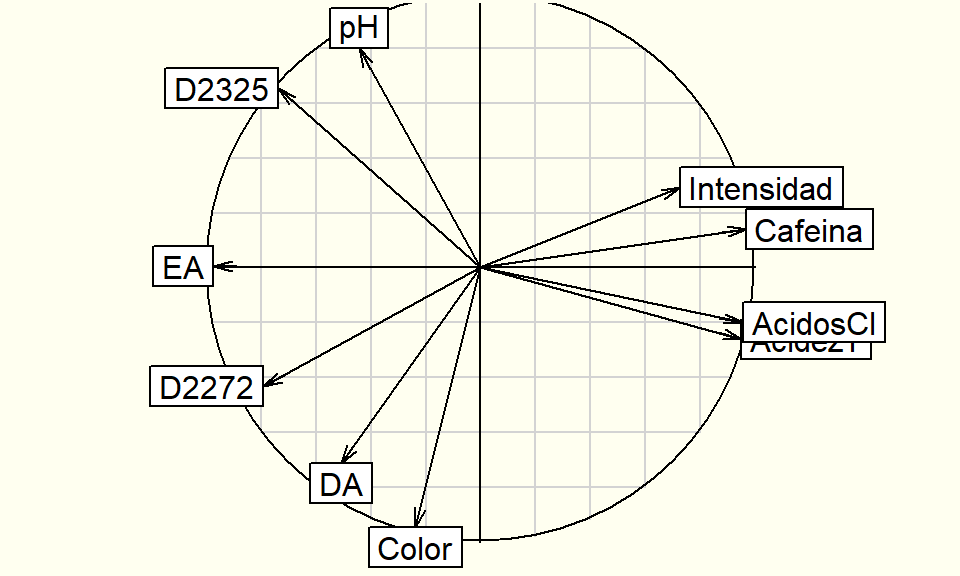
# Gráfico del plano factorial 3,2s.corcircle(acp$co, xax =3, yax =2)s.arrow(Gexam, xax =3, yax =2, add.plot =TRUE, boxes =FALSE)
Ayudas numéricas para la interpretación:
Código
# Ayudas numéricas para interpretaciónvar<-get_pca_var(acp)var
Principal Component Analysis Results for variables
===================================================
Name Description
1 "$coord" "Coordinates for the variables"
2 "$cor" "Correlations between variables and dimensions"
3 "$cos2" "Cos2 for the variables"
4 "$contrib" "contributions of the variables"
A continuación utilizaremos el ejemplo que se presenta en la pág. 41 del libro de Estadística Descriptiva Multivariada del Profesor Campo Elías. Adicionalmente, este es un extracto del resumen (abstract) del artículo origen de los datos:
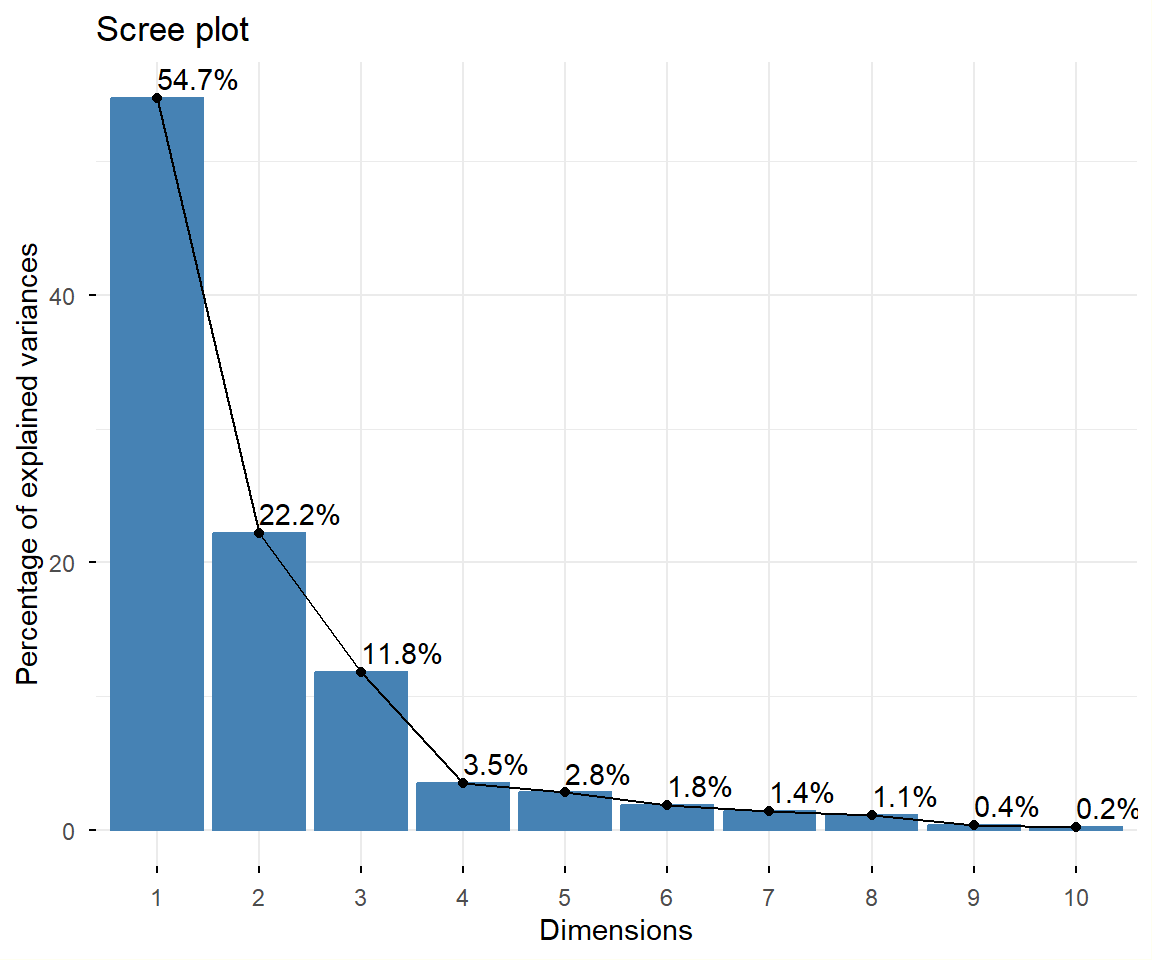
“Ocasionalmente el café tostado y molido es objeto de adulteraciones, mediante la adición de toda clase de materiales extraños. Debido a que estos adulterantes modifican notablemente las características sensoriales, químicas y físicas del café, es necesario desarrollar métodos de análisis que permitan establecer el grado contenido en un producto comercial. En este estudio se analizaron 14 muestras y se realizaron determinaciones de color, acidez titulable, extracto acuoso, contenido de ácidos clorogénicos, cafeína, intensidad del aroma, acidez, amargo y cuerpo, entre otros. Se buscó sintetizar la información contenida en cada una de las determinaciones, con el fin de obtener tanto relaciones entre éstas, así como una evaluación de las muestras estudiadas. Con el análisis estadístico multivariado por componentes principales realizado se logró reducir la dimensión del problema de 16 variables estudiadas a sólo 3 factores, manteniéndose representativamente el 85,36% de la variación total…”
Duarte et al. (1996). Análisis multivariado por componentes principales, de cafés tostados y molidos adulterados con cereales. Cenicafé, 478(2):65-76
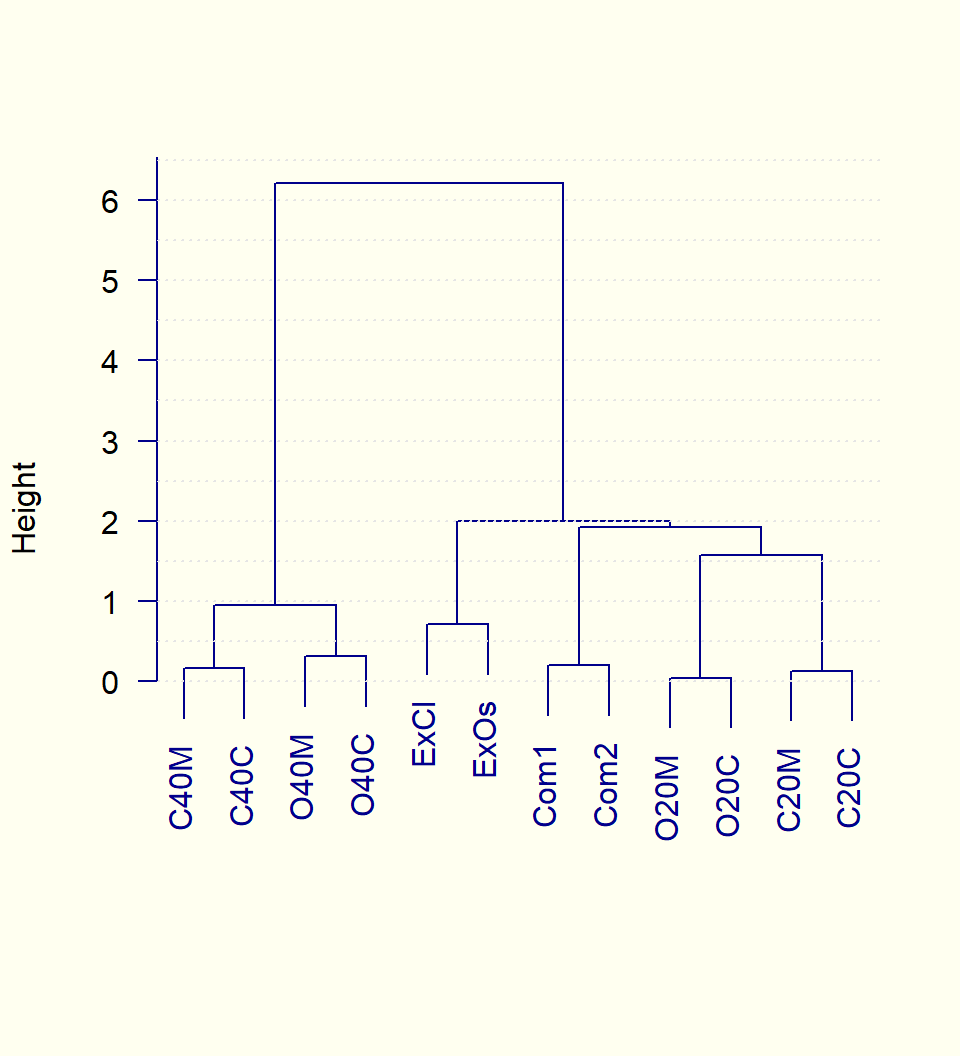
7.4.2.1 Tabla de datos “café”
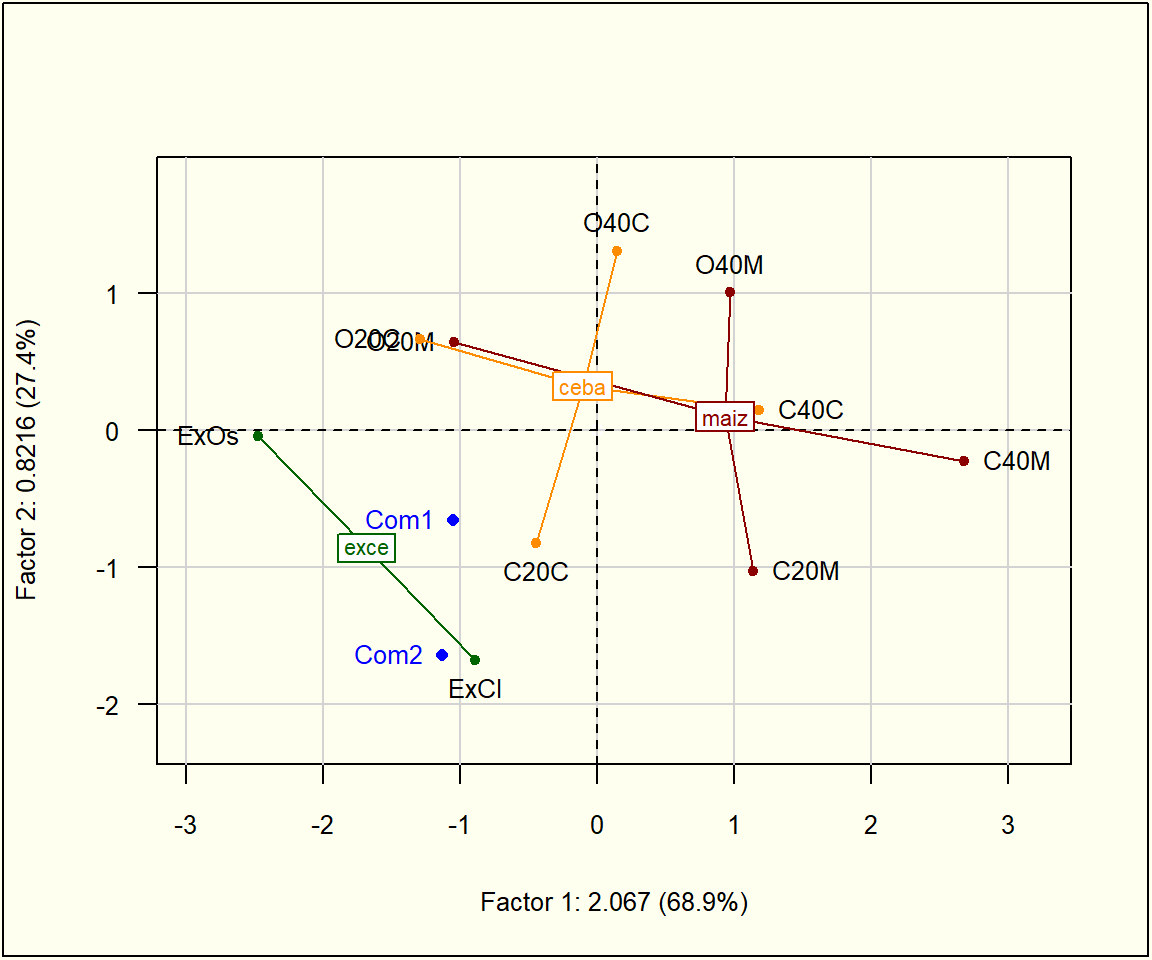
Se usa una identificación nemotécnica de los individuos, que corresponden a 2 marcas comerciales de café y a 10 tratamientos del experimento (Agregado: Sin, Maíz, Cebada. Porcentaje del Agregado: 0, 20% y 40%. Grado de tostión: Clara y Oscura).
Código
# Si no está cargado, cargar paquete FactoClass:if(!require(FactoClass)){install.packages("FactoClass"); library(FactoClass)}data(cafe)# cargar datos cafe de FactoClass
Color DA EA pH AcidezT Cafeina
Min. :186 Min. :347 Min. :23 Min. :5.0 Min. : 4.9 Min. :0.79
1st Qu.:225 1st Qu.:369 1st Qu.:28 1st Qu.:5.1 1st Qu.: 6.3 1st Qu.:0.81
Median :271 Median :402 Median :34 Median :5.2 Median : 7.8 Median :1.10
Mean :271 Mean :402 Mean :34 Mean :5.2 Mean : 8.0 Mean :1.08
3rd Qu.:316 3rd Qu.:423 3rd Qu.:40 3rd Qu.:5.3 3rd Qu.: 9.3 3rd Qu.:1.31
Max. :361 Max. :481 Max. :43 Max. :5.4 Max. :11.7 Max. :1.40
AcidosCl D2325 D2272 Intensidad Aroma Cuerpo
Min. :1.35 Min. :-0.101 Min. :-0.065 Min. :6.0 Min. :5.4 Min. :6.2
1st Qu.:1.62 1st Qu.:-0.079 1st Qu.:-0.056 1st Qu.:6.5 1st Qu.:5.9 1st Qu.:6.6
Median :1.95 Median :-0.055 Median :-0.048 Median :6.7 Median :6.3 Median :6.8
Mean :1.99 Mean :-0.058 Mean :-0.049 Mean :6.8 Mean :6.4 Mean :6.8
3rd Qu.:2.22 3rd Qu.:-0.039 3rd Qu.:-0.038 3rd Qu.:7.0 3rd Qu.:6.8 3rd Qu.:7.0
Max. :2.84 Max. :-0.025 Max. :-0.036 Max. :7.7 Max. :7.4 Max. :7.4
Acidez Amargo Astringencia Impresion
Min. :4.0 Min. :4.4 Min. :4.8 Min. :5.7
1st Qu.:4.4 1st Qu.:4.8 1st Qu.:4.8 1st Qu.:6.0
Median :4.6 Median :5.0 Median :4.9 Median :6.2
Mean :4.6 Mean :4.9 Mean :5.0 Mean :6.5
3rd Qu.:4.7 3rd Qu.:5.1 3rd Qu.:5.2 3rd Qu.:7.0
Max. :5.1 Max. :5.6 Max. :5.4 Max. :7.5
Imagine un análisis bivariado de todas las variables
7.4.2.2 Nubes de puntos
Inicialmente, tomemos solamente los datos de dos individuos y tres variables (numéricas):
Código
# Individuos 1 y 6 ("ExCl" y "ExOs")# Variables 1 a 3 ("Color", "DA", "EA")Y<-cafe[c(1,6), 1:3]# datos seleccionados
Color
DA
EA
ExCl
298
385
25
ExOs
186
347
28
Esta matriz, que denotaremos como Y, está conformada por vectores columna que representan a las variables, por un lado, y por vectores fila que representan a los individuos, por el otro.
7.4.2.3 Nube de variables
Cada punto representa una variable en un espacio de tantas dimensiones como individuos. Cada punto corresponde a un vector columna.
Código
Y<-cafe[c(1,6), 1:3]# datos seleccionadostY<-as.data.frame(t(Y))# transpuesta# Si no está cargado, cargar paquete plotlyfig<-plot_ly(tY, x =~ExOs, y =~ExCl)fig<-fig%>%add_markers(text =rownames(tY))fig<-fig%>%add_text(text =rownames(tY), textposition ="top")fig<-fig%>%layout(title ="Nube de variables", xaxis =list(range =c(-10,400)), yaxis =list(range =c(-10,450)), showlegend =FALSE)fig
7.4.2.4 Nube de individuos
Cada punto representa un individuo en un espacio de tantas dimensiones como variables. Cada punto corresponde a un vector fila.
Código
Y<-cafe[c(1,6), 1:3]# datos seleccionados# Si no está cargado, cargar paquete plotly:fig<-plot_ly(Y, x =~Color, y =~DA, z =~EA)fig<-fig%>%add_markers(text =rownames(Y))fig<-fig%>%add_text(text =rownames(Y))fig<-fig%>%layout(title ="Nube de individuos", scene =list(xaxis =list(range =c(0,350)), yaxis =list(range =c(0,450)), zaxis =list(range =c(0,35))), showlegend =FALSE)fig
A continuación nos enfocaremos primero en la nube de individuos.
7.4.2.5 Centro de gravedad
Sumar los vectores fila (uno por individuo) y dividir por la cantidad de individuos:
Es una suma ponderada en donde todos los individuos tienen la misma ponderación: \tfrac{1}{n}.
Código
# Individuos 1 a 10 (Todos menos los cafés comerciales)# Variables 1 a 3 ("Color", "DA", "EA")Y<-cafe[1:10, 1:3]g<-colMeans(Y)# centro de gravedad
Código
# Si no está cargado, cargar paquete plotlyfig<-plot_ly(Y, x =~Color, y =~DA, z =~EA)fig<-fig%>%add_markers()fig<-fig%>%add_text(text =rownames(Y))fig<-fig%>%add_markers(x =g[1], y =g[2], z =g[3])fig<-fig%>%layout(showlegend =FALSE)fig
7.4.2.6 Centrado
Centrar los puntos es hacer que el centro de gravedad quede en el origen de las coordenadas (“en el cero”).
A cada vector fila se le resta el vector de medias, de esta manera se da una traslación de todos los individuos. Esta operación se escribiría así para cada vector fila (para el i-ésimo): \vec{y}_C = \vec{y}_i - \vec{\mathrm{g}}, y matricialmente, así: Y_C = Y - \mathbf{1}_n \, \vec{\mathrm{g}}'.
Código
Y<-cafe[1:10, 1:3]# datos seleccionadosn<-nrow(Y)# número de individuosp<-ncol(Y)# número de variablesunos<-rep(1, n)# vector de n unosYc<-Y-unos%*%t(g)# Centradofig<-plot_ly(Yc, x =~Color, y =~DA, z =~EA)fig<-fig%>%add_markers()fig<-fig%>%add_text(text =rownames(Yc))fig<-fig%>%add_markers(x =0, y =0, z =0)fig<-fig%>%layout(showlegend =FALSE)fig
Min. 1st Qu. Median Mean 3rd Qu. Max.
16 46 84 91 120 221
La distancia euclidiana al cuadrado entre dos individuos (dos vectores fila) es la suma de las diferencias al cuadrado de sus componentes variable por variable:
Suma ponderada en donde cada diferencia al cuadrado por variable tienen la misma ponderación: 1.
7.4.2.8 Inercia, reducción y estandarización
La inercia de la nube de individuos es la suma de las varianzas de las variables.
\begin{aligned}
Inercia\left(N_{n_Y}\right) &= \sum\nolimits_{i=1}^{n}{ \tfrac{1}{n} \, d^2\left(\vec{y}_i,\vec{\mathbf{g}}\right)} = \sigma_1^2 + \sigma_2^2 + \dots + \sigma_p^2
\end{aligned}
Si a cada término de la matriz Y lo centramos y luego lo reducimos (cambiamos a una escala común, eliminando las unidades), entonces obtenemos, x_{ij}=\tfrac{y_{ij}-\bar{y}_j}{\sigma_j} donde \bar{y}_j y \sigma_j son respectivamente la media y la desviación estándar de la variable j (al centrar y reducir estamos estandarizando). Matricialmente, X = Y_C \, D_{\sigma}^{-1} donde D_{\sigma}=diag(\sigma_{_j}). Además, la inercia de la nube estandarizada es,
\begin{aligned}
Inercia\left(N_{n_X}\right) &= 1 + 1 + \dots + 1 = p
\end{aligned}
7.4.2.9 Resultado de la estandarización (individuos)
fig<-plot_ly(X, x =~Color, y =~DA)fig<-fig%>%add_markers(text =rownames(X))fig<-fig%>%add_text(text =rownames(X), textposition ="top")fig<-config(fig, displayModeBar =FALSE)%>%layout(xaxis =list(range =c(-2.5,2.5)), yaxis =list(range =c(-2.5,2.5)), showlegend =FALSE)fig
Código
fig<-plot_ly(X, x =~Color, y =~EA)fig<-fig%>%add_markers(text =rownames(X))fig<-fig%>%add_text(text =rownames(X), textposition ="top")fig<-config(fig, displayModeBar =FALSE)%>%layout(xaxis =list(range =c(-2.5,2.5)), yaxis =list(range =c(-2.5,2.5)), showlegend =FALSE)fig
Código
fig<-plot_ly(X, x =~DA, y =~EA)fig<-fig%>%add_markers(text =rownames(X))fig<-fig%>%add_text(text =rownames(X), textposition ="top")fig<-config(fig, displayModeBar =FALSE)%>%layout(xaxis =list(range =c(-2.5,2.5)), yaxis =list(range =c(-2.5,2.5)), showlegend =FALSE)fig
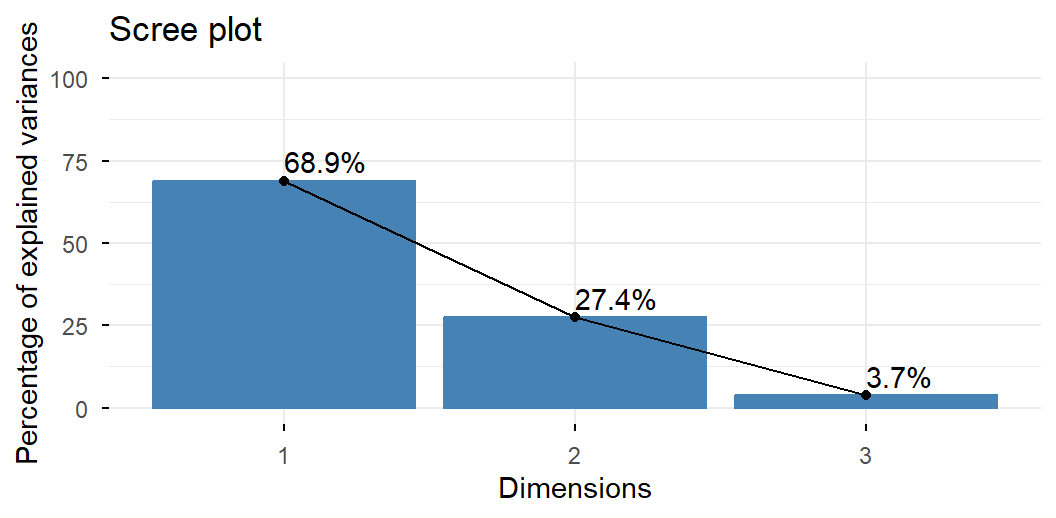
7.4.2.10 Componentes principales
Se puede demostrar que los componentes principales son ejes generados por los vectores propios (eigenvectors) de la matriz de correlaciones de las variables, si se estandarizó (análisis normado), o de la matriz de varianzas y covarianzas, si solamente se centró (análisis no normado). Las componentes se ordenan de mayor a menor magnitud de sus correspondientes valores propios (eigenvalues).
Los vectores propios\left(\vec{u_j}\right) de cierta transformación lineal (T) (por ejemplo, dada por una matriz A) son los vectores que después de sufrir la transformación, solamente cambian su magnitud \left(T\left(\vec{u_j}\right) = A \vec{u_j} = \lambda_j \vec{u_j}\right). Los escalares (\lambda_j) se denominan valores propios.
Las coordenadas de la nube de individuos en los nuevos ejes (en las componentes principales) se pueden obtener haciendo F = X U, en donde los vectores propios son los vectores columna de la matriz U (ordenados por su valor propio correspondiente: \lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_p).
Además, la inercia de la nube en esos nuevos ejes es,
\begin{aligned}
Inercia(N_{F}) &= \lambda_1 + \lambda_2 + \dots + \lambda_p = p
\end{aligned}
7.4.2.11 Resultado componentes principales (individuos)
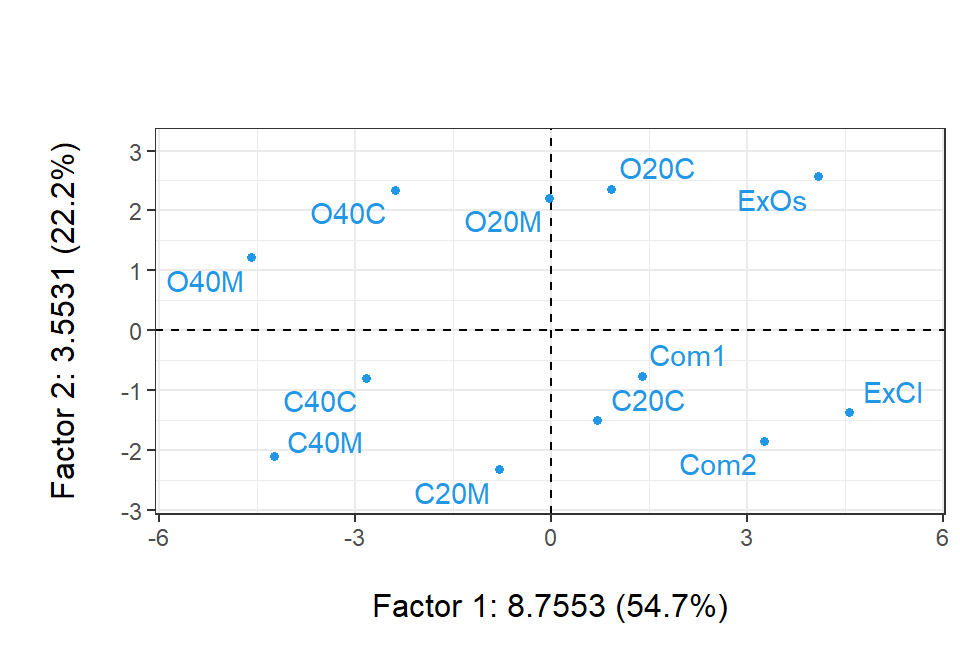
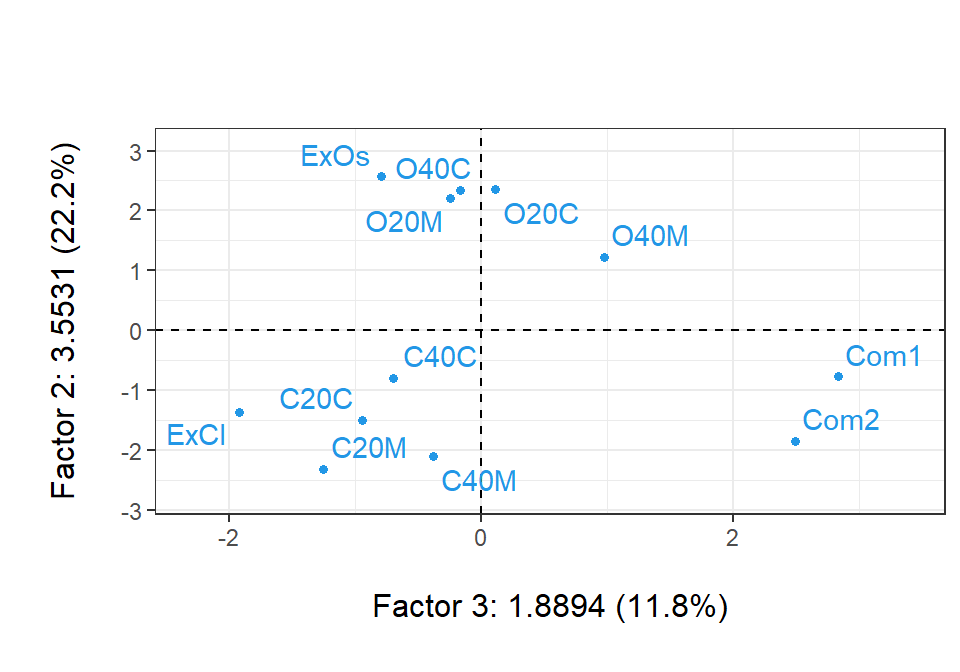
conta<-factor(c("exce","maiz","ceba","maiz","ceba","exce","maiz","ceba","maiz","ceba"))plot(acp, Tcol =FALSE, cex =.8, cex.row =.8)ade4::s.class(acp$li, conta, col =c("darkorange","darkgreen","darkred"), add.plot =TRUE, cellipse =0, clabel =0.7)lcom<-suprow(acp, cafe[11:12,1:3])$lisuppoints(lcom, col ="blue", pch =16, cex =.8)text(lcom, rownames(lcom), col ="blue", pos =2, cex =.8)
Primer plano factorial de los individuos, más información suplementaria
7.4.2.12 ¿y la nube de variables?
Código
G=acp$cofig<-plot_ly(G, x =~Comp1, y =~Comp2, z =~Comp3)# Código experimental# Graficaré como puntos pero sería mejor como flechasfig<-fig%>%add_markers(text =rownames(G))fig<-fig%>%add_text(text =rownames(G))fig<-fig%>%add_markers(x =0, y =0, z =0)sphere<-function(n=100){theta<-seq(0, pi, length.out =n)phi<-seq(0, 2*pi, length.out =n)r<-1x<-r*outer(sin(theta), cos(phi))y<-r*outer(sin(theta), sin(phi))z<-r*outer(cos(theta), rep(1, length(phi)))return(list(x =x, y =y, z =z))}s_c<-sphere()fig<-fig%>%add_trace(x =s_c$x, y =s_c$y, z =s_c$z, type ='surface', opacity =0.2, colorscale ="Greys", # cambiar por valor fijo showscale =FALSE)fig<-fig%>%layout(scene =list(xaxis =list(range =c(-1,1)), yaxis =list(range =c(-1,1)), zaxis =list(range =c(-1,1)), aspectratio =list(x=1,y=1,z=1), camera =list(eye =list(x=1,y=1,z=1))), showlegend =FALSE)fig
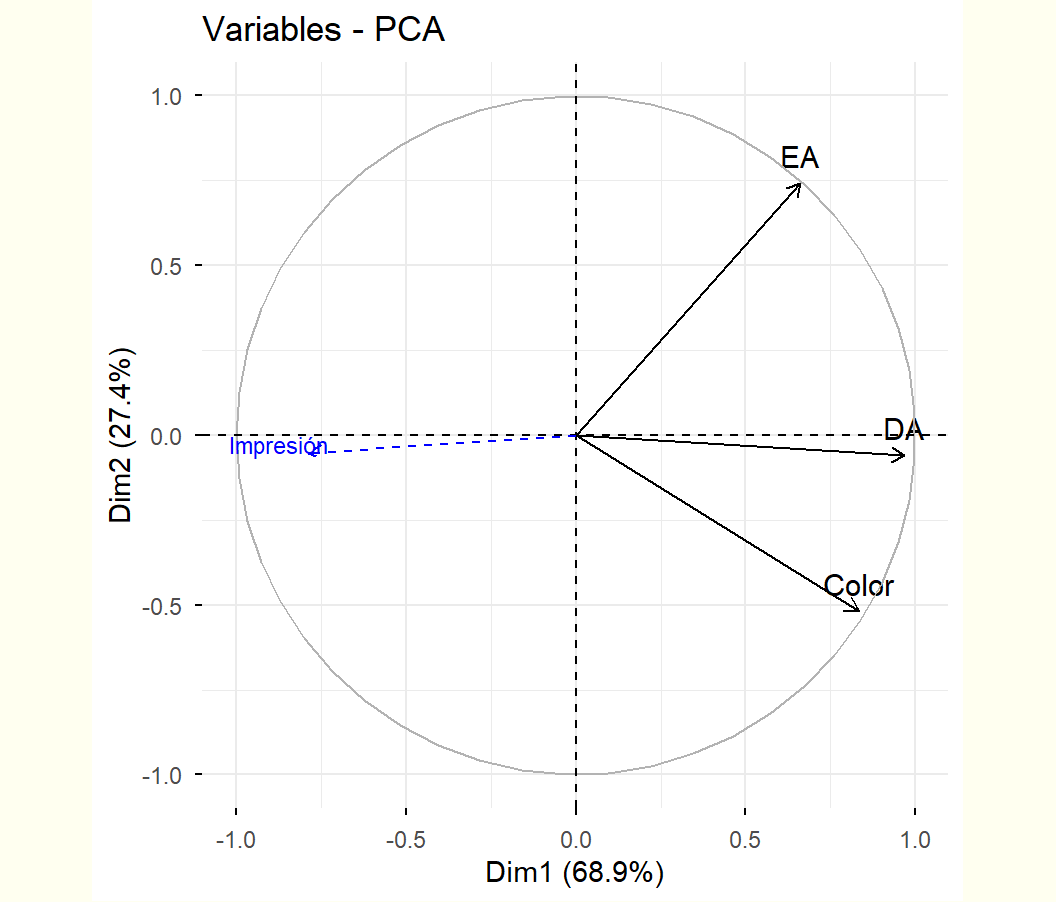
Código
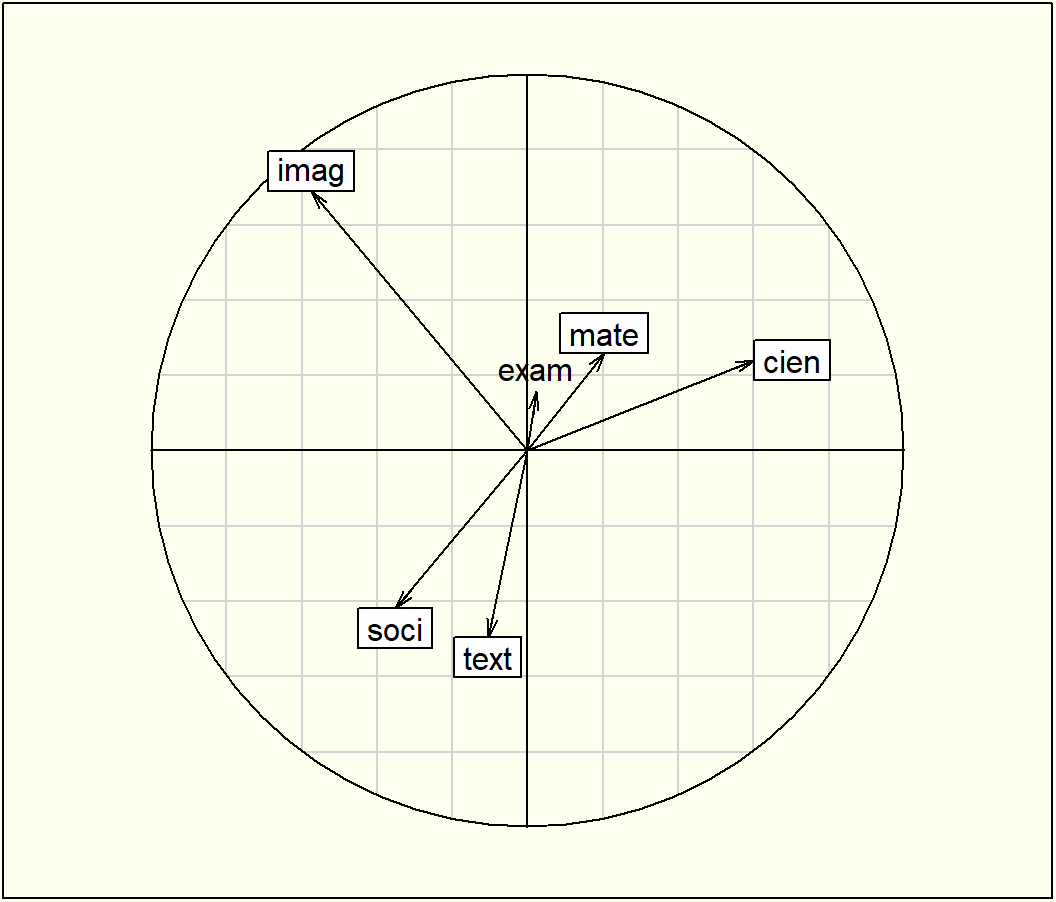
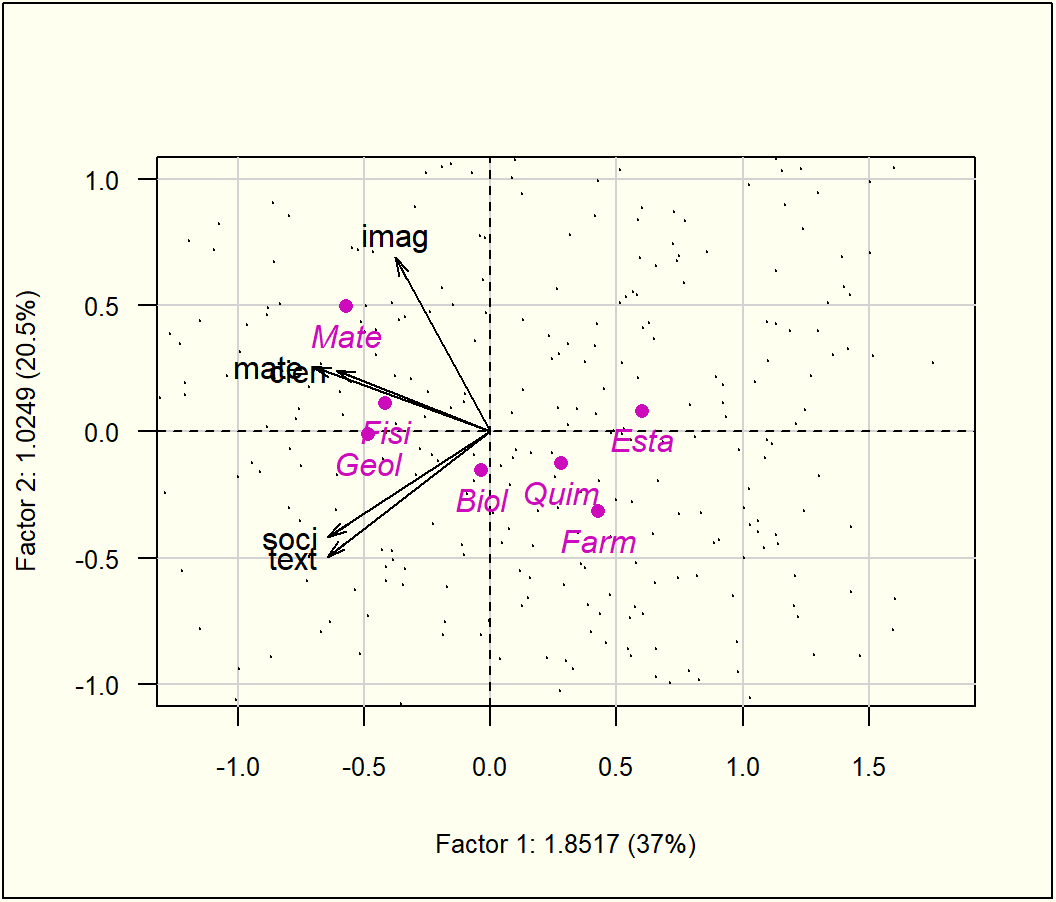
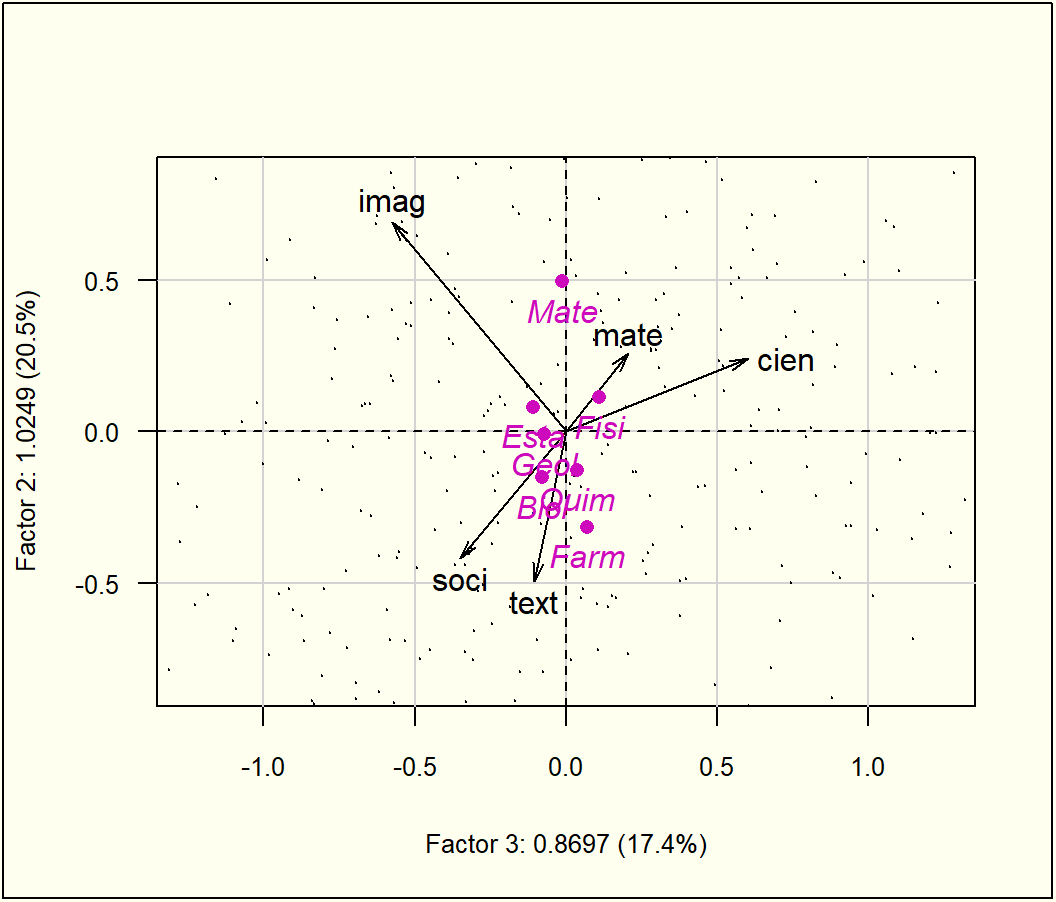
fig<-fviz_pca_var(acp, col.var ="black")coord<-cor(cafe[1:10,16], F)rownames(coord)<-"Impresión"fviz_add(fig, coord, color ="blue", geom="arrow", labelsize=3)
Primer plano factorial de las variables, más nota de impresión global de los catadores (variable suplementaria proyectada)
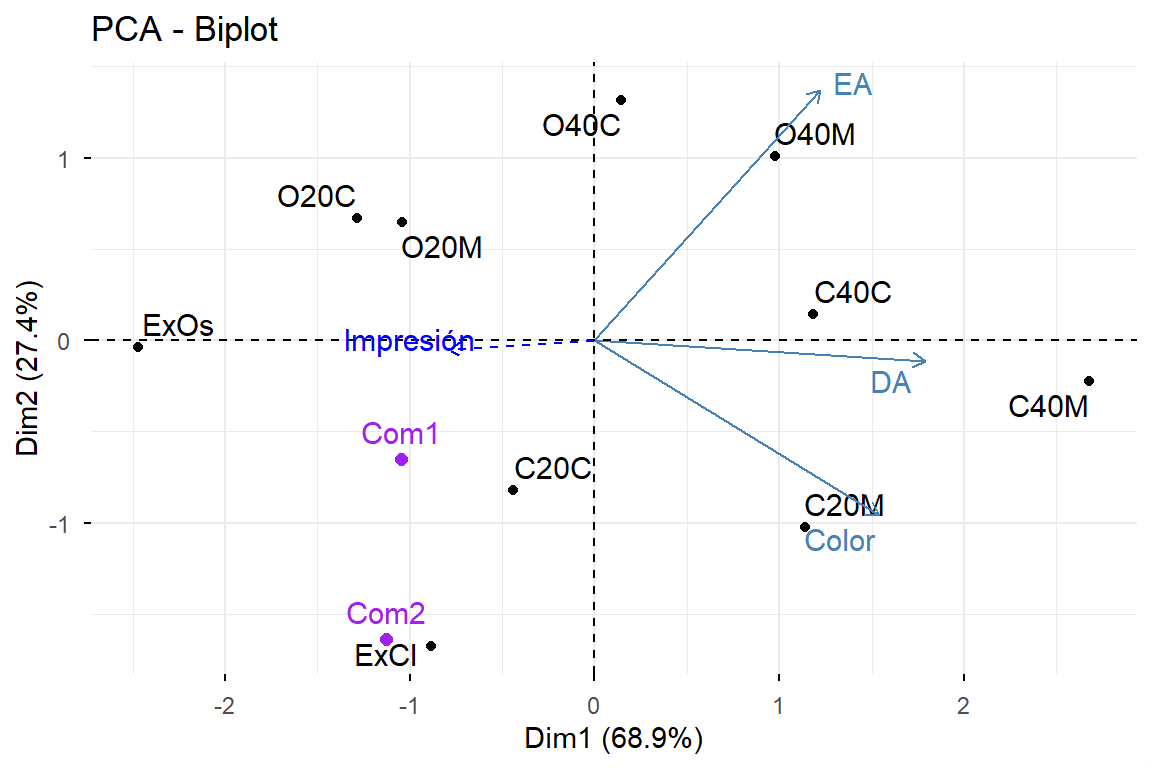
7.4.2.13 Podemos unir en un solo gráfico
Código
fig<-fviz_pca_biplot(acp, repel =TRUE)fig<-fviz_add(fig, coord, color ="blue", geom="arrow")fviz_add(fig, lcom, color ="purple", geom="point")
¿Cuál sería el resultado si hubiésemos usado más variables (por ejemplo, todas las físico-químicas)?
7.4.3 Ampliar o complementar
El contenido de esta subsección (Análisis de componentes principales) se puede ampliar o complementar con lo que se encuentra en:
PCA tutorial with R (Factoshiny & FactoMineR) (François Husson - Feb 12, 2020 - 22:26)
7.5 Análisis en componentes principales generalizado
El análisis en componentes principales (ACP), descrito previamente, se denomina ACP canónico. Esto se debe a que este análisis se apoya en la geometría canónica, es decir en la geometría usual o euclidiana.
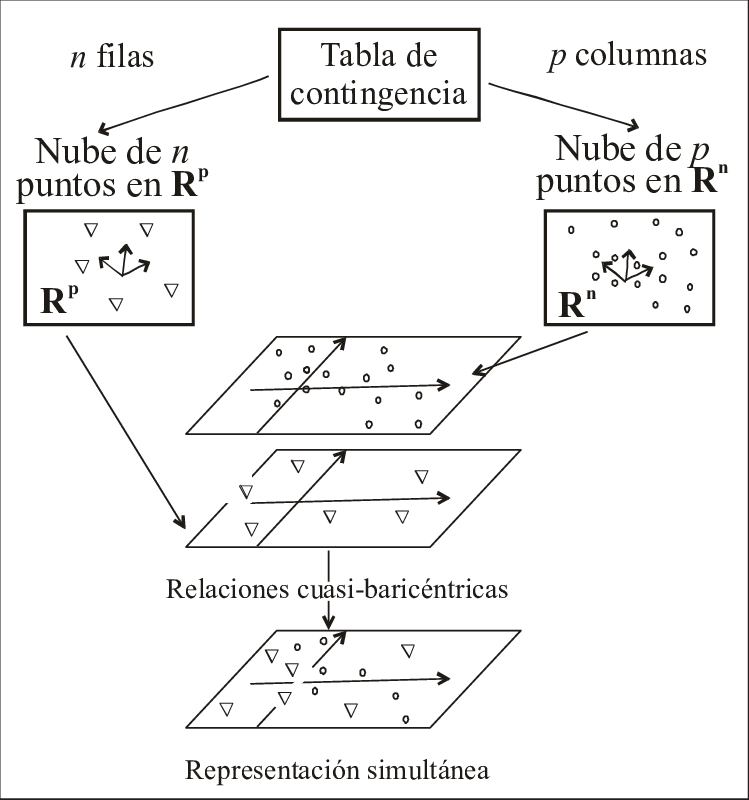
Aquí mencionamos una extensión que sirve para poner en un marco de referencia común, a los métodos denominados factoriales, dentro de los cuales están el ACP canónico y los análisis de correspondencias simples y múltiples. Dicha extensión se denomina ACP generalizado o general, y se denotará por ACP(X, M, N).
7.5.1ACP(X, M, N)
\boldsymbol{ X_{n \times p} \; : }
Matriz de n filas y p columnas, obtenida mediante alguna transformación de los datos, dependiendo del análisis a realizar.
\boldsymbol{ M_{p \times p} \; : }
Matriz diagonal de tamaño p (matriz de p valores en la diagonal y ceros fuera de la diagonal). En la diagonal están los pesos de las columnas (variables).
\boldsymbol{ N_{n \times n} \; : }
Matriz diagonal con los pesos de las filas (individuos).
7.5.2 Matrices X, M y N del ACP canónico
La matriz de trabajo ( X ) es la matriz de datos solamente centrada (X = Y_C) (ACP no normado) o estandarizada (X = Y_C \, D_{\sigma}^{-1}) (ACP normado).
Los pesos de las variables se evidencian en la distancia euclidiana entre individuos,
Por lo tanto, el ACP canónico (normado) se puede escribir como el ACP generalizado:
ACP\left(X = Y_C \, D_{\sigma}^{-1} \, , \, M = I_p \, , \, N = \frac{1}{n} I_n\right)
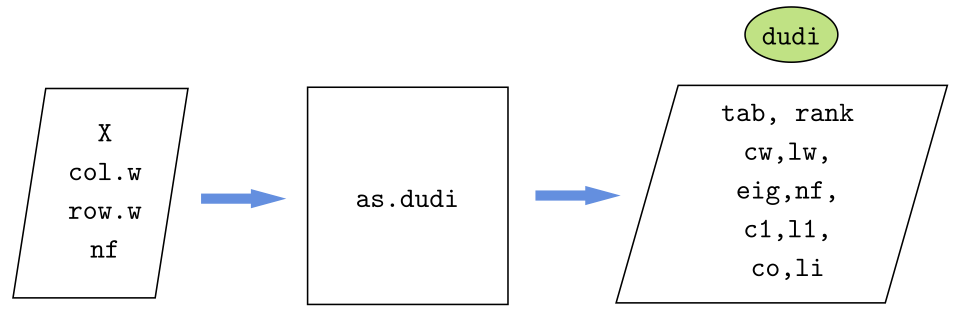
7.5.3 Función as.dudi de ade4
as.dudi es una función del paquete ade4 para obtener un ACP generalizado (consultar la ayuda: ?as.dudi).
7.5.4 ¿Para qué sirve?
7.5.4.1 Imagen de matriz de covarianzas o de matriz de correlaciones
Podemos usar el ACP generalizado para producir una representación gráfica de la relación lineal entre variables, directamente de una matriz de varianzas y covarianzas o de una matriz de correlaciones.
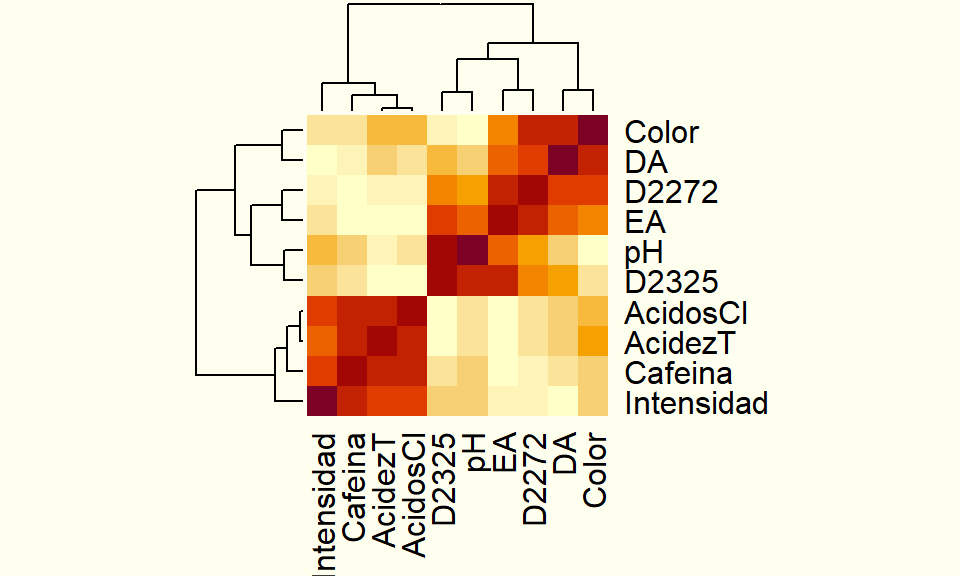
Supongamos que solamente tenemos la siguiente matriz de correlaciones (primeras 10 variables (cuantitativas) de los datos cafe del paquete FactoClass):
También podemos usar el ACP generalizado para producir una representación gráfica de lo cerca o lejos que están los individuos unos de otros, partiendo de una matriz de distancias euclidianas entre ellos.
Supongamos que solamente tenemos la matriz de distancias (individuos de los datos cafe del paquete FactoClass):
En este caso, todo lo que se puede hacer y lograr con un ACP canónico para una nube de individuos, también se puede realizar con el análisis en coordenadas principales de una matriz de distancias euclidianas.
7.5.4.3 Análisis de correspondencias simples (ACS)
El análisis de correspondencias simples (ACS) se puede realizar sobre tablas de contingencia (TC), tablas de frecuencias, y algunas tablas de números positivos para las que tenga sentido el análisis.
Un ejemplo, de una tabla de números positivos de interés que se podría describir mediante el ACS, es una tabla del producto interno bruto (PIB) agrupado según departamentos y subsectores de la economía. La suma de las filas es la distribución del PIB por departamentos y la de las columnas la distribución del PIB por subsectores de la economía. El total de la tabla es el PIB del país.
Recordemos que una tabla de contingencia (TC) es una tabla de resumen de dos variables cualitativas, las filas son categorías de una variable y las columnas son las categorías de la otra. En una celda se encuentra el número de objetos que asumen simultáneamente la categoría de la fila y la de la columna correspondientes. La suma de una fila, o de una columna, es el total de objetos que tiene la categoría respectiva.
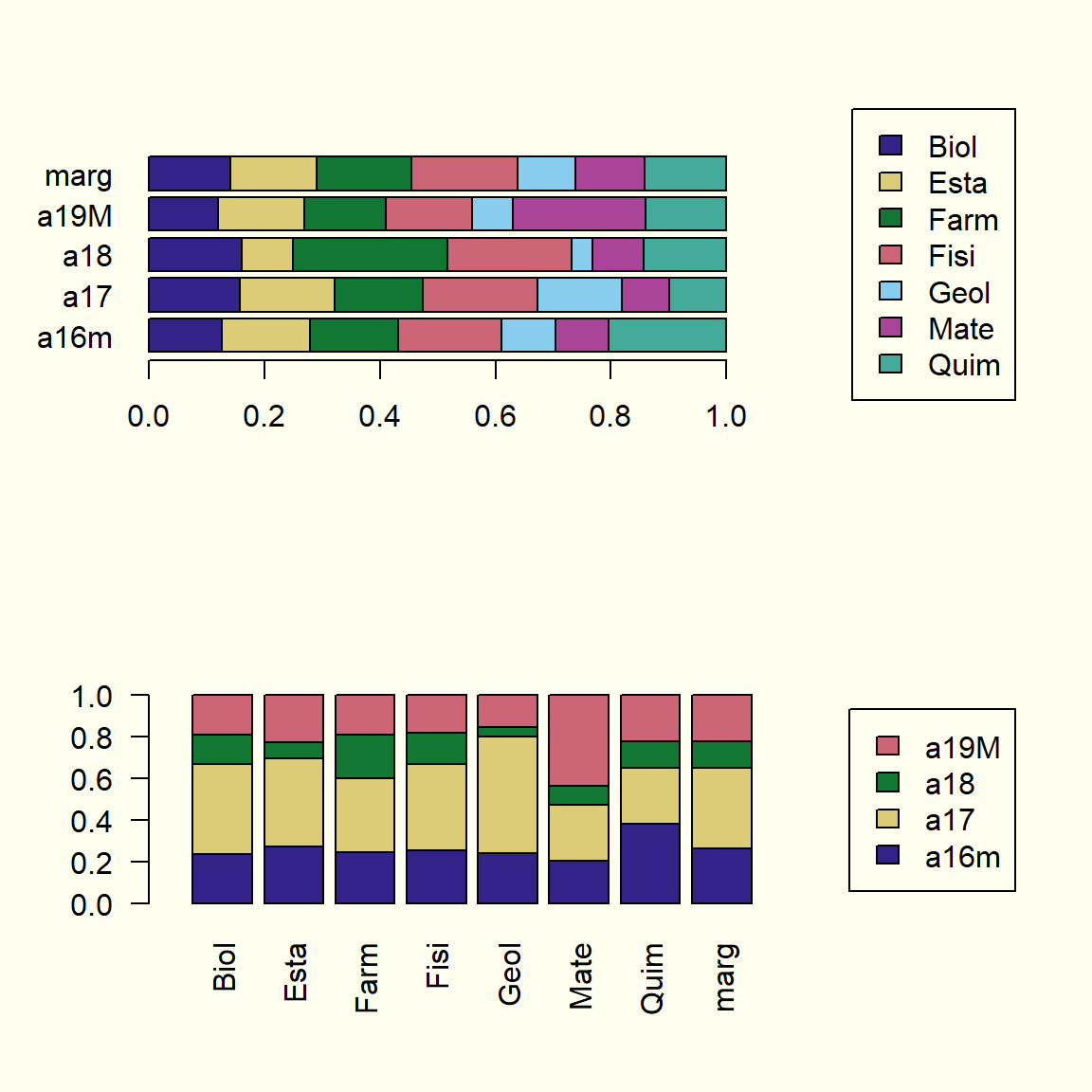
paleta7<-c("#332288", "#DDCC77", "#117733", "#CC6677", "#88CCEE", "#AA4499", "#44AA99")par(mfrow =c(2, 1))plotct(K, "row", col =paleta7)plotct(K, "col", col =paleta7[1:4])
En el caso de ACS, también tendremos las respectivas ayudas numéricas para la interpretación (inercia, valores propios, coordenadas, contribuciones y cosenos cuadrados), y elementos ilustrativos o suplementarios (filas, columnas u otras variables que no participan en la obtención de los ejes del análisis).
Otros ejemplos:
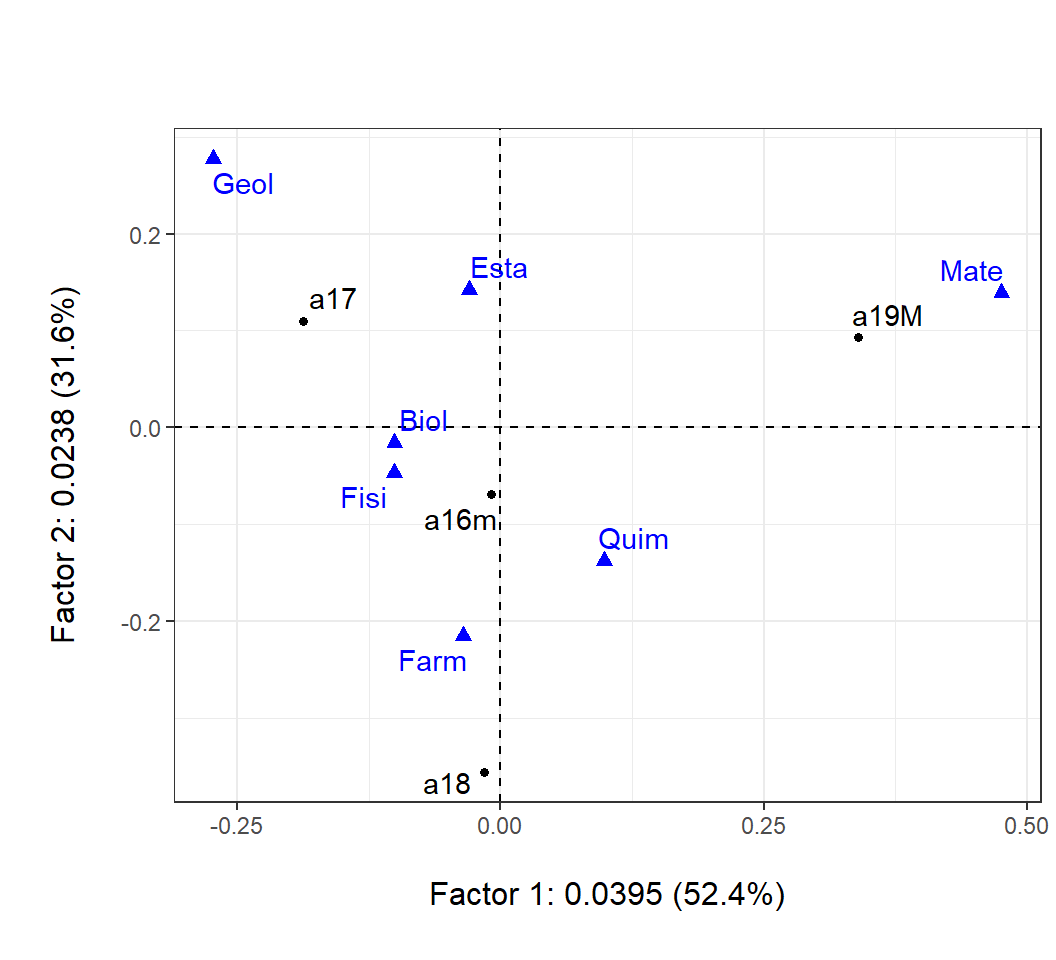
El objetivo principal del análisis es comparar los perfiles departamentales según la calidad educativa de los colegios. También se desea explorar la influencia de la jornada sobre el ordenamiento de los departamentos y la influencia de su tamaño, en términos de población, en ese ordenamiento. (Ver la ayuda de los datos ?icfes08 y la Sección 5.4. del libro de Estadística Descriptiva Multivariada del profesor Campo Elías Pardo)
Una agencia de publicidad encarga un estudio sobre las asociaciones entre colores y adjetivos, para armonizar la publicidad de los productos con las imágenes que los compradores potenciales tienen de los colores (Ver la ayuda de los datos ?ColorAdjective y el taller de la Subsección 5.6.2. del libro de Estadística Descriptiva Multivariada del profesor Campo Elías Pardo).
7.5.4.4 Análisis de correspondencias múltiples (ACM)
El análisis de correspondencias múltiples (ACM) se utiliza para analizar tablas de individuos descritos por variables cualitativas.
Para cada individuo, cada variable debe tener como valor solamente una opción o categoría (“selección múltiple con única respuesta”).
El ACM se puede ver como una extensión del ACS, pero con propiedades muy particulares.
Dependiendo del objetivo del análisis, las variables de uno de los temas suelen jugar el papel de variables activas para el análisis.
El ACM nos permite:
Descubrir asociaciones entre categorías de las variables.
Identificar posibles patrones en los individuos.
Estudiar la relación entre las categorías de las variables activas y elementos ilustrativos o suplementarios.
El ACM también se puede usar para:
Reducir la dimensión.
Separar información de “ruido”.
Dar valores numéricos a las categorías (“llevar variables cualitativas a variables cuantitativas que las puedan representar adecuadamente”).
De lo anterior se deduce que uno de los posibles usos del ACM es como un pretratamiento de los datos, para aplicar luego métodos aptos para variables cuantitativas (como por ejemplo, regresión o algunos métodos de agrupamiento y de discriminación).
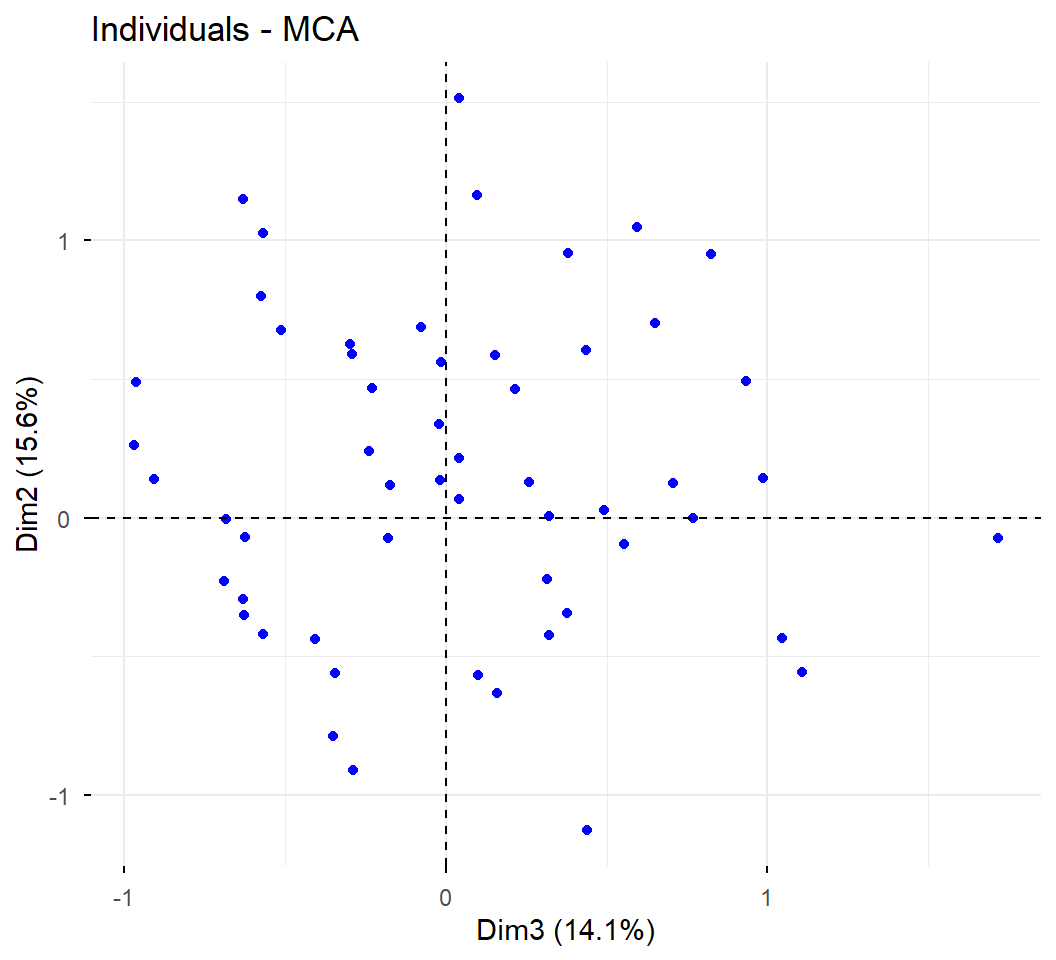
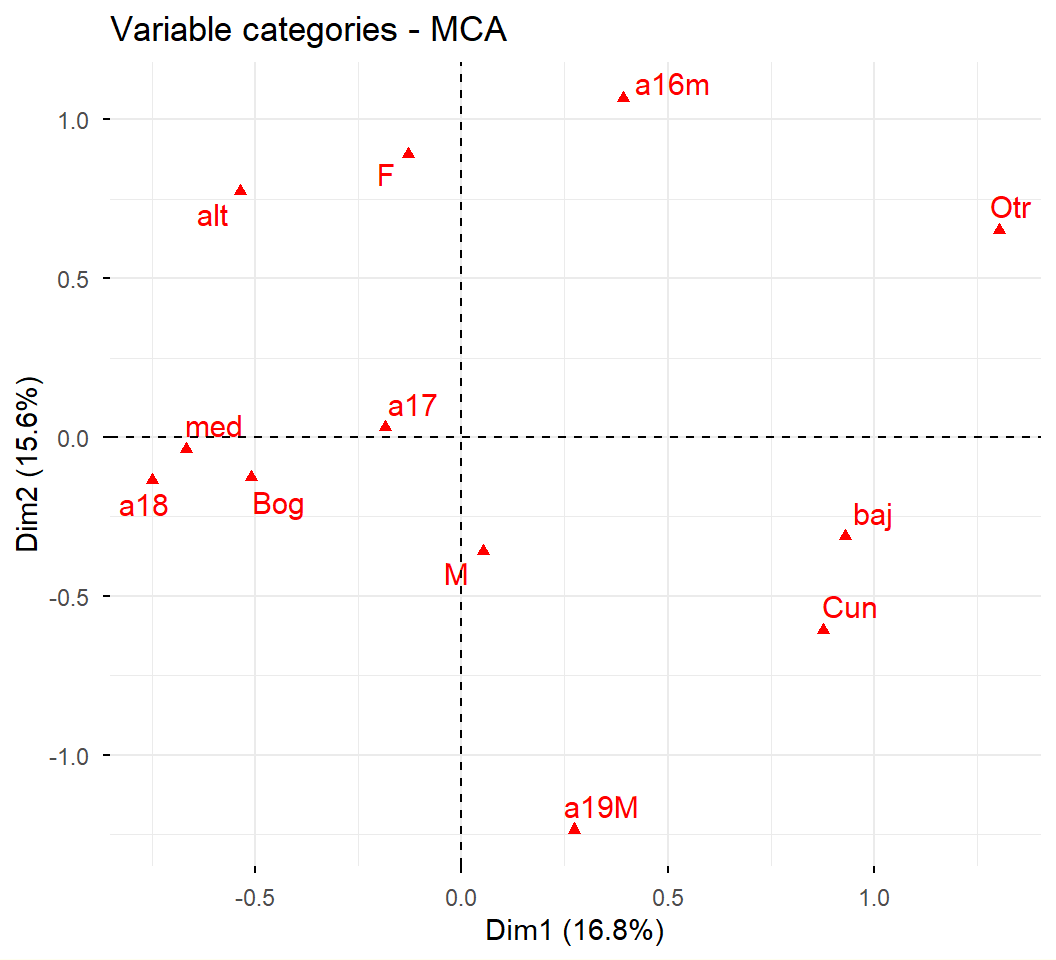
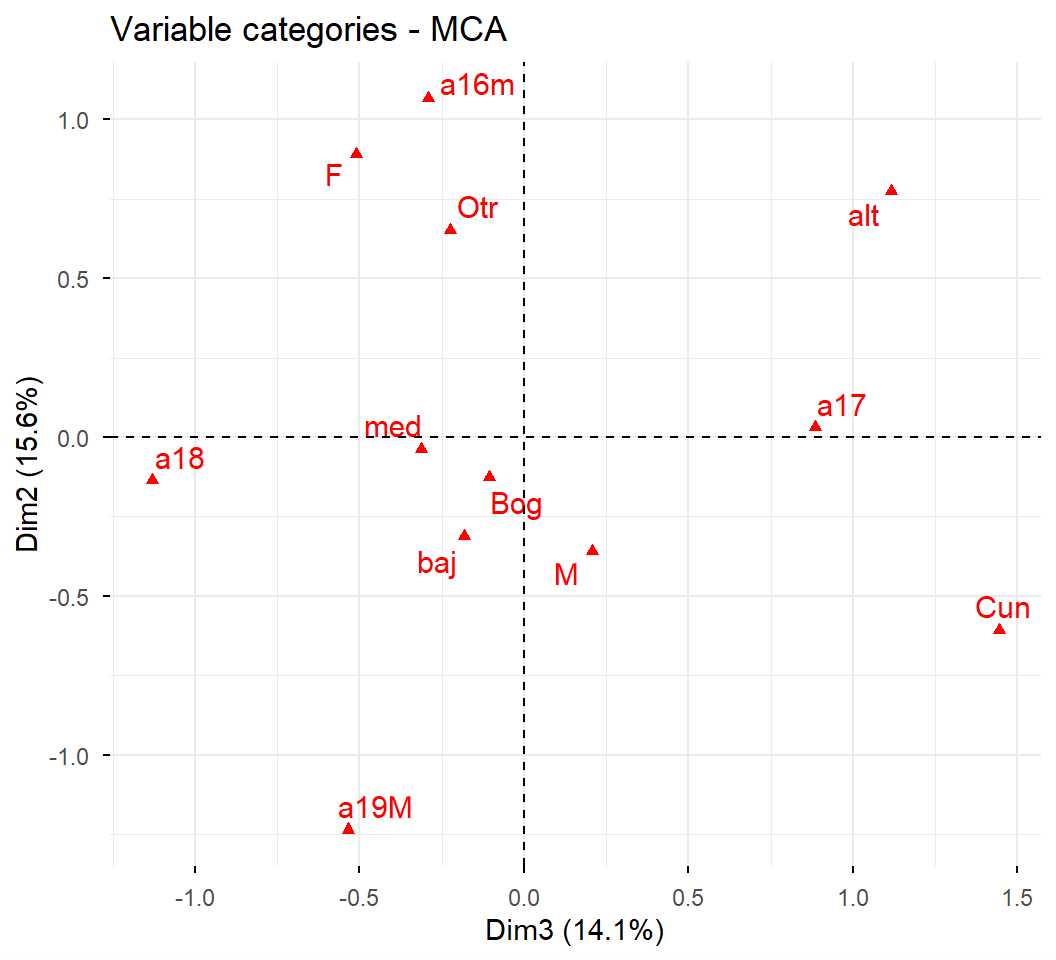
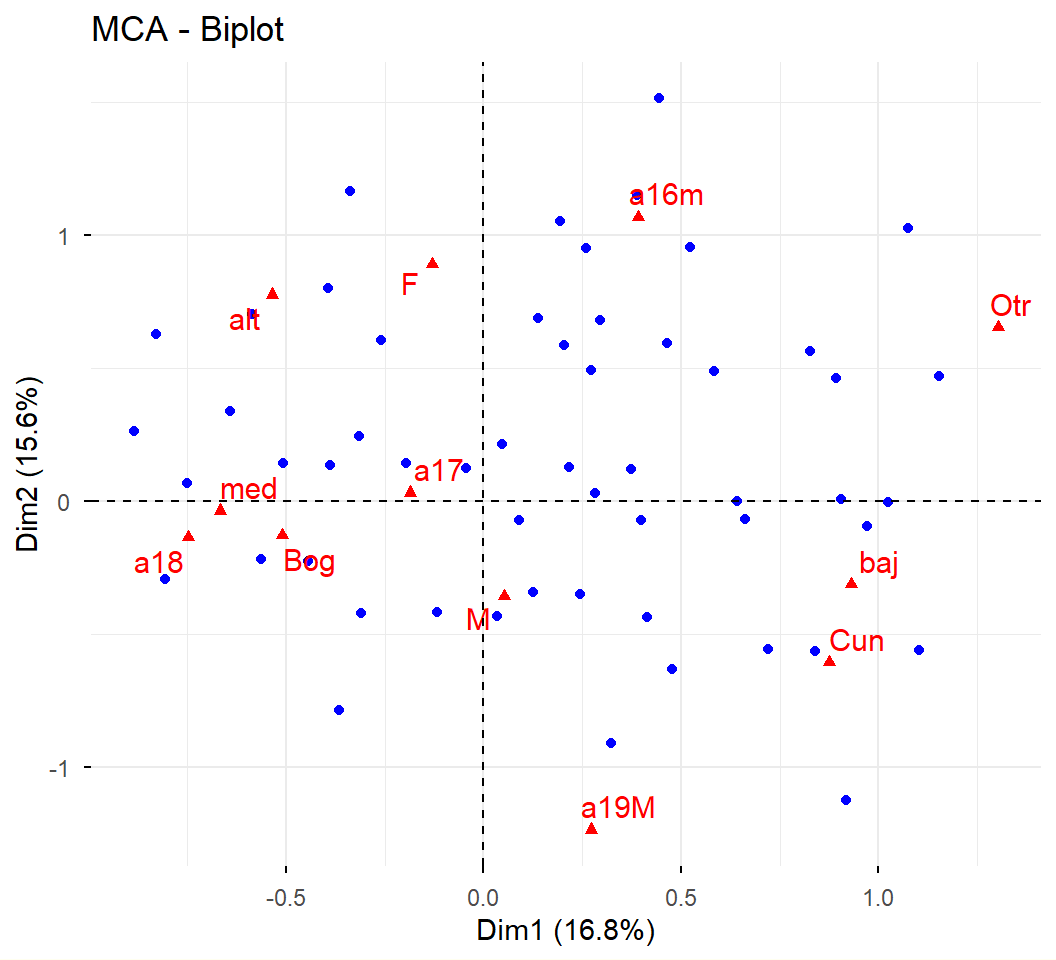
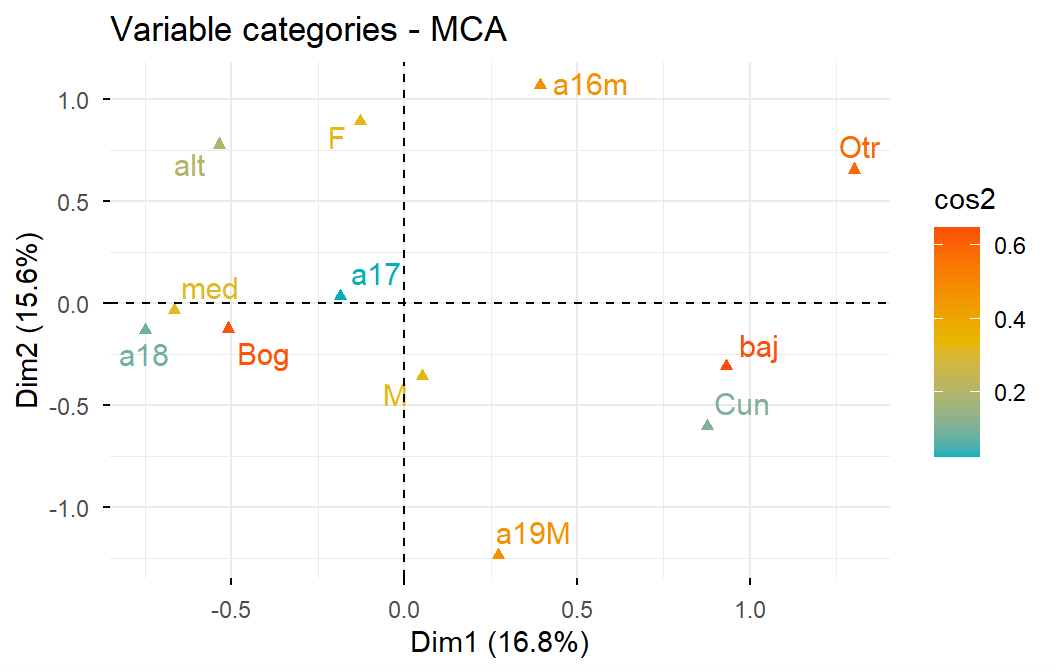
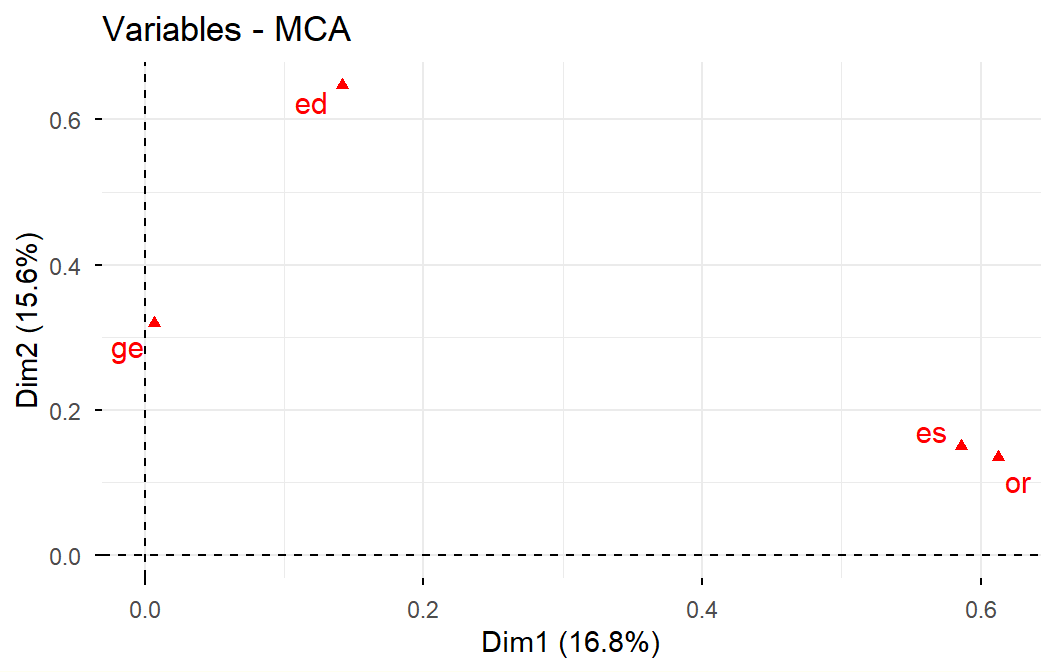
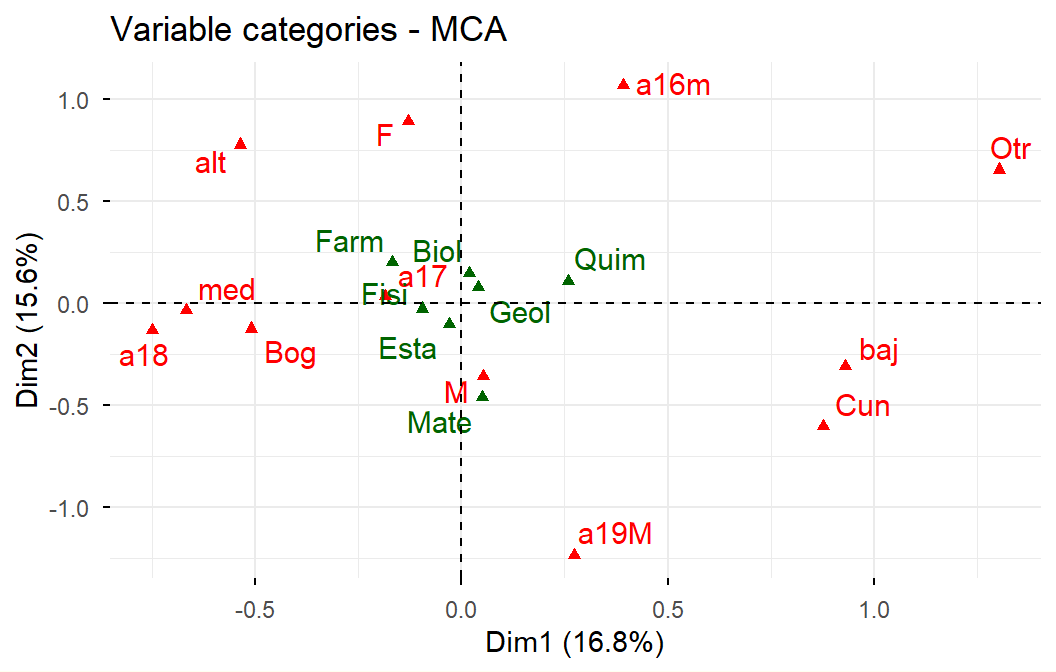
ACM a datos de admitidos:
Supongamos que los objetivos de análisis son describir el espacio sociodemográfico de los admitidos, y explorar las diferencias en las condiciones sociodemográficas, entre los grupos de admitidos según las carreras.
Se utilizan como variables activas, las sociodemográficas disponibles:
Género (gene): Femenino, Masculino
Edad (edad): 16 o menos, 17, 18, 19 o más
Estrato (estr): bajo, medio, alto
Procedencia (orig): Bogotá, Cundinamarca, Otro
IMPORTANTE: No olvidemos que en R, las variables cualitativas siempre deberían ser de tipo de dato factor.
Código
data(admi)# carga datos admi de FactoClassY<-admi[, c("gene","edad","estr","orig")]
Las filas representan los (n) individuos y las columnas las (s) variables cualitativas. Note que esta tabla no tiene significado numérico. Esta tabla se denomina Tabla de código condensado.
La tabla disyuntiva completa (TDC) es una tabla binaria, que sigue teniendo por filas los individuos, pero por columnas tiene todas las (p) categorías. ¿Qué significá el uno o cero en cada celda?¿La tabla disyuntiva completa es equivalente a realizar un one-hot encoding de todas las variables categóricas?
El ACM se podría ver como un ACS de la tabla disyuntiva completa o de la tabla de Burt. Sin embargo, en el segundo caso se perdería la información de los individuos. Por tal razón, es mejor verlo como un ACS de la TDC. Teniendo en cuenta lo anterior, el ACP generalizado correspondiente para las filas (los individuos) sería:
ACP\left(X = \tfrac{1}{s} Z \, , \, M = n s D_{p}^{-1} \, , \, N = \tfrac{1}{n} I_{n}\right)
El ACM también se podría ver como un ACP generalizado de la TDC. Bajo esta visión, el ACP generalizado correspondiente sería:
ACP\left(X = n Z D_{p}^{-1} \, , \, M = \tfrac{1}{n s} D_{p} \, , \, N = \tfrac{1}{n} I_{n}\right)
Del análisis de las filas (los individuos) concluimos que:
Dos individuos se parecen cuando asumen más o menos las mismas categorías. La distancia se amplifica más cuando uno solo de los dos individuos asume una categoría de baja frecuencia.
En el ACM se pone más atención a las categorías, porque los individuos son anónimos en la mayoría de las aplicaciones.
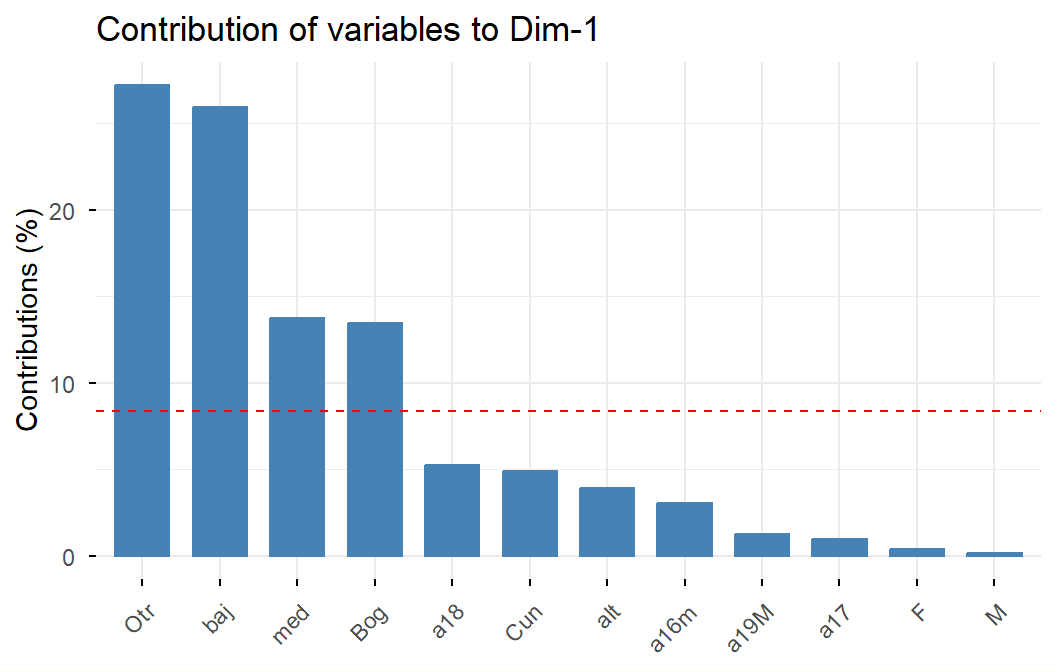
Las variables con más número de categorías contribuyen más a la inercia.
Por otro lado, las categorías de baja frecuencia contribuyen más a la inercia. En consecuencia, las categorías de menores frecuencias son las más alejadas del origen.
En el Análisis de Correspondencias Múltiples (ACM), debido al “one-hot enconding”, algunos ejes terminan siendo “parásitos”, en el sentido en que realmente no están aportando información.
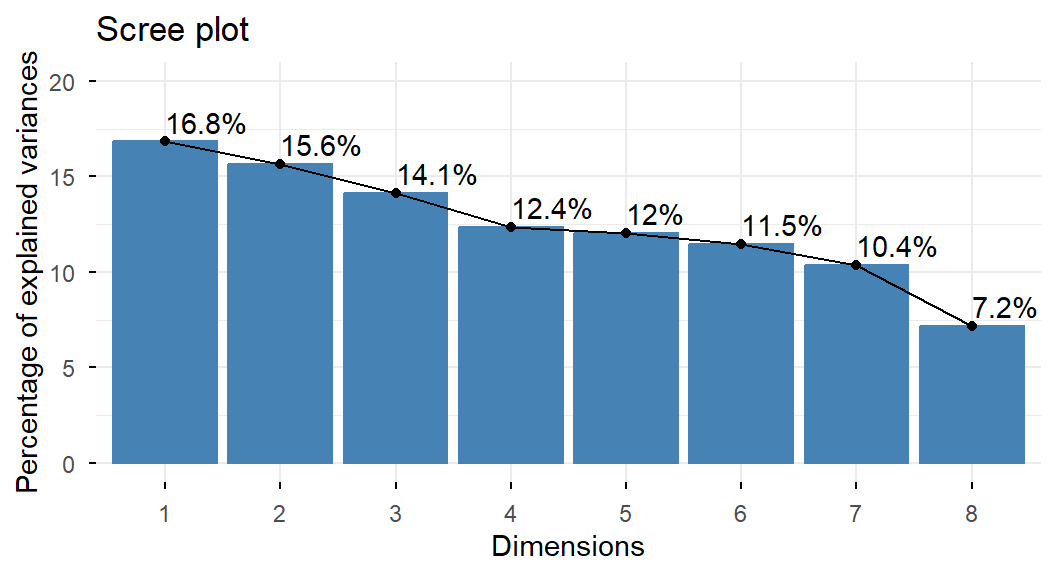
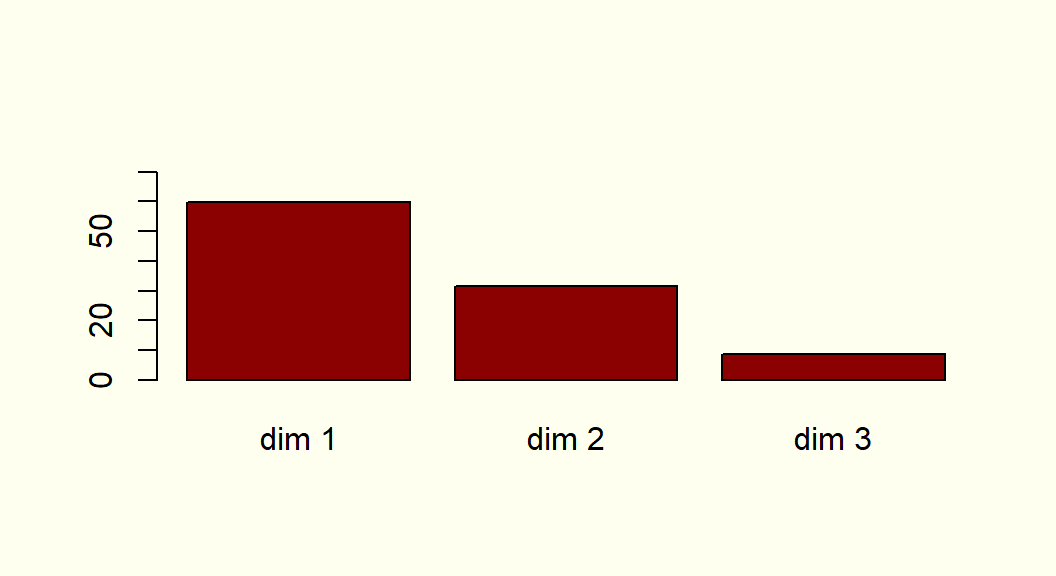
Por eso, tomar decisiones o sacar conclusiones basadas directamente en la inercia o en los porcentajes de inercia no resulta apropiado en este tipo de análisis.
Mientras que en el Análisis de Componentes Principales (ACP) la inercia se interpreta como una medida de dispersión tanto para la nube de individuos como para la nube de variables, en el ACM, la inercia depende exclusivamente de la relación entre el número de categorías y el número de variables: Inercia = \left( \tfrac{p}{s} - 1\right).
Esto quiere decir que no depende de los datos internos de la tabla y, por lo tanto, no ofrece información valiosa que pueda interpretarse directamente sobre los mismos.
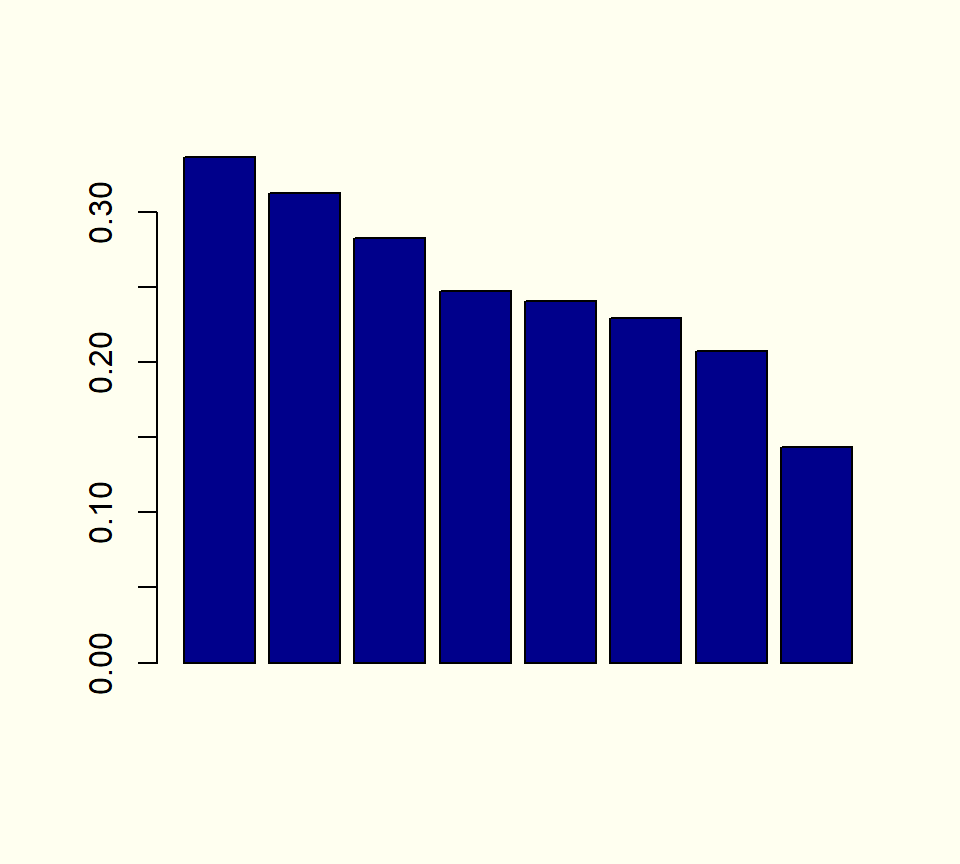
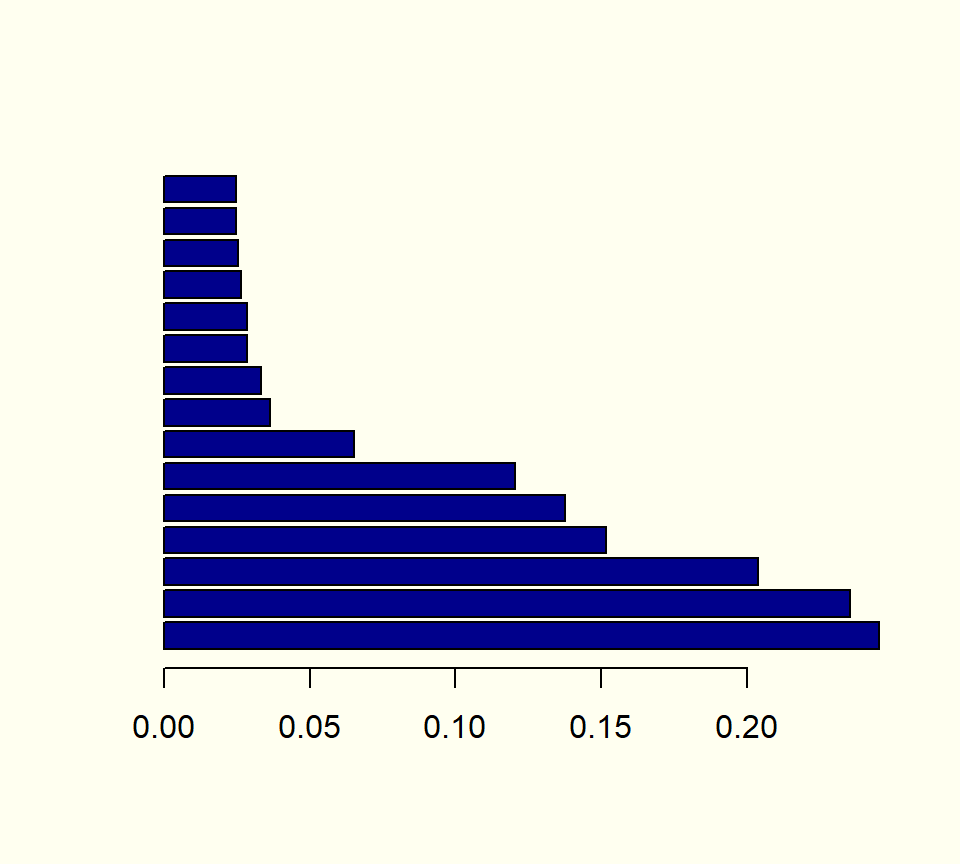
Para abordar esta limitación, Benzécri propuso considerar únicamente los ejes asociados a valores propios mayores que el inverso multiplicativo del número de variables.
Además, recomendó recalcular las tasas de inercia utilizando la siguiente fórmula:
\tau(\lambda) = \left(\tfrac{s}{s-1}\right)^2 \left(\lambda-\tfrac{1}{s}\right)^2 para \lambda > \tfrac{1}{s}
## Usando modif.rate() del paquete GDAtools:# ptau <- modif.rate(acm)$modif[, 1]## Haciendo las cuentas sin usar paquetes:s<-ncol(Y)l<-acm$eig[acm$eig[,1]>1/s, 1]tau<-(s/(s-1))^2*(l-(1/s))^2ptau<-tau/sum(tau)*100barplot(ptau, col="darkred", ylim =c(0,75))
En el Análisis de Correspondencias Múltiples (ACM), las ayudas numéricas para las interpretaciones son básicamente las mismas que en el Análisis de Componentes Principales (ACP) y en el Análisis de Correspondencias Simples (ACS).
No olvide consultar la ayudas numéricas (incluso antes de escoger qué gráficos va a producir), especialmente los valores test para identificar cuándo las diferencias SON o NO SON significativas con respeto al centro de gravedad.
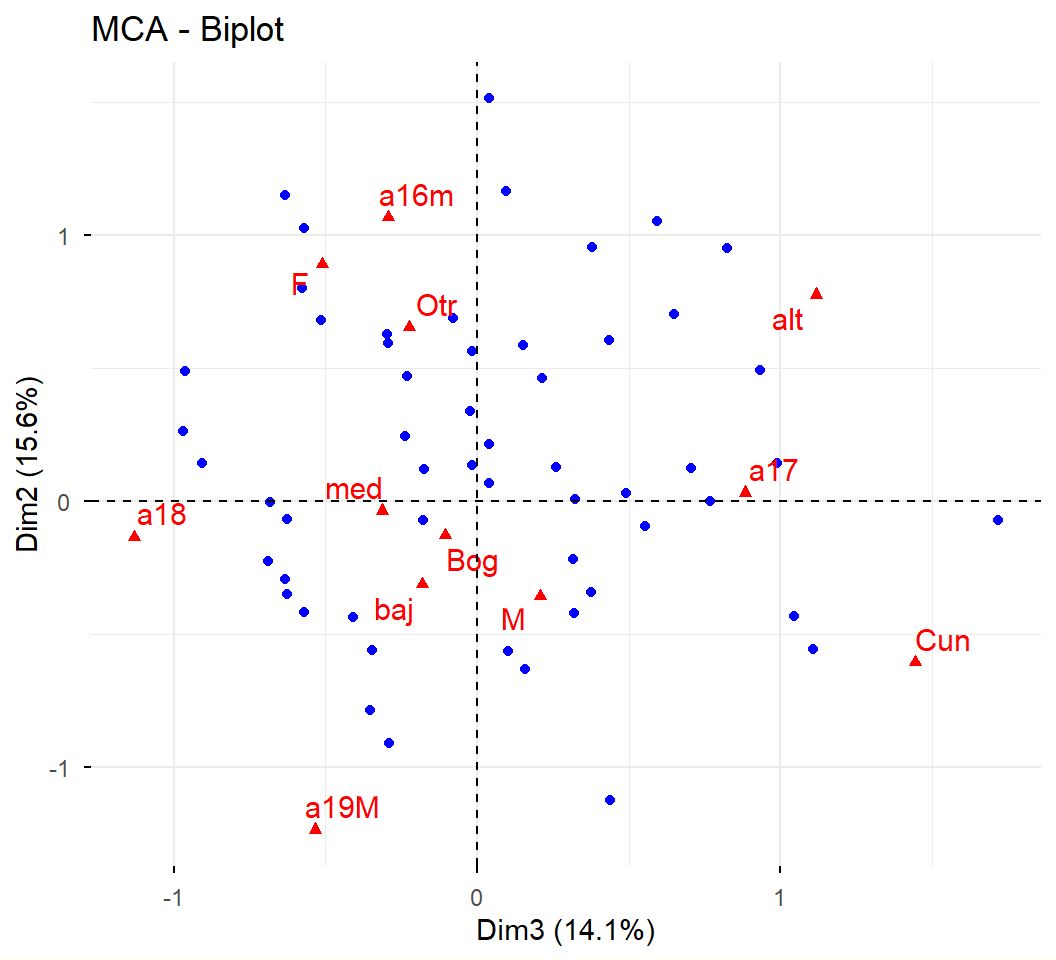
## ¿Parece que no está funcionando correctamente para otros ejes?:# fviz_mca_var(acm, axes = c(3,2),# choice = "mca.cor", repel = TRUE, # ggtheme = theme_minimal())## Haciendo el gráfico sin uso de librerías adicionales:# plot(acm$var$eta2[,c(3,2)], col="red", pch=17,# bty="n", xlim = c(0,0.7), ylim = c(0,0.7))# text(acm$var$eta2[,c(3,2)], col="red", pos = 1,# labels = rownames(acm$var$eta2))## Haciendo el gráfico con ggplot:# ggplot(data = acm$var$eta2, aes(x = `Dim 3`, y = `Dim 2`)) +# geom_point(colour = "red") + xlim(0,0.7) + ylim(0,0.7) + # geom_text(label=rownames(acm$var$eta2), colour = "red", hjust=1) + # theme_minimal()## Parece estar funcionando bien para los ejes 1 y 2:fviz_mca_var(acm, axes =c(1,2), choice ="mca.cor", repel =TRUE, ggtheme =theme_minimal())
Al igual que en el Análisis de Componentes Principales (ACP) y en el Análisis de Correspondencias Simples (ACS), en el Análisis de Correspondencias Múltiples (ACM) es posible proyectar individuos, variables cualitativas y variables continuas suplementarios, tratándolos como elementos ilustrativos en el espacio de componentes factoriales.
Consumo cultural (ver la Sección 6.5. del libro Estadística Descriptiva Multivariada del Profesor Campo Elías Pardo):
Se presenta un ejemplo de análisis parcial de la Encuesta de Consumo Cultural del Dane (2014). La encuesta aplica un formulario a una subpoblación de niños de 5 a 11 años, sobre consumo cultural. Se adicionan algunas variables sociodemográficas de los módulos de hogares y viviendas. Para este análisis, se seleccionan los niños que tienen edades entre 8 y 11 años y que saben leer.
Objetivos del análisis
Describir el consumo cultural de niños entre 8 y 11 años, que saben leer y explorar su relación con algunas variables sociodemográficas.
Código
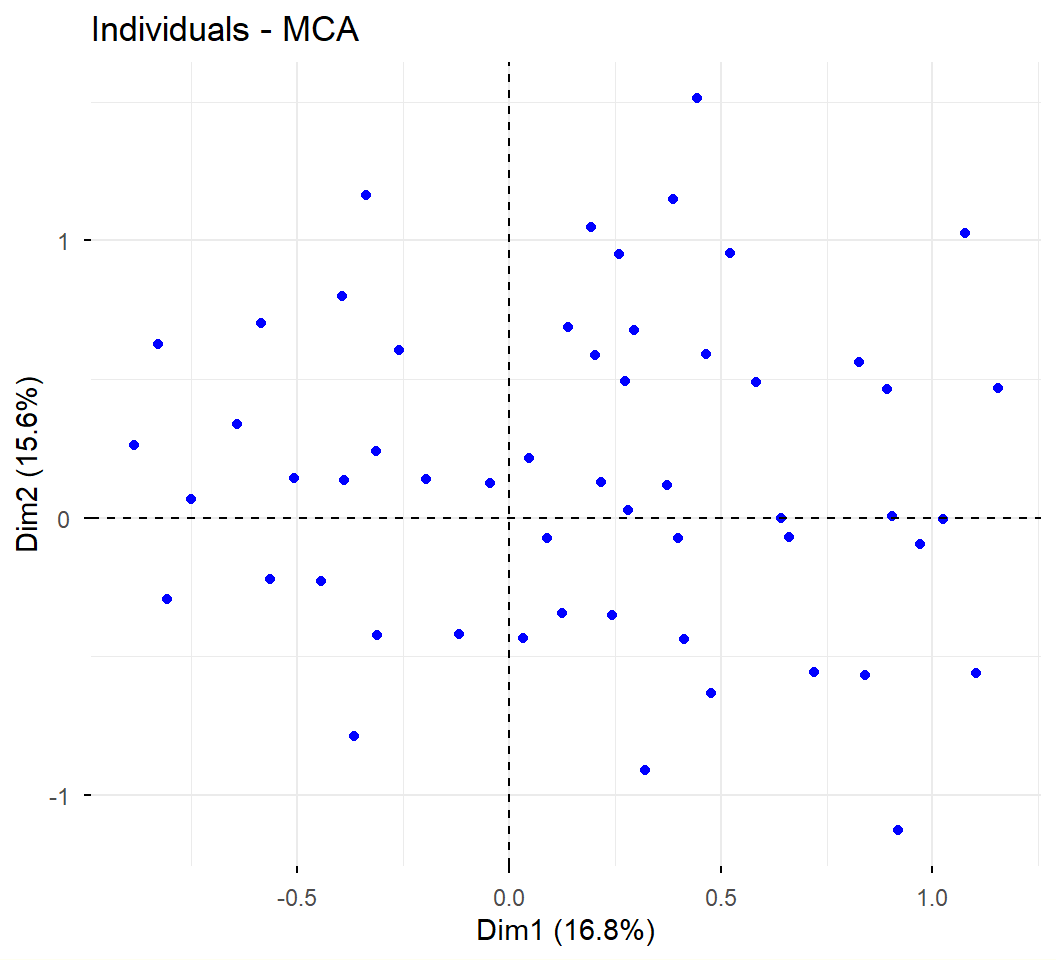
# cargar datos de archivo .Rda:load("./ruta/ninios8a11.Rda")# cambia variable a tipo factor # (también elimina categorías con 0 individuos):ninios8a11$Edad<-factor(ninios8a11$Edad)# variables activas: Teat, Libr, Cine, Vide, Radi, MusiY<-ninios8a11[, c("Teat","Libr","Cine","Vide","Radi","Musi")]# variables suplementarias: Ys<-ninios8a11[, c("Pare","Sexo","Edad","Regi","Estr")]# ACM con Factoshinyif(!require(Factoshiny)){install.packages("Factoshiny"); library(Factoshiny)}res<-MCAshiny(cbind(Y,Ys))
7.5.5 Ampliar o complementar
El contenido de esta subsección (Análisis de componentes principales generalizado) se puede ampliar o complementar con lo que se encuentra en:
Tutorial on Correspondence Analysis with R (Factoshiny & FactoMineR) (François Husson - Feb 27, 2020 - 13:33)
El objetivo de estos métodos es descubrir patrones en los datos, en forma de grupos bien diferenciados, que tengan individuos homogéneos en su interior.
En las áreas de minería de datos, aprendizaje automático y reconocimiento de patrones, estos métodos hacen parte de lo que se denominaría como aprendizaje no supervisado (unsupervised learning).
En la literatura francesa de análisis de datos (d’analyse des données) se los denomina métodos de clasificación (techniques de classification), mencionando que son no supervisados (non supervisé) cuando se necesita la aclaración. Por otro lado, Partitionnement de données, en francés, sería un término similar o equivalente a data clustering en inglés.
En el sentido matemático, un algoritmo de agrupamiento busca una partición de un conjunto de elementos (los individuos) en subconjuntos (grupos). Esto es equivalente a asignarle una categoría a cada individuo (una etiqueta que indica el subconjunto o grupo al que pertenece), y por lo tanto es como obtener una nueva variable cualitativa a partir de los datos.
Existen una gran cantidad de métodos de agrupamiento y diferentes tipos de ellos. En esta subsección nos concentraremos, primero, en un método que obtiene los grupos a partir de una sucesión de particiones (agrupamiento jerárquico), y luego, en un método que obtiene los grupos a partir de la cantidad de grupos deseados, unos puntos iniciales y un criterio de parada (agrupamiento directo).
Los algoritmos de agrupamiento suelen necesitar medidas de similitud, disimilitud o distancia entre individuos y entre grupos. Existen varias medidas de similitud, disimilitud y distancia entre individuos, dependiendo del tipo de variable y del contexto de aplicación.
7.6.1 Agrupamiento jerárquico (Ward)
7.6.1.1 Agrupamiento jerárquico aglomerativo
Un procedimiento de agrupamiento jerárquico aglomerativo procede de la siguiente manera:
Seleccionar una medida de disimilitud (o distancia) entre individuos, y seleccionar un criterio de agregación o medida de disimilitud (o distancia) entre grupos.
Calcular las disimilitudes (o distancias) entre los n individuos.
Unir los dos individuos menos disimiles, obteniendo n - 1 grupos.
Calcular las disimilitudes entre el nuevo grupo y los demás individuos (se pueden considerar grupos de un solo individuo).
Unir los dos grupos menos disimiles, obteniendo n - 2 grupos.
Continuar calculando las disimilitudes entre el nuevo grupo y los demás grupos, para luego, unir los dos grupos menos disimiles, hasta que obtenga un solo grupo con todos los individuos.
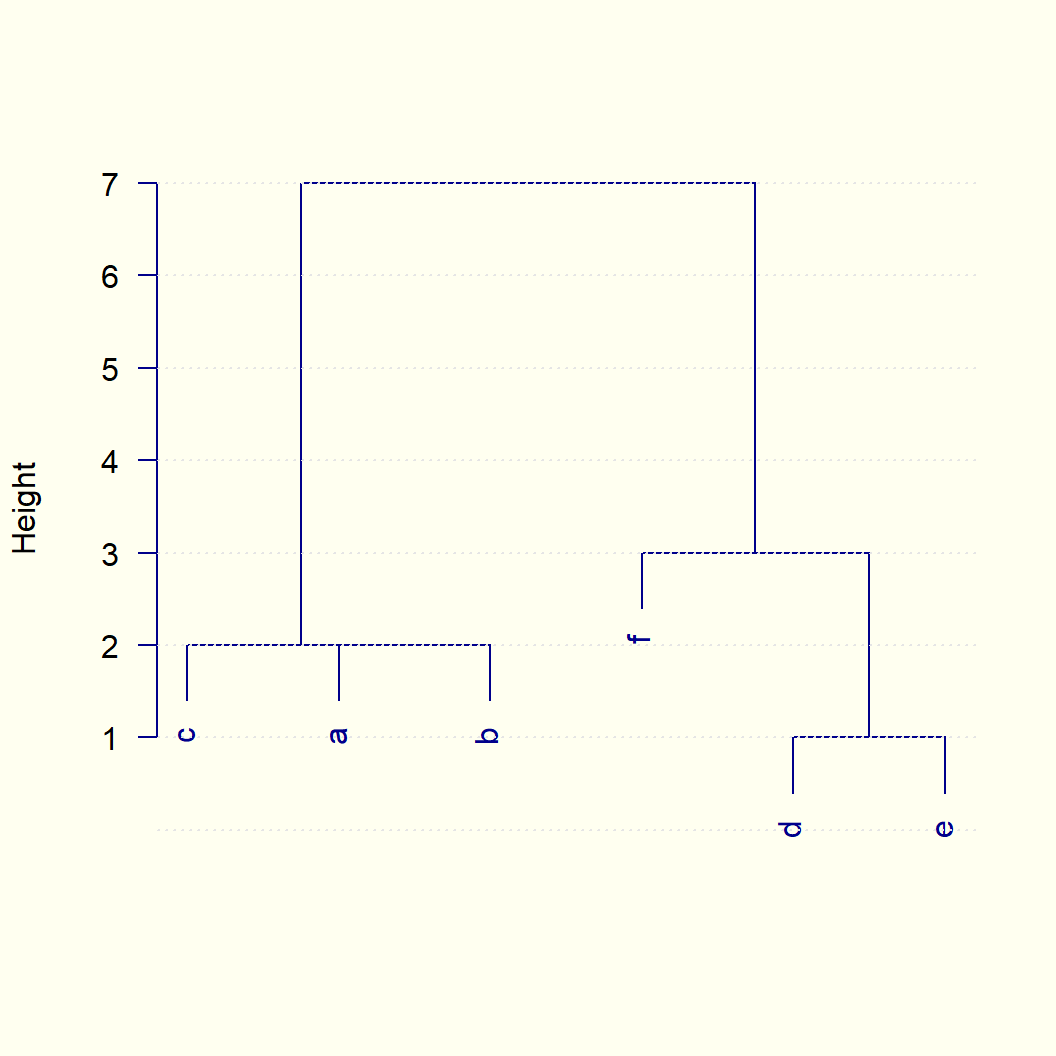
El proceso de uniones se representa por medio de un gráfico llamado Dendrograma.
Ilustremos con la distancia de Manhattan y el enlace completo:
| a | b | c | d | e
-------------------
b | 2 |
c | 2 | 2
d | 7 | 7 | 7
e | 7 | 7 | 7 | 1
f | 7 | 7 | 7 | 3 | 3
Criterio de agregación de Ward:
Para lograr grupos que tengan inercia “dentro-grupos” / “intra-grupos” mínima se debe utilizar una distancia euclidiana y unir en cada paso del procedimiento los dos grupos que menos aumenten la inercia dentro-grupos. Al incremento de inercia dentro-grupos al unir dos grupos lo llamaremos distancia de Ward entre esos dos grupos y la notaremos W(,). Entonces, al tener tres grupos A, B y C, es necesario calcular W(A, B), W(A, C) y W(B, C) y el menor valor determinará los grupos a unir.
¿Que defectos, problemas o debilidades tendrá el anterior método de agrupamiento (aglomerativo de Ward) y en general los métodos de agrupamiento jerárquico?
7.6.2 Agrupamiento directo (K-means)
En este caso, los métodos suelen requerir: la cantidad de grupos a obtener, valores iniciales para poder empezar y un criterio de parada para poder detenerse.
Uno de los métodos más sencillo y más conocido de agrupamiento directo (basado en particiones y basado en centroides) es el de K-means.
Tomado de: Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern recognition letters, 31(8), 651-666.
Método K-means:
Está relacionado con la geometría utilizada en los métodos factoriales porque recurre a la distancia euclidiana entre individuos.
La distancia entre grupos se calcula como la distancia euclidiana entre sus respectivos centros de gravedad (puntos promedio).
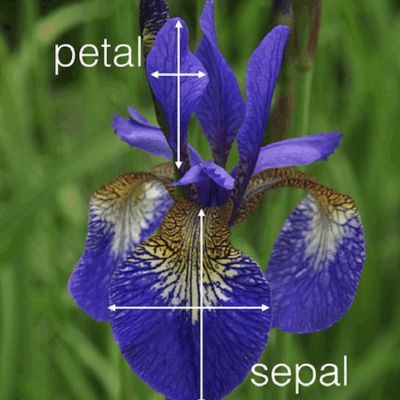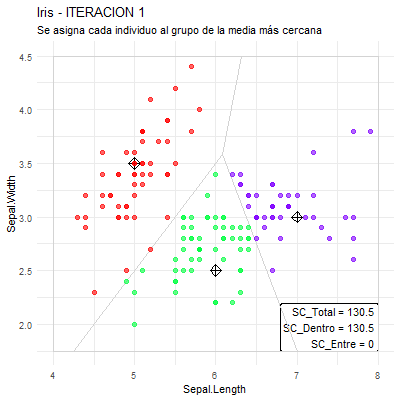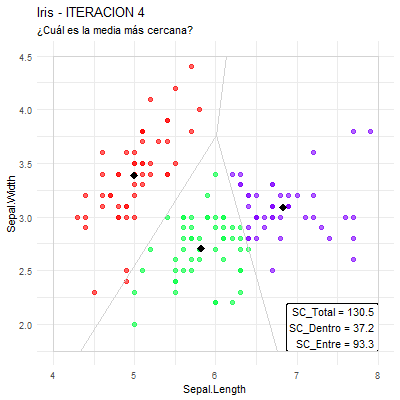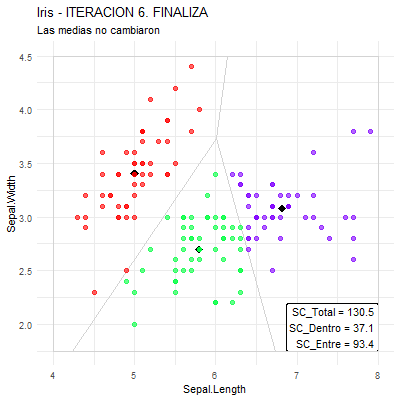
El método K-means busca una partición en K grupos que tenga inercia dentro-grupos mínima, es decir, lo que hace es minimizar las distancias euclidianas al cuadrado entre los individuos y el centro de gravedad del grupo al que pertenecen.
Además, el minimizar esta inercia dentro-grupos coincide con el buscar que los individuos de cada grupo sean lo más “parecidos” entre sí que se pueda (individuos homogéneos dentro de cada grupo).
Por otro lado, como inercia (total) = inercia dentro-grupos + inercia entre-grupos, entonces, también se está buscando que los individuos de grupos distintos sean lo más “diferentes” que se pueda (individuos heterogéneos entre grupos distintos).
Algoritmo K-means (Algoritmo de Lloyd/Forgy)
ENTRADA: Tabla de datos de variables cuantitativas y la cantidad de grupos a obtener (K).
Pedir como entrada o seleccionar K puntos (“centros de gravedad”) iniciales.
Repetir:
Asignar a cada individuo el grupo cuyo centro de gravedad sea el más cercano.
Calcular los nuevos centros de gravedad de cada grupo.
Hasta que: los centros de gravedad no cambien.
SALIDA: Conformación de los grupos (asociación individuo-grupo).
Ventajas del K-means:
Es muy rápido. Usualmente converge en pocas iteraciones.
Poco exigente en recursos computacionales. Por ejemplo, no requiere calcular distancias entre todos los individuos, basta con calcular las distancias de los individuos a los centros de gravedad de los grupos. Como K suele ser mucho menor a n, la cantidad de distancias a calcular es menor.
Desventajas del K-means:
Se debe suministrar la cantidad de grupos a obtener. De alguna manera se debe determinar el número de grupos más adecuado para el conjunto de datos.
El resultado obtenido por el algoritmo depende de los puntos (“centros de gravedad”) iniciales dados. No hay garantía de que la inercia dentro-grupos alcanzada sea un mínimo global, incluso podría estar bastante lejos de serlo.
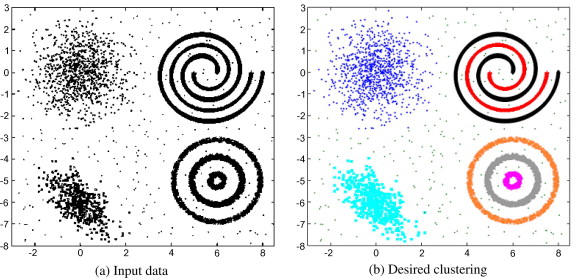
El método solamente es capaz de identificar adecuadamente grupos de individuos cuando estos se encuentran en regiones separables por “puntos equidistantes” con respecto a los centros de gravedad.
Código
# Cargar librerías necesariasif(!require(plotly)){install.packages("plotly"); library(plotly)}# Cargar los datosdata(admi)# Seleccionar las variables numéricas para el agrupamiento admi_data<-admi[, c(2,4,6)]# mate, soci, imag# Aplicar K-means por ejemplo para obtener 3 gruposset.seed(123)# fijar semilla para que sea reproduciblekmeans_result<-kmeans(admi_data, centers =3, nstart =5)# Agregar los resultados del agrupamiento a los datos originalesadmi_data$cluster<-as.factor(kmeans_result$cluster)# Crear gráfico 3D interactivo con Plotlyfig<-plot_ly(admi_data, x =~mate, y =~soci, z =~imag, color =~cluster, colors =c("darkgreen", "darkorange", "darkblue"), type ="scatter3d", mode ="markers")# Añadir títulos a los ejesfig<-fig%>%layout( scene =list( xaxis =list(title ="Matemáticas"), yaxis =list(title ="Sociales"), zaxis =list(title ="Imagen")), title ="Agrupamiento de admitidos a partir de mate, soci y imag")# Mostrar gráficofig
Los métodos de agrupamiento de Ward y de K-means son compatibles, ya que los dos buscan la más baja inercia dentro-grupos.
Además, estos dos métodos tienen ventajas y desventajas que se complementan.
La recomendación para combinar los métodos sería:
Cuando el número de elementos a agrupar no es tan grande, y los recursos computacionales que se tienen lo permiten, se realiza la agrupación jerárquica aglomerativa con la distancia de Ward. Si el número de elementos a clasificar es demasiado grande se puede utilizar el K-means para un pre-agrupamiento (miles de grupos), y luego realizar el agrupamiento jerárquico con los centros de gravedad del pre-agrupamiento.
A partir del Dendrograma, es posible escoger un corte del árbol que nos daría la cantidad de grupos potencialmente más adecuada.
Luego, con los centros de gravedad dados por el corte en el árbol, utilizar el K-means para disminuir, tanto como se pueda, la inercia dentro-grupos, y de esa manera lograr mejorar o consolidar la agrupación respectiva.
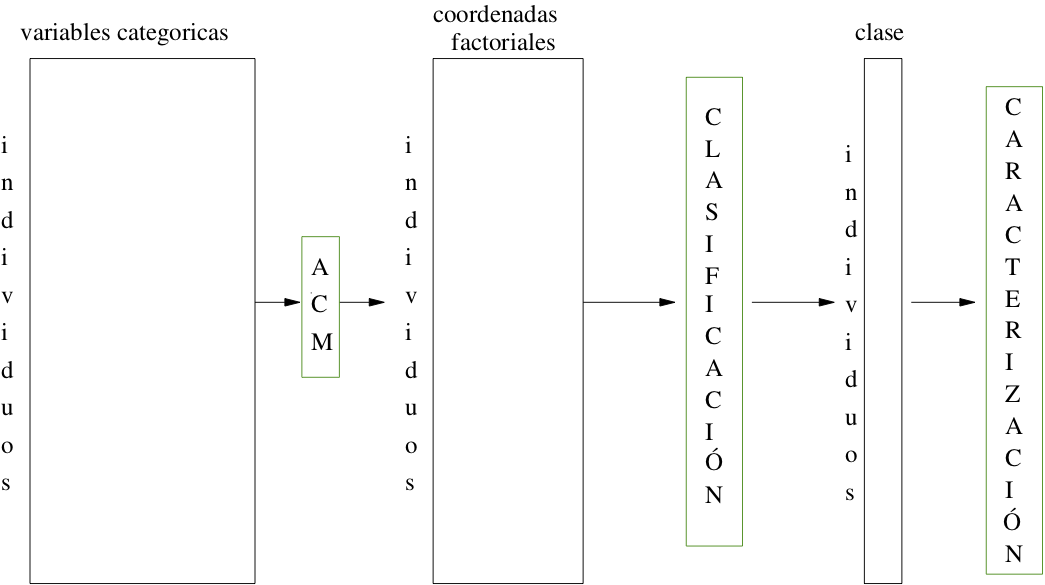
7.6.4 Agrupamiento a partir de ejes factoriales
Los métodos factoriales se pueden utilizar para transformar los datos antes de realizar procedimientos de agrupación. Estos métodos pueden cumplir dos funciones: reducir la dimensión de los datos y cuantificar las variables cualitativas. Por ejemplo:
7.6.5 Caracterización automática
Luego de obtener los grupos de individuos, es natural el querer identificar las características que distinguen a cada grupo, de los demás grupos, o del conjunto completo de individuos.
Como al agrupar se obtiene una nueva variable cualitativa a partir de los datos, esta nueva variable se puede contrastar con las demás mediante un análisis bivariado. En particular, se pueden utilizar los valores test:
Para una variable cuantitativa, los valores test son valores indicativos de que tan lejos, en desviaciones estándar, está la media de la variable cuantitativa para los individuos de un grupo, con respecto a la media general o global de la variable.
En el caso de una variable cualitativa, un valor test nos indica que tan diferente es la frecuencia de una categoría dentro de un grupo, con respecto a su frecuencia global.
Las variables cuantitativas o las categorías de las variables cualitativas con un valor test en magnitud superior a un umbral se dice que caracterizan al grupo.
7.6.6 Estrategia completa de agrupamiento
La estrategia completa de agrupamiento que se ha venido planteando, se resumiría en los siguientes pasos:
Realizar el análisis en ejes factoriales que corresponda.
Seleccionar el número de ejes factoriales para el agrupamiento.
Si el número de “individuos” es muy grande, realizar un K-means de pre-agrupamiento en miles de grupos.
Realizar el agrupamiento jerárquico con el método de Ward sobre los “individuos” o los grupos del paso anterior.
Decidir el número de grupos y cortar el árbol.
Realizar un K-means de consolidación, partiendo de los centros de gravedad de la partición obtenida al cortar el árbol.
Caracterizar los grupos.
Proyectar los grupos sobre los planos factoriales.
OPCIÓN FactoClass:
Para seguir la estrategia completa de agrupamiento planteada, se podría usar el paquete FactoClass.
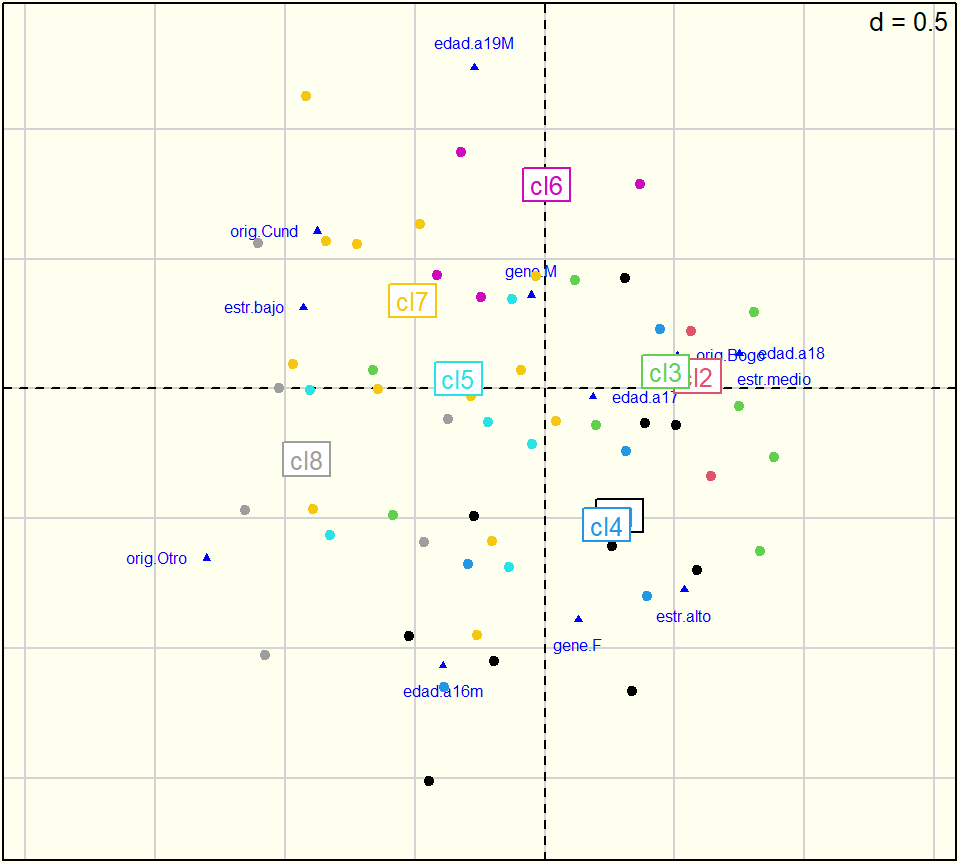
A continuación se procederá a realizar la agrupación de admitidos. Las variables activas serán género, edad, estrato y origen (cualitativas). Las variables ilustrativas serán los resultados del examen de admisión (continuas) y la carrera (cualitativa).
Para seguir la estrategia completa de agrupamiento planteada, se podría usar el paquete Factoshiny mediante los siguientes pasos:
Hacer el análisis factorial que corresponda.
En la anterior situación correspondía un ACM. Podríamos reproducir el trabajo anterior y sus resultados ahora con otro paquete, pero de pronto es más interesante, productivo y valioso trabajar ahora con otro conjunto de datos:
Adjetivos × colores
Una agencia de publicidad encarga un estudio sobre las asociaciones entre colores y adjetivos, para armonizar la publicidad de los productos con las imágenes que los compradores potenciales tienen de los colores (Ver la ayuda de los datos ?ColorAdjective y el taller de la Subsección 5.6.2. del libro Estadística Descriptiva Multivariada del Profesor Campo Elías Pardo).
Seleccionar la opción “Perform clustering after leaving CA app?”.
Indicar el número de ejes a conservar para el agrupamiento.
Dar clic en “Quit the app”.
Este último paso abre la aplicación web que tiene como título: “HCPC on the dataset”, que es la encargada específicamente de la parte del agrupamiento (la cual se realiza a partir de los resultados obtenidos en el análisis factorial del paso previo correspondiente).
7.6.7 Ampliar o complementar
El contenido de esta subsección (Métodos de agrupamiento) se puede ampliar o complementar con lo que se encuentra en:
Clustering with R (FactoMineR & Factoshiny) (François Husson - Mar 3, 2020 - 17:01)
El contenido de toda la sección se puede ampliar o complementar con lo que se encuentra en:
Husson, F., Lê, S., Pagès, J. (2017). Exploratory Multivariate Analysis by Example Using R. 2nd Edition. Chapman and Hall/CRC Press.
Lê, S., Josse, J. & Husson, F. (2008). FactoMineR: An R Package for Multivariate Analysis. Journal of Statistical Software. 25(1). pp. 1-18. http://factominer.free.fr/
Pagès, J. (2015). Multiple Factor Analysis by Example Using R. Chapman and Hall/CRC Press.
MFA - Multiple Factor Analyis with R (FactoMineR & Factoshiny) (François Husson - Mar 1, 2020 - 16:36)https://youtu.be/ffCM2RHccqk
Halford, M. Princehttps://github.com/MaxHalford/prince (No puedo dar cuenta de la calidad de este paquete. Sin embargo, parece ser que es el único en Python como alternativa a los mencionados de R: “Prince is a Python library for multivariate exploratory data analysis in Python. It includes a variety of methods for summarizing tabular data, including principal component analysis (PCA) and correspondence analysis (CA). Prince provides efficient implementations, using a scikit-learn API.”)