De posición (cuantiles)
¿Cómo podría responder preguntas como esta o similares, usando los datos que se tienen (por ejemplo, de los puntajes en el examen)?: Si se decide proporcionar apoyo adicional al 25% de los estudiantes con los puntajes más bajos, ¿cuál sería el puntaje de corte para proporcionar o no ese apoyo?
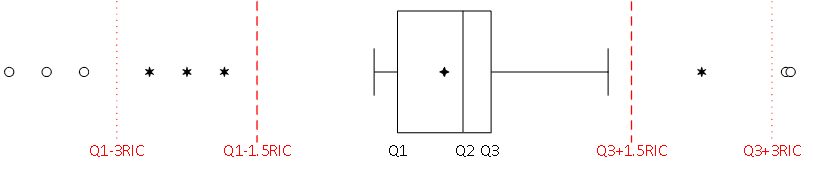
Por ejemplo, el cuantil 0.12 es el valor para la variable, que marca un corte de tal manera que el 12\% de los valores que se tienen de la variable son menores o iguales al valor del cuantil, y el 88\% restante de los valores de la variable son mayores o iguales al valor del cuantil.
Existen una serie de cuantiles importantes o de uso más frecuente:
Cuartiles: Dividen los datos en cuatro partes iguales. Corresponden a los cuantiles 0.25 (Q_1), 0.50 (Q_2) y 0.75 (Q_3).
Quintiles: Dividen los datos en cinco partes iguales
Deciles: Dividen los datos en diez partes iguales
Percentiles: Dividen los datos en cien partes iguales. Corresponden a los cuantiles 0.01, 0.02, …, 0.98 y 0.99
¿Cómo calcular?:
En Hyndman, R. J., & Fan, Y. (1996). Sample quantiles in statistical packages. The American Statistician, 50(4), 361-365. hacen una revisión y comparación de nueve (9) alternativas de cálculo para los cuantiles (desde la teoría, cada una tiene sus ventajas y desventajas).
“Alternativa 7” es la que usan en:
- En Excel, desde Office 2013 es la función
PERCENTILE.INC (antes era la función PERCENTILE).
- En R, Es la opción predeterminada de la función
quantile, pero se puede seleccionar cualquiera de las nueve del artículo mencionado (cambiando el valor para el parámetro type).
Para la variable examen, se tiene que:
De dispersión
Las medidas descriptivas de dispersión deben poder darnos una idea acerca de que tan concentrados o no están los valores de una variable.
Hay varias opciones, en cada caso identifique en qué unidades estaría la medida y que potenciales ventajas y desventajas podría tener.
Rango (R): Diferencia entre el máximo y el mínimo valor de la variable.
Rango intercuartílico (RIC): Diferencia entre el tercer cuartil y el primer cuartil. Magnitud en la cual oscilan el 50\% de los valores centrales que toma la variable.
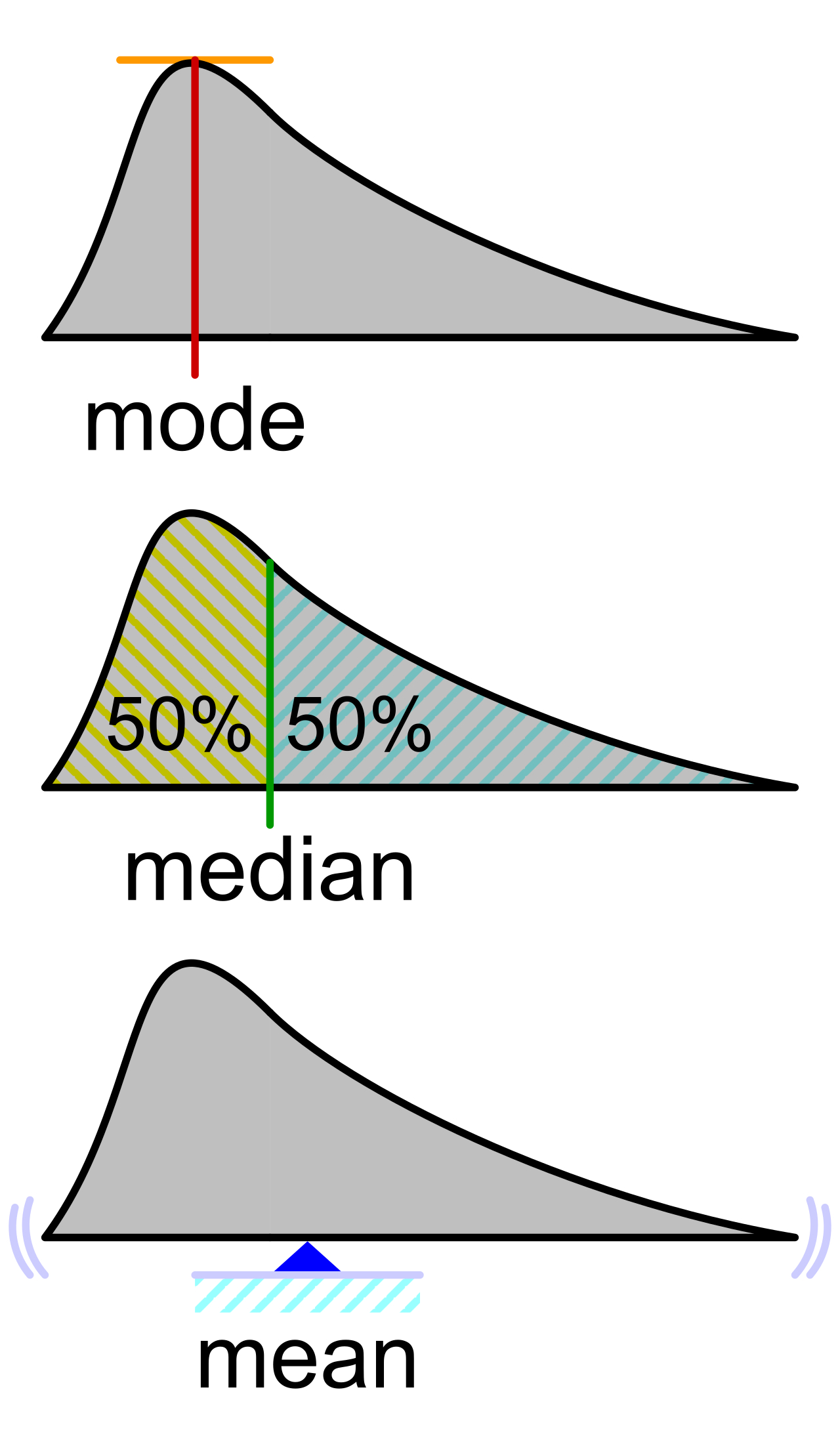
Varianza poblacional (\sigma^2): Promedio de los cuadrados de las distancias entre cada valor y el promedio.
Desviación estándar poblacional (\sigma): Raíz cuadrada de la varianza.
Pero, ¿qué podría representar la varianza y la desviación estándar?
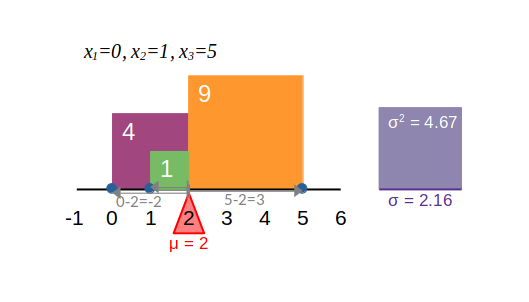
\begin{aligned}
\sigma^2 &= \frac{(0 - 2)^2 + (1 - 2)^2 + (5 - 2)^2}{3} = 4.6667 \\
\sigma^2 &= \frac{(x_1 - \mu)^2 + (x_2 - \mu)^2 + \dots + (x_N - \mu)^2}{N}
\end{aligned}
Coeficiente de variación:
Es el resultado de tomar la desviación estándar y dividirla por media (con signo positivo, en caso de que la media sea negativa).
El coeficiente de variación da una idea de variabilidad relativa. Es una cantidad que no tiene asociada alguna unidad (se cancelan las unidades del numerador con las del denominador). Frecuentemente se da o se interpreta como un porcentaje (es un cociente o una razón en donde el numerador no es parte del denominador para que pueda ser considerada como una proporción, y que al multiplicarla por cien se pueda interpretar como un porcentaje). Es útil para comparar la dispersión de dos o más variables.
¿Cuál variable tiene mayor variabilidad (mayor dispersión, menor concentración) entre puntaje en el examen y edad?