En esta sección se hará una revisión de algunos temas relacionados con modelos/distribuciones de variables aleatorias continuas.
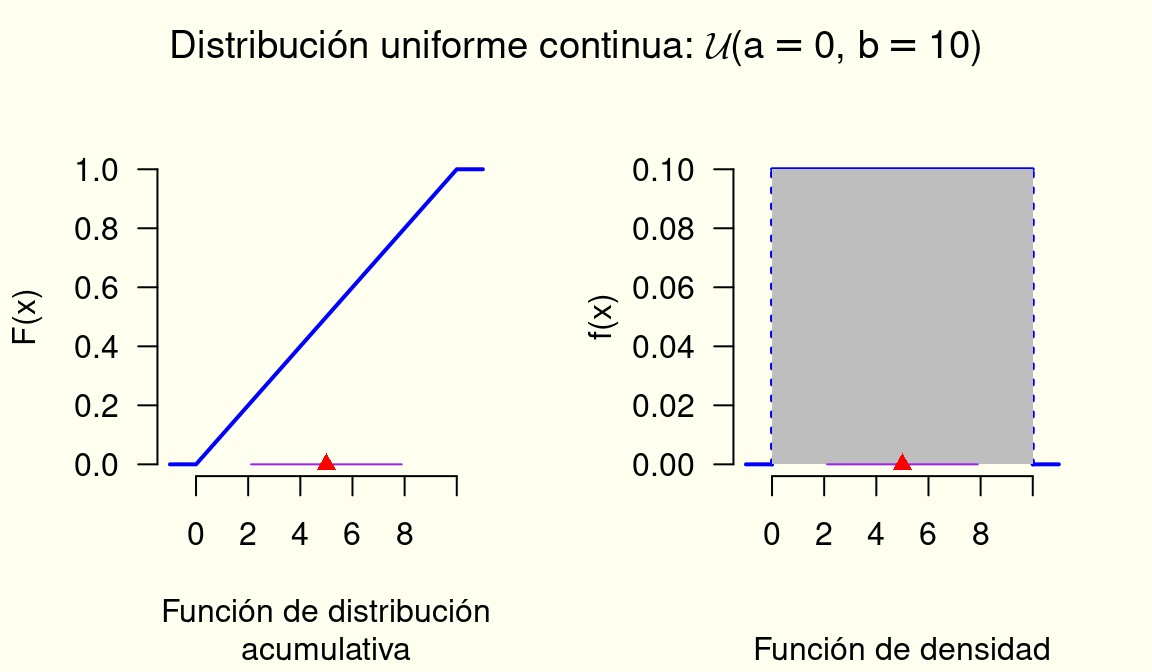
Uniforme Continua
Ejercicio 1
Un autobús llega cada 10 minutos a una parada. Se supone que el tiempo de espera para un individuo en particular es una variable aleatoria con distribución continua uniforme.
¿Cuál es la probabilidad de que el individuo espere más de 7 minutos?
¿Cuál es la probabilidad de que el individuo espere entre 2 y 7 minutos?
Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 6.4.
Características:
Extiende, al caso continuo, la idea de que todos los valores de la variable aleatoria X son igualmente probables.
Dominio (valores que puede tomar la variable aleatoria):
x \in [a,b].
Parámetros:
a, límite inferior del dominio de la variable aleatoria, y b, límite superior del dominio de la variable a aleatoria. -\infty < a < b < \infty
Notación:
X \sim \mathcal{U}(a,b), esto se lee así: la variable aleatoria X tiene una distribución uniforme continua de parámetros a y b.
Función de densidad:
f_X(x) =
\begin{cases}
\frac{1}{b-a} & \text{Si } a < x < b \\
0 & \text{en otro caso}
\end{cases}
Función de distribución acumulativa:
F_X(x) =
\begin{cases}
0 & \text{Si } x < a \\
\frac{x-a}{b-a} & \text{Si } a \leq x < b \\
1 & \text{Si } b \leq x
\end{cases}
Ejercicio 2 Supongamos que el tiempo de desplazamiento en TM de mi casa a la Universidad puede ser cualquier valor entre 40 y 60 minutos, todos igualmente probables. Si a las 10:05 am estoy tomando el TM desde la estación que queda cerca a mi casa, ¿cuál es la probabilidad de que llegue tarde a clase de 11 am?, ¿En promedio a que horas se espera que llegue?
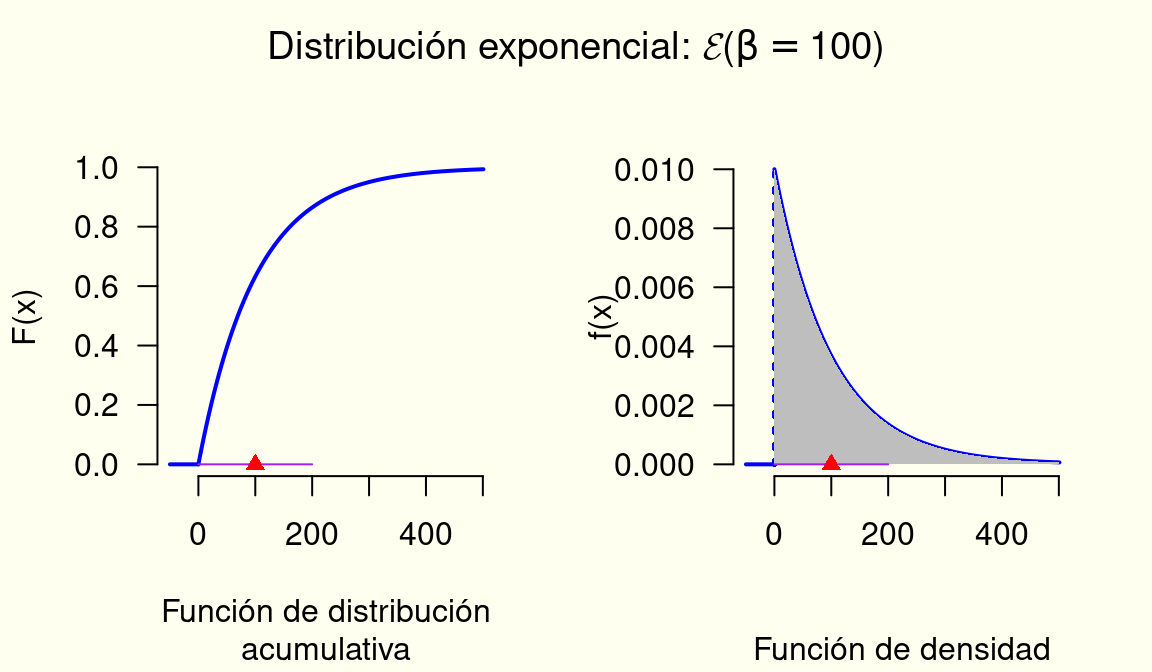
Distribución Exponencial
Ejercicio 3
Cierto tipo de dispositivo tiene una tasa de fallas anunciada de 0.01 por hora. La tasa de fallas es constante y se aplica la distribución exponencial.
¿Cuál es el tiempo promedio que transcurre antes de la falla?
¿Cuál es la probabilidad de que pasen 200 horas antes de que se observe una falla?
Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 6.66.
Características:
La longitud de intervalo entre ocurrencias consecutivas de un proceso Poisson es una variable aleatoria X con distribución exponencial.
Dominio (valores que puede tomar la variable aleatoria):
x \in [0,\infty).
Parámetro de escala
Parámetros:
\beta, promedio de la variable aleatoria (longitud de intervalo promedio entre ocurrencias consecutivas de un proceso Poisson). \beta > 0
Notación:
X \sim \mathcal{E}(\beta), esto se lee así: la variable aleatoria X tiene una distribución exponencial de parámetro (de escala) \beta.
Función de densidad:
f_X(x) =
\begin{cases}
\frac{1}{\beta} e^{-x/\beta} & \text{Si } x \geq 0 \\
0 & \text{en otro caso}
\end{cases}
Si Y := “número de ocurrencias” y Y \sim \mathcal{P}(\lambda), entonces X := “longitud de intervalo entre ocurrencias” tiene distribución exponencial de parámetro \beta = \frac{1}{\lambda}.
Notación:
X \sim \mathcal{E}(\lambda), esto se lee así: la variable aleatoria X tiene una distribución exponencial de parámetro (de tasa) \lambda.
Función de densidad:
f_X(x) =
\begin{cases}
\lambda e^{-\lambda \, x} & \text{Si } x > 0 \\
0 & \text{en otro caso}
\end{cases}
Ejercicio 4 Supongamos que un estudiante siempre llega tarde a clase, que la cantidad de tiempo de clase que se pierde sigue una distribución exponencial y que su promedio de llegada tarde es de 10 minutos, ¿cuál es la probabilidad de que llegue a clase después de las 11:15 am?. Si después de llegar media hora tarde decide no entrar. ¿De 32 clases al semestre, a cuántas se esperaría que no entre?
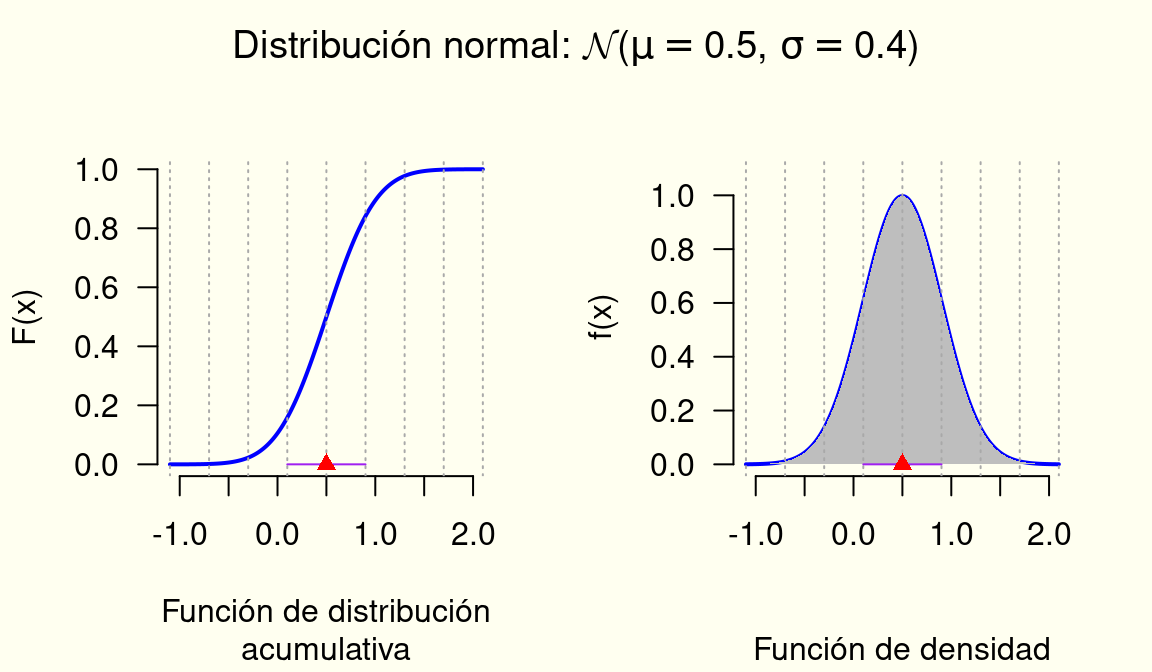
Distribución Gaussiana
Ejercicio 5
En un proyecto experimental sobre el factor humano se determinó que el tiempo de reacción de un piloto ante un estímulo visual es distribuido normalmente con una media de 1/2 segundo y una desviación estándar de 2/5 de segundo.
¿Cuál es la probabilidad de que una reacción del piloto tome más de 0.3 segundos?
¿Qué tiempo de reacción se excede el 95\% de las veces?
Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 6.80.
Características:
“La distribución normal, distribución de Gauss, distribución gaussiana o distribución de Laplace-Gauss, es una de las distribuciones de probabilidad de variable continua que con más frecuencia aparece en estadística y en la teoría de probabilidades.
La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de una función gaussiana.
La importancia de esta distribución radica en que permite modelar numerosos fenómenos naturales, sociales y psicológicos.
Algunos ejemplos de variables asociadas a fenómenos naturales que siguen el modelo de la normal son:
caracteres morfológicos de individuos como la estatura;
caracteres fisiológicos como el efecto de un fármaco;
caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos;
caracteres psicológicos como el cociente intelectual;
nivel de ruido en telecomunicaciones;
errores cometidos al medir ciertas magnitudes;
etc.
La distribución normal también aparece en muchas áreas de la propia estadística.”
Note que la función de distribución acumulativa de una variable aleatoria gaussiana simplemente se dejó expresada y ya. Resulta que no se conoce una expresión cerrada simple para la antiderivada de la función de densidad de una variable aleatoria gaussiana. Entonces, ¿cómo se supone que voy a obtener las probabilidades que necesito, si la integral correspondiente no tiene solución analítica?, recordemos que para una variable aleatoria continua: P[x_1 < X < x_2] = \int\limits_{x_1}^{x_2} f_X(t) \, dt.
Respuesta
La solución a la anterior inquietud sería la siguiente: para una variables aleatoria X \sim \mathcal{N}(\mu,\sigma), transformamos el problema P[x_1 < X < x_2] en un problema equivalente que use una variable aleatoria Z \sim \mathcal{N}(0,1), luego, usando aproximaciones numéricas de F_Z(z) = \int\limits_{-\infty}^{z} f_Z(t) \, dt, encontramos la respuesta al problema equivalente.
Transformación (Estandarización):
Si X \sim \mathcal{N}(\mu,\sigma) y Z = \frac{X-\mu}{\sigma}, entonces Z \sim \mathcal{N}(0,1).
\begin{aligned}
P[x_1 < X < x_2] &= P\left[x_1 - \mu < X - \mu < x_2 - \mu\right] \\
&= P\left[\frac{x_1 - \mu}{\sigma} < \frac{X - \mu}{\sigma} < \frac{x_2 - \mu}{\sigma}\right] \\
&= P\left[z_1 < Z < z_2\right],
\end{aligned}
en donde, z_1 = \frac{x_1 - \mu}{\sigma} \quad \text{y} \quad z_2 = \frac{x_2 - \mu}{\sigma}, además ya sabíamos que,
\begin{aligned}
P\left[z_1 < Z < z_2\right] &= P\left[Z < z_2\right] - P\left[Z < z_1\right] \\
&= F_Z\left(z_2\right) - F_Z\left(z_1\right),
\end{aligned}
y las aproximaciones numéricas para F_Z(z) se encuentran tabuladas (por ejemplo, ver libro de Anderson. Página FM1 o 978) o se pueden obtener mediante herramientas electrónicas, incluyendo algunas calculadoras.
Dentro del conjunto de variables aleatorias que tienen distribución gaussiana, Z \sim \mathcal{N}(0,1) es evidentemente una variable particularmente especial. Este caso especial se denomina distribución normal estándar (con media igual a cero y desviación estándar igual a uno) y naturalmente su función de densidad es, f_Z(z) = \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2} z^2}
Ejercicios
Ejercicio 6
Dada una distribución normal con \mu = 30 y \sigma = 6, calcule
el área de la curva normal a la derecha de x = 17;
el área de la curva normal a la izquierda de x = 22;
el área de la curva normal entre x = 32 y x = 41;
el valor de x que tiene 80% del área de la curva normal a la izquierda;
los dos valores de x que contienen 75% central del área de la curva normal.
Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 6.8.
Ejercicio 7
Dada la variable X normalmente distribuida con una media de 18 y una desviación estándar de 2.5, calcule
P(X < 15);
el valor de k tal que P(X < k) = 0.2236;
el valor de k tal que P(X > k) = 0.1814;
P(17 < X < 21).
Walpole, Myers & Myers (2012). Probabilidad y estadística para ingeniería y ciencias. (9a. ed.) Pearson Educación. Ejercicio 6.9.
Ejercicio 8 Supongamos que el tiempo de desplazamiento en TM de mi casa a la Universidad tiene una distribución normal con media 50 minutos y desviación estándar 5 minutos. Si a las 10:05 am estoy tomando el TM desde la estación cerca de mi casa, ¿cuál es la probabilidad de que llegue tarde a clase de 11 am?. ¿De 32 clases, a cuántas se espera que llegue tarde?
Ejercicio 9
El precio medio de las acciones de las empresas que forman el S&P 500 es \$30, y la desviación estándar es \$8.20 (BusinessWeek, publicación anual especial, primavera de 2003). Suponga que los precios de las acciones se distribuyen normalmente.
¿Cuál es la probabilidad de que las acciones de una empresa tengan un precio mínimo de \$40?
¿Cuál es la probabilidad de que el precio de las acciones no supere \$20?
¿Qué tan alto debe ser el precio de las acciones de una firma para situarla en el 10\% de las principales empresas?
Anderson, Sweeney, Williams & Camm (2016). Estadística para Negocios y Economía. (12a. ed.) Cengage Learning. Sección 6.2, ejercicio 18.
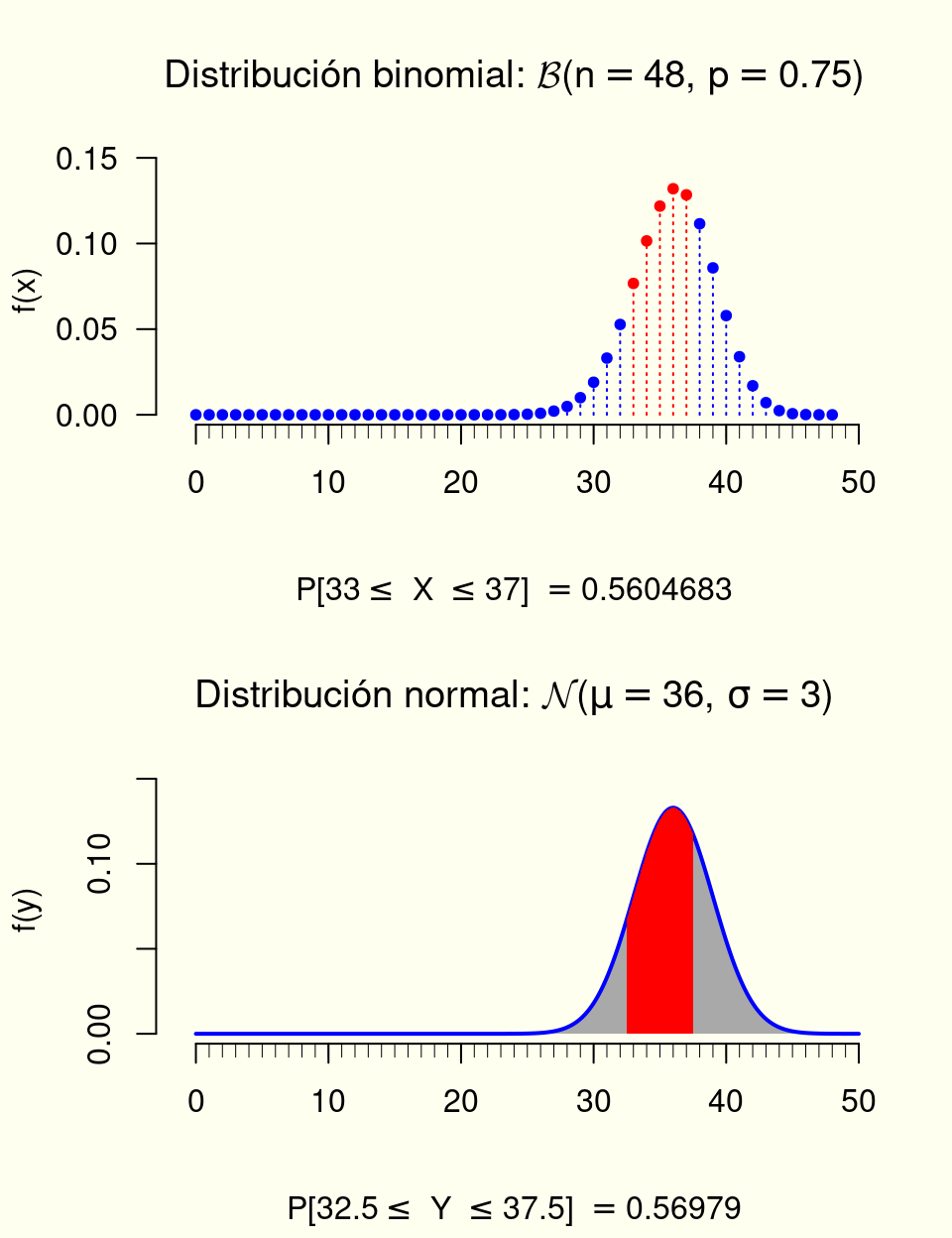
Relación con la binomial
Se tiene que, X \sim \mathcal{B}(n,p) \underset{n \to \infty}{\longrightarrow} Y \sim \mathcal{N}\left(np, \sqrt{np(1-p)}\right)
Es decir, si X \sim \mathcal{B}(n,p), entonces \frac{X - np}{\sqrt{np(1-p)}} \underset{n \to \infty}{\longrightarrow} Z \sim \mathcal{N}(0, 1)
Generalmente se debe hacer una corrección por continuidad (es decir, tengo que tener en cuenta que estoy utilizando una distribución continua para aproximar una distribución discreta):
Si X \sim \mathcal{B}(n,p), np > 5 y n(1-p) > 5 entonces,
\begin{aligned}
P[X \leq x] &\approx P\left[Y \leq (x+0.5) \right] \\
& \approx P\left[Z \leq \frac{(x+0.5)-np}{\sqrt{np(1-p)}} \right]
\end{aligned}
donde Y \sim \mathcal{N}(np,\sqrt{np(1-p)}) y Z \sim \mathcal{N}(0,1).
Buscando ilustrar en alguna medida todo lo anterior, se presenta el siguiente gráfico:
Ejercicio 10 Se cree que 1 de cada 10 votantes registrados en una gran ciudad están a favor de un nuevo impuesto. Si se escogen de manera aleatoria e independiente 1000 votantes y se les pregunta su opinión, ¿cuál es la probabilidad de que al menos 900 estén en contra?
Para más detalles acerca de las características de varias distribuciones discretas y continuas, consultar la siguiente bibliografía clásica básica: Johnson et al. (1994), Johnson et al. (1995), Johnson et al. (2005)
Johnson, N. L., Kemp, A. W., and Kotz, S. (2005), Univariate
discrete distributions, Wiley series in probability and statistics,
Wiley.
Johnson, N. L., Kotz, S., and Balakrishnan, N. (1994), Continuous
univariate distributions, volume 1, Wiley series in probability and
statistics, Wiley.
Johnson, N. L., Kotz, S., and Balakrishnan, N. (1995), Continuous
univariate distributions, volume 2, Wiley series in probability and
statistics, Wiley.