10 Redes neuronales artificiales
Fundamentos aplicados de redes neuronales artificiales y aprendizaje profundo
Neural networks https://youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
But what is a neural network? | Deep learning chapter 1 (3Blue1Brown - Oct 5, 2017 - 18:39) https://youtu.be/aircAruvnKk
Gradient descent, how neural networks learn | Deep Learning Chapter 2 (3Blue1Brown - Oct 16, 2017 - 20:33) https://youtu.be/IHZwWFHWa-w
Backpropagation, intuitively | Deep Learning Chapter 3 (3Blue1Brown - Nov 3, 2017 - 12:46) https://youtu.be/Ilg3gGewQ5U
Backpropagation calculus | Deep Learning Chapter 4 (3Blue1Brown - Nov 3, 2017 - 10:17) https://youtu.be/tIeHLnjs5U8
10.1 Introducción
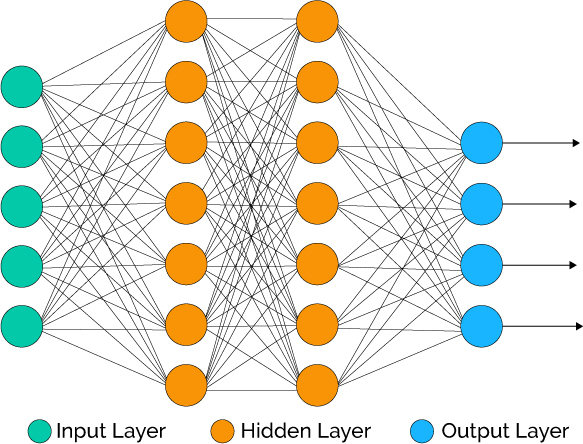
A visual representation of a neural network:
Las redes neuronales artificiales (artificial neural networks, ANN) son modelos computacionales para realizar tareas como reconocimiento de patrones, agrupamiento, clasificación o regresión, inspirados en elementos relacionados con la manera en que se cree podría llegar a ser el funcionamiento del cerebro humano.
10.1.1 Partes de una neurona biológica

Las células nerviosas típicas por ejemplo del cerebro humano se componen de cuatro partes:
- Función de la Dendrita. Recibe las señales de otras neuronas.
- Soma (cuerpo celular). Suma todas las señales entrantes para generar una señal total de entrada (input).
- Estructura del Axón. Cuando la suma sobrepasa un cierto umbral numérico, la neurona se activa, dispara y la señal viaja a través del axón hacia otras neuronas.
- Trabajo de la Sinapsis. Es el punto donde se realiza la interconexión de una neurona con otras neuronas. La cantidad de la señal transmitida depende en la fuerza (peso sináptico) de las conexiones. Las conexiones pueden ser inhibidoras (disminuyendo la fuerza) o de excitación (aumentando la fuerza) en principio.
Así pues, una Red Neuronal sería, en general una red altamente interconectada de billones de neuronas con trillones de interconexiones entre ellas.
10.1.2 Neuronas y redes neuronales artificiales
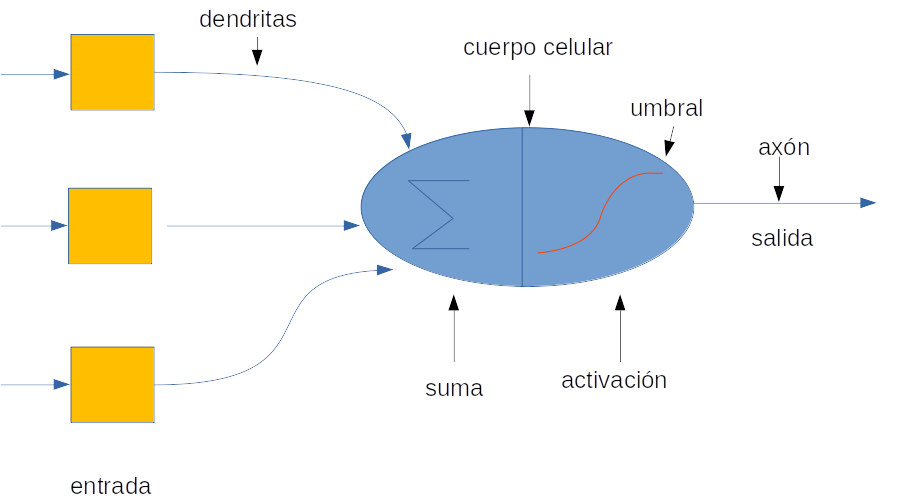
Las redes neuronales artificiales están compuestas por unidades básicas llamadas neuronas, organizadas en capas interconectadas que transforman entradas en salidas mediante operaciones matemáticas.
Las dendritas en las Redes Neuronales Biológicas son un análogo a las entradas conteniendo un peso específico basada en la interconexión “sináptica” presente en la Red Neuronal Artificial.
El cuerpo celular es comparable a la unidad artificial llamada “neurona” en una Red Neuronal Artificial, que también comprende la suma de señales y umbral de activación.
La salida de los Axones (presentes en la sinapsis) son el análogo de los datos de salida en la Red Neuronal Artificial.
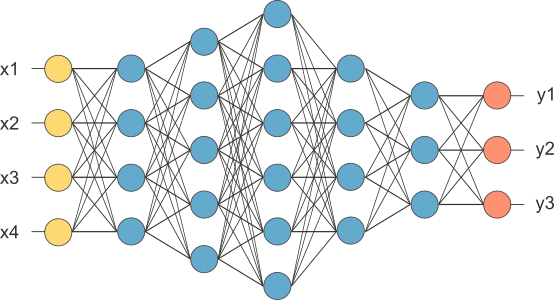
La capacidad de las redes de neuronas artificiales para modelar relaciones complejas en los datos las convierte en herramientas fundamentales en el contexto del aprendizaje automático (machine learning, ML).
10.1.3 ¿Cómo funciona una red neuronal artificial?
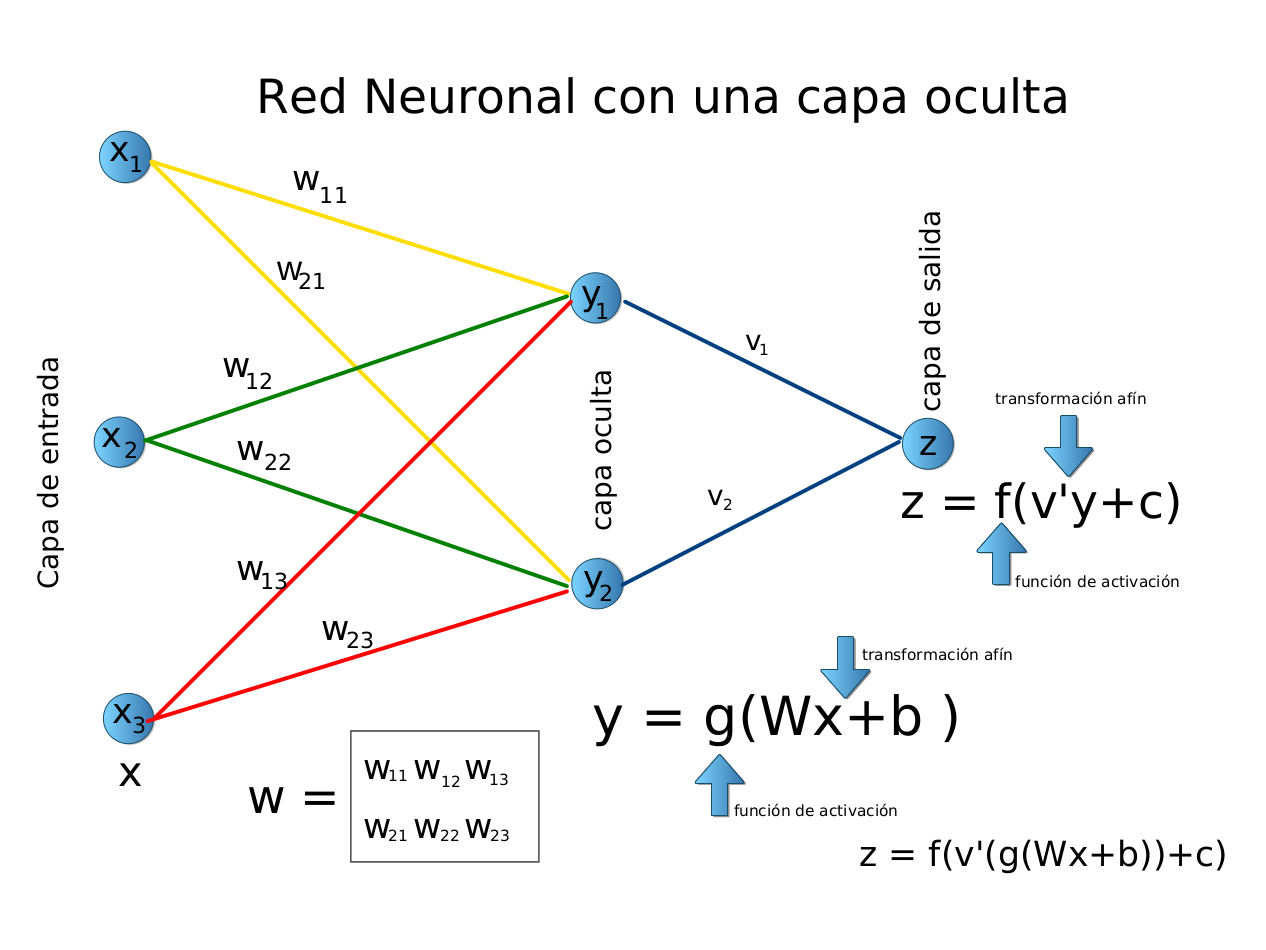
La red neuronal artificial recibe información del mundo externo en forma de vector, digamos x=(x_1,\ldots,x_n)^t.
En este caso, la capa de entrada posee 3 neuronas artificiales.
Cada componente x_i de la entrada se multiplica por el peso correspondiente w_{i}.
Los pesos son la información utilizada por la red neuronal para resolver un problema específico.
Estos pesos deben aprenderse (ajustarse / estimarse) en el paso de entrenamiento.
Los pesos representan el conocimiento que tiene la red sobre el problema en cuestión.
Usando la metáfora biológica, los pesos representan la fuerza de la interconexión entre las neuronas dentro de la red neuronal.
Las entradas y los pesos se combinan y se resumen dentro de la unidad de computación (neurona artificial), y se agrega un “sesgo” (intercepto / bias), como muestra la figura arriba.
La suma es un número real: z = \sum_i x_iw_i + b, z \in\mathbb{R}.
Esta suma se transforma a través de una función de activación, digamos g(\cdot), para obtener la salida neta x^* = g(z).
10.2 Perceptrón multicapa
Deep playground. Play with neural networks:
El modelo más básico de red neuronal es el perceptrón (perceptron).
Un perceptrón consiste en una o más entradas (input), una función que calcula una combinación lineal de las entradas y una función de activación básica (una función escalón, step function) que transforma los valores en la salida (output).
- El perceptrón, bajo su definición original, permitía realizar tareas de clasificación linealmente separable, pero era limitado para problemas más complejos.
Un perceptron multicapa (multilayer perceptron, MLP) extiende el perceptrón original, añadiendo capas ocultas con múltiples neuronas y otras funciones de activación (como sigmoide o ReLU), permitiendo representar relaciones no lineales.
Un modelo de regresión lineal múltiple y un perceptrón sin capas ocultas con función de activación lineal son matemáticamente equivalentes. Ambos modelos calculan una combinación lineal de las variables explicativas, donde los coeficientes estimados en la regresión corresponden a los pesos del perceptrón y el intercepto equivale al sesgo (bias).
En este escenario, la única diferencia es terminológica y de contexto de aplicación, ya que el procedimiento matemático subyacente es el mismo.
Cuando el perceptrón simple incorpora una función de activación no lineal en la salida, deja de ser equivalente a la regresión lineal múltiple.
Por ejemplo, si se emplea la función sigmoide, el modelo pasa a ser análogo a una regresión logística, mientras que otras funciones de activación producen variantes relacionadas con modelos de clasificación no lineales.
En este caso, la capacidad del modelo ya no se limita a relaciones estrictamente lineales, sino que puede abordar problemas de decisión con fronteras no lineales.
En el caso de un perceptrón multicapa con varias capas ocultas, si todas las funciones de activación son lineales, la red sigue siendo en esencia una transformación lineal de las entradas.
Esto se debe a que la composición de funciones lineales produce otra función lineal, por lo que el modelo resultante no supera en capacidad expresiva a la regresión lineal múltiple.
La diferencia radica únicamente en la representación: los parámetros se distribuyen en varias matrices de pesos en lugar de concentrarse en un único vector de coeficientes, pero el resultado final describe la misma clase de funciones.
Solo cuando el perceptrón multicapa incorpora funciones de activación no lineales en las capas ocultas se obtiene un modelo con mayor poder de representación.
En ese caso, la red deja de ser equivalente a la regresión lineal y adquiere la capacidad de capturar relaciones complejas y no lineales en los datos.
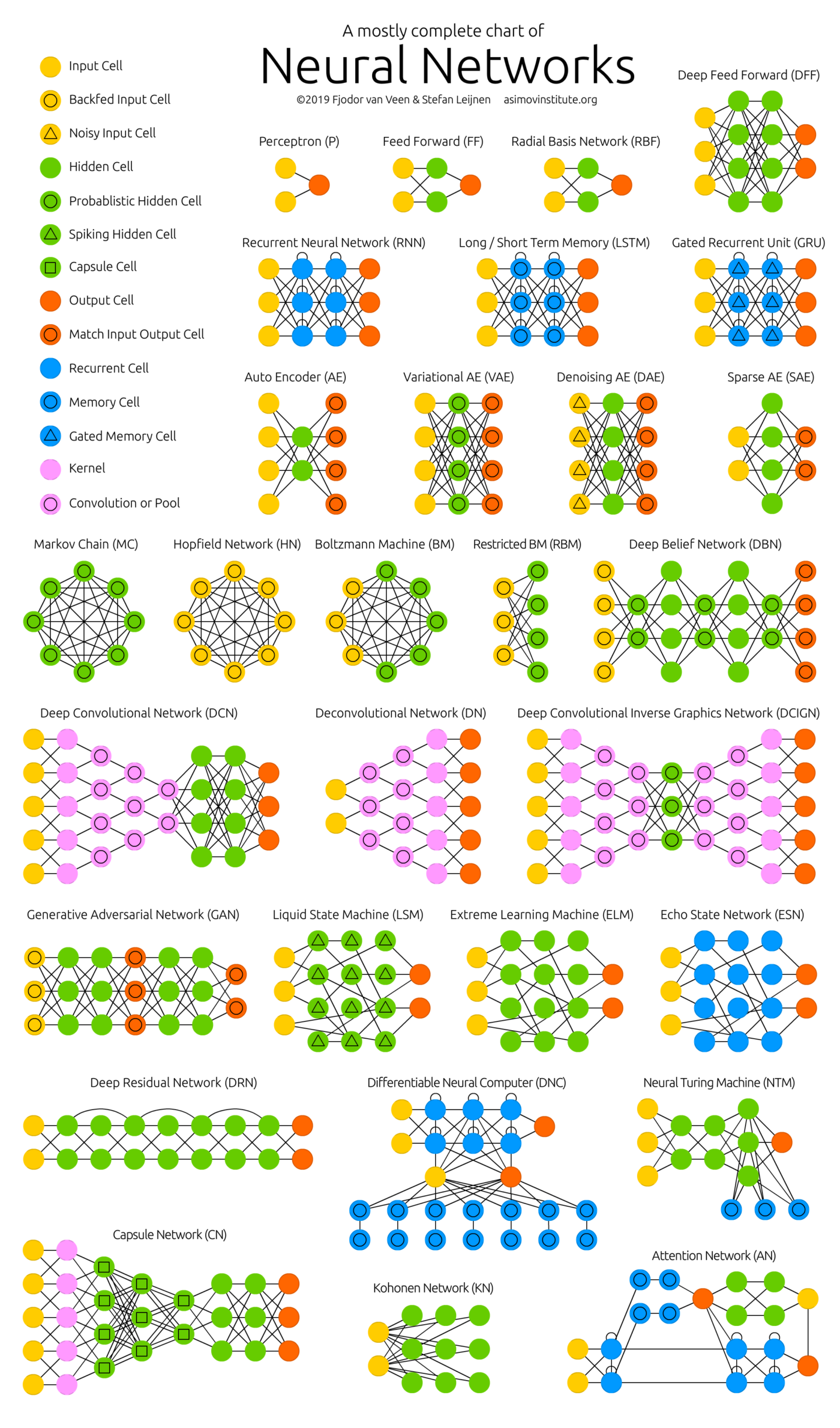
Los MLP constituyen la base conceptual del denominado aprendizaje profundo (Deep Learning) y de arquitecturas de modelos de redes neuronales más avanzados como por ejemplo:
- Redes Neuronales Convolucionales (Convolutional Neural Networks, CNNs)
- Redes Neuronales Recurrentes (Recurrent Neural Networks, RNNs)
- Redes LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Units)
- Redes Generativas Antagónicas o Adversarias (Generative Adversarial Networks, GANs)
- Modelos Autoencoders
- Modelos basados en mecanismos de atención, como los Transformers
En esta parte, nos enfocaremos exclusivamente en el perceptrón multicapa, abordando los fundamentos esenciales para comprender el funcionamiento de estas redes y su aplicación en tareas de clasificación y regresión.
Cuadernos computacionales:
10.3 Introducción al lenguaje natural
Minicurso de inteligencia artificial y aprendizaje profundo
Día 4: Introducción al lenguaje natural (Aprendizaje Profundo - Mar 16, 2023 - 2:02:13) https://www.youtube.com/live/zJBIe0QSZjM
Neural networks
Large Language Models explained briefly (3Blue1Brown - Nov 20, 2024 - 7:57) https://youtu.be/LPZh9BOjkQs
Transformers, the tech behind LLMs | Deep Learning Chapter 5 (3Blue1Brown - Apr 1, 2024 - 27:13) https://youtu.be/wjZofJX0v4M
Attention in transformers, step-by-step | Deep Learning Chapter 6 (3Blue1Brown - Apr 7, 2024 - 26:09) https://youtu.be/eMlx5fFNoYc
How might LLMs store facts | Deep Learning Chapter 7 (3Blue1Brown - Aug 31, 2024 - 22:42) https://youtu.be/9-Jl0dxWQs8
10.4 Introducción a visión por computador
Minicurso de inteligencia artificial y aprendizaje profundo
Día 3: Introducción a visión por computador (Aprendizaje Profundo - Mar 15, 2023 - 2:02:03) https://www.youtube.com/live/qDMFYuJo8tI
Neural networks
But how do AI images and videos actually work? | Guest video by Welch Labs (3Blue1Brown - Jul 25, 2025 - 37:19) https://youtu.be/iv-5mZ_9CPY
10.5 Ampliar o complementar
Scikit-learn: Machine Learning in Python, 1.17. Neural network models (supervised) https://scikit-learn.org/stable/modules/neural_networks_supervised.html
TensorFlow Learn https://www.tensorflow.org/learn
PyTorch Tutorials - Intro https://docs.pytorch.org/tutorials/intro.html