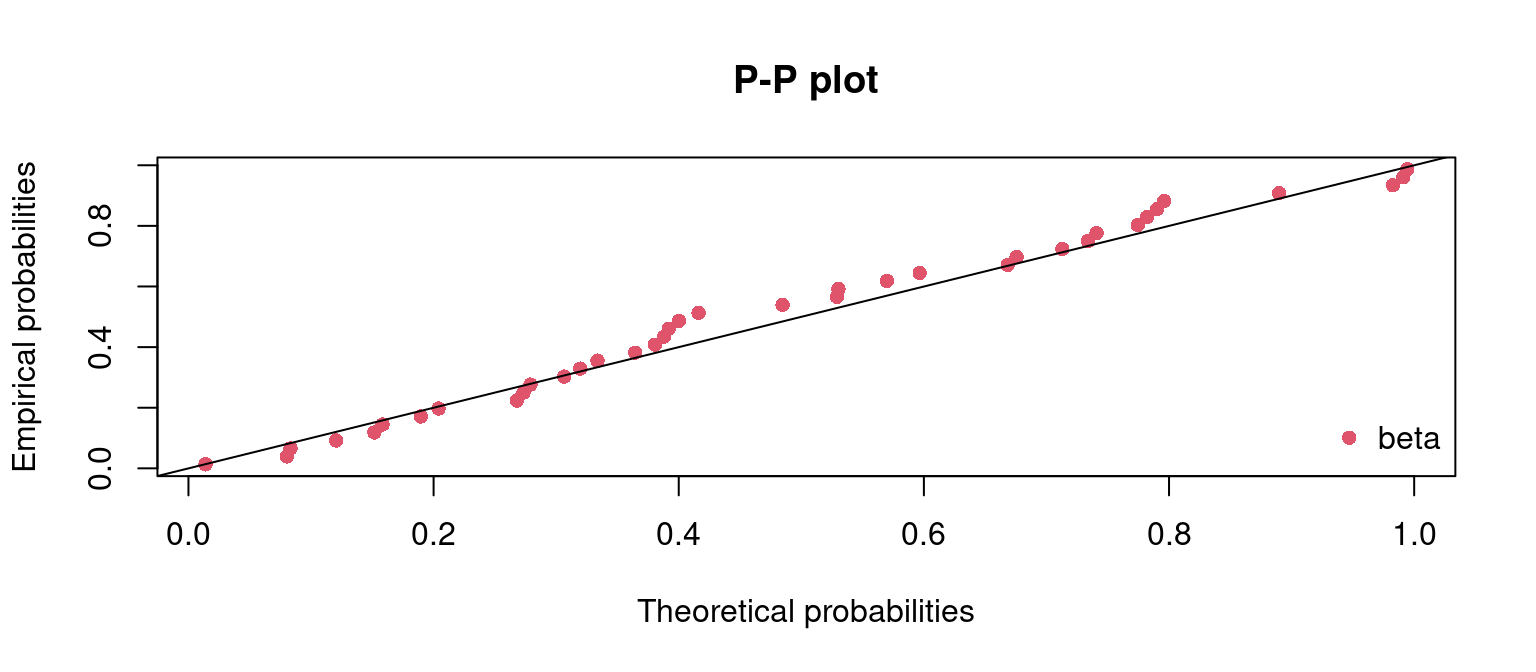
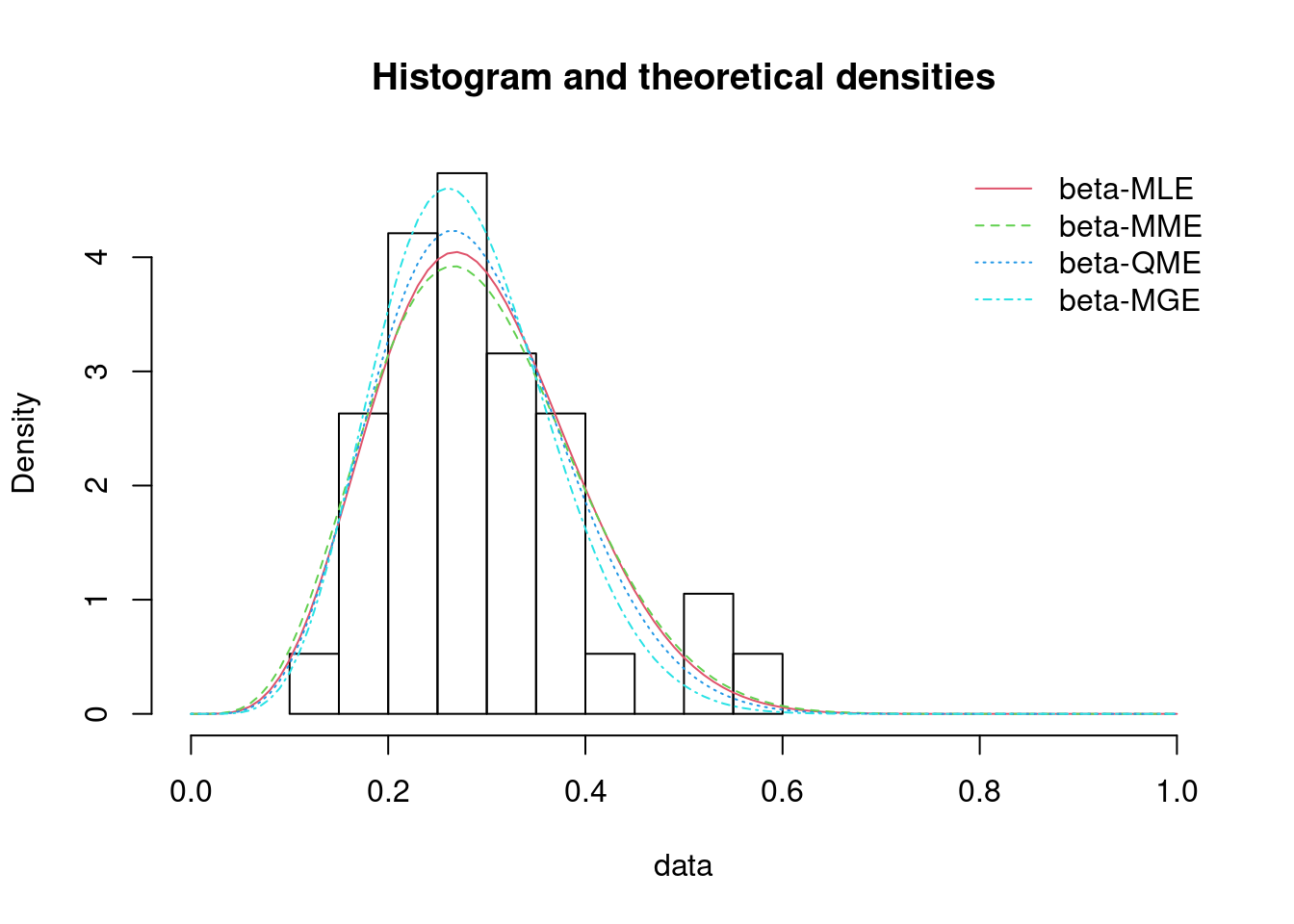
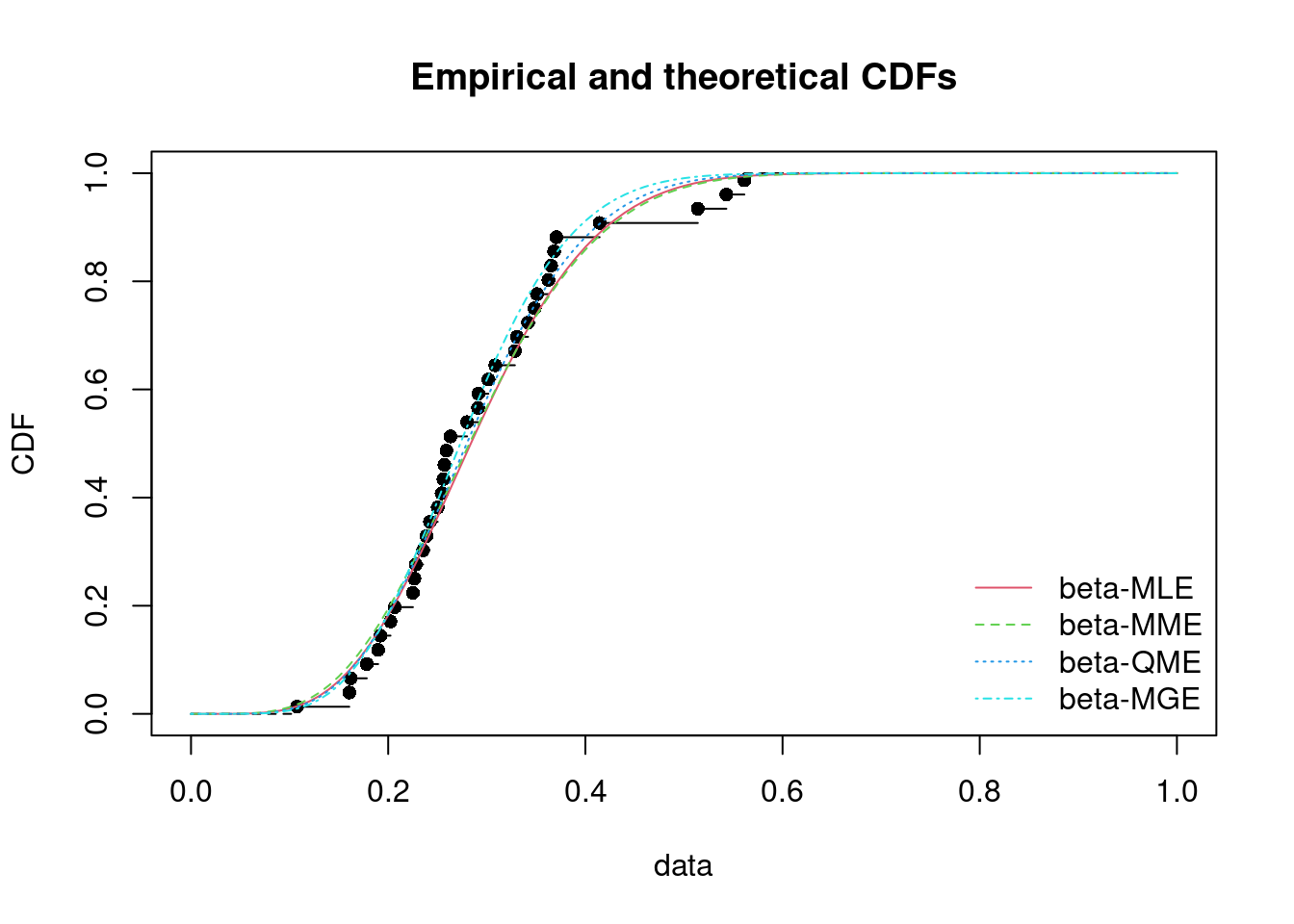
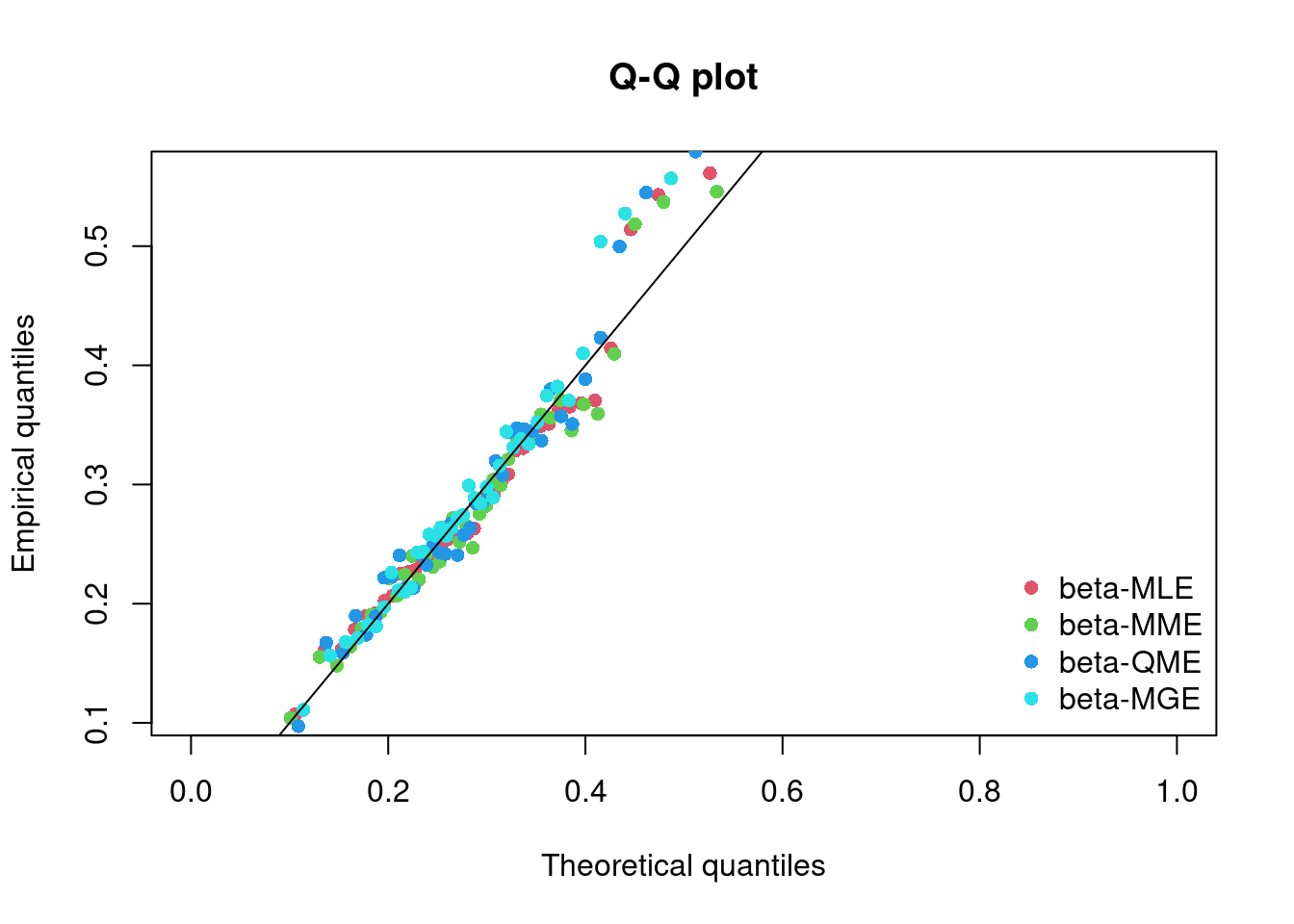
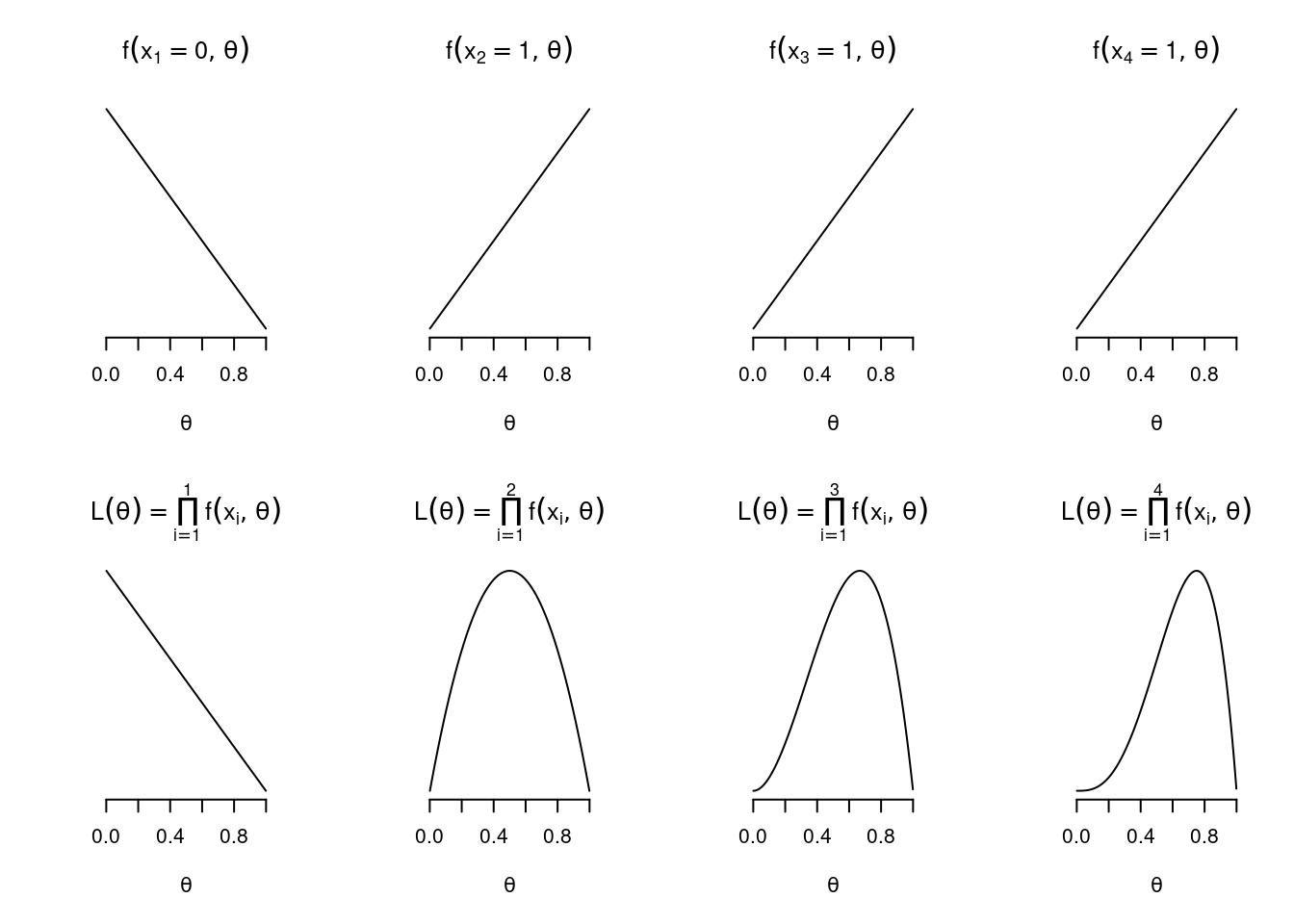En esta sección se hará una revisión de algunos temas relacionados con la estimación puntual de parámetros, específicamente los relacionados con la obtención de estimadores mediante el método de máxima verosimilitud y de otros métodos.
2.1 Preliminares
El objetivo de la estimación puntual de parámetros es obtener, a partir de la muestra, un valor que pueda ser una “buena aproximación” de un parámetro (o una función del mismo).
Estimador puntual: Un estimador puntual de un parámetro \theta es una función de una muestra aleatoria: \mathrm{T} \left( X_1, \dots, X_n \right) que es utilizada para estimar el parámetro \theta.
Estimación puntual: Una estimación puntual \hat{\theta} de un parámetro \theta es el valor que toma un estimador puntual dada una realización de la muestra aleatoria: \hat{\theta} = \mathrm{T} \left( x_1, \dots, x_n \right).
Definición 2.1 Una estadísticaT = \mathrm{T} \left( X_1, \dots, X_n \right) cuyos valores son utilizados para estimar una función del parámetro \mathrm{g}(\theta) es un estimador de \mathrm{g}(\theta) y las realizaciones del estimador se llaman estimaciones.
¿Cómo encuentro una función apropiada de la muestra aleatoria para que me sea de utilidad en la estimación de parámetros?
En esta sección se hará una revisión de algunos métodos para obtener estimadores puntuales.
2.2 Método de máxima verosimilitud
La función de verosimilitud es la función de densidad conjunta de la muestra aleatoria X_1, \dots, X_n (de las variables aleatorias X_1, \dots, X_n).
Sea X_1 \dots, X_n una muestra aleatoria de una población con función de densidad (o de masa de probabilidad) \mathrm{f}_X(x; \theta), con \theta \in \Theta, la función de verosimilitud de la muestra aleatoria se denota y corresponde a,
\mathrm{f}_{X_1,\dots,X_n}(x_1,\dots,x_n;\theta) = \mathrm{L}\left(\theta; x_1, \dots, x_n \right),
donde x_1, \dots, x_n son realizaciones de las variables aleatorias que constituyen la muestra aleatoria, es decir son los valores observados o los datos con que se cuenta, y por ende se asumen conocidos en la función de verosimilitud \mathrm{L}\left(\theta; x_1, \dots, x_n \right).
Ejemplo 2.1 (Función de verosimilitud, distribución Bernoulli) Supongamos que nuestra variable aleatoria de interés X toma únicamente dos valores, uno asociado a “acierto” x=1 y otro a “fracaso” x = 0. Esta variable tendrá una distribución Bernoulli de parámetro \theta = p \in (0,1), asociado a la probabilidad de “acierto”.
En este caso, el objetivo sería encontrar \hat{\theta}_{ML} = T(x_1, \dots, x_n) para una muestra aleatoria X_1, \dots, X_n de una población con X \sim Bern(p = \theta).
En este ejemplo, la función de verosimilitud es \mathrm{L}\left(\theta; x_1, \dots, x_n \right) = \prod_{i=1}^{n} \mathrm{f}_X(x_i; \theta), en donde \mathrm{f}_X \left(x; \theta\right) = \theta^x (1-\theta)^{1-x} \mathrm{I}_{\{0,1\}}(x).
Para poder observar gráficamente la función de verosimilitud, supongamos que tenemos la siguiente realización de la muestra aleatoria: x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 1:
Código
x<-c(0, 1, 1, 1)# Realización de la muestra aleatorian<-length(x)# Tamaño de la muestra### Gráfica funciones de densidad y funciones de verosimilitudlayout(matrix(c(1:(2*n)), 2, n))# Malla para 2 x n gráficosp<-seq(0.001, 0.999, by =0.001)# valores que toma el parámetro pl<-rep(1, length(p))# inicializa la variable para la función de verosimilitudfor(iin1:n){f<-p^(x[i])*(1-p)^(1-x[i])# valores que toma la función de densidad plot(p, f, type="l", ylim=c(0,1), bty="none", yaxt="n", ylab="", xlab=expression(theta), main=bquote(f(x[.(i)]==.(x[i]),theta)))l<-l*f# funciones de verosimilitud a medida que incluyo valores x_iplot(p, l, type="l", bty="none", yaxt="n", ylab="", xlab=expression(theta), main=bquote(L(theta)==prod(f(x[i],theta),i==1,.(i))))}
Se dice que el estimador \mathrm{T}(X_1 \dots, X_n) es el estimador máximo-verosímil de \theta (Maximum-Likelihood (ML) Estimator of \theta) si al tomar \theta = \mathrm{T}(x_1 \dots, x_n) \in \Theta se obtiene el supremo de la función de verosimilitud de la muestra aleatoria, es decir,
\mathrm{L}\left(\hat{\theta}_{ML}; x_1, \dots, x_n \right) = \sup_{\theta \in \Theta} \mathrm{L}\left(\theta; x_1, \dots, x_n \right),
o escrito de otra forma,
\hat{\theta}_{ML} = \underset{\theta \in \Theta}{\arg \sup} \; \mathrm{L}\left(\theta; x_1, \dots, x_n \right),
donde \hat{\theta}_{ML} = \mathrm{T}(x_1 \dots, x_n) es la estimación máximo-verosímil de \theta.
Por otra parte se tiene que,
\begin{aligned}
\hat{\theta}_{ML} &= \underset{\theta \in \Theta}{\arg \sup} \; \mathrm{L}\left(\theta; x_1, \dots, x_n \right) \\
&= \underset{\theta \in \Theta}{\arg \sup} \; \mathrm{g} \big( \mathrm{L}\left(\theta; x_1, \dots, x_n \right) \big)
\end{aligned}
para \mathrm{g}(.) una función monótona creciente.
En particular,
\begin{aligned}
\hat{\theta}_{ML} &= \underset{\theta \in \Theta}{\arg \sup} \; \mathrm{L}\left(\theta; x_1, \dots, x_n \right) \\
&= \underset{\theta \in \Theta}{\arg \sup} \; \log \big( \mathrm{L}\left(\theta; x_1, \dots, x_n \right) \big)
\end{aligned}
y teniendo en cuenta que para una muestra aleatoria se tiene que \mathrm{L}\left(\theta; x_1, \dots, x_n \right) = \prod_{i=1}^{n} \mathrm{f}_X \left( x_i, \theta \right), entonces,
\begin{aligned}
\hat{\theta}_{ML} &= \underset{\theta \in \Theta}{\arg \sup} \; \prod_{i=1}^{n} \mathrm{f}_X \left(x_i, \theta\right) \\
&= \underset{\theta \in \Theta}{\arg \sup} \; \sum_{i=1}^{n} \log \big( \mathrm{f}_X \left(x_i, \theta\right) \big).
\end{aligned}
¿Qué hago para encontrar el o los valores de \theta que maximizan la función de verosimilitud (o su logaritmo)?
2.2.1 Una solución analítica
Bajo ciertas condiciones, los valores de \theta que maximizan la función de verosimilitud \mathrm{L}(\theta; x_1, \dots, x_n) son solución de la ecuación,
\frac{\partial }{\partial \theta} \mathrm{L}(\theta; x_1, \dots, x_n) = 0.
Ademas, esos mismos valores de \theta maximizan el logaritmo de la función de verosimilitud (función de log-verosimilitud) \log \mathrm{L}(\theta; x_1, \dots, x_n), y son solución de la ecuación,
\frac{\partial }{\partial \theta} \log \mathrm{L}(\theta; x_1, \dots, x_n) = 0.
Manteniendo el mismo objetivo de encontrar \hat{\theta}_{ML} = \mathrm{T}(x_1 \dots, x_n) cuando X_1 \dots, X_n es una muestra aleatoria de una población con X \sim Bern(p = \theta)\left( \mathrm{f}_X \left(x, \theta\right) = \theta^x (1-\theta)^{1-x} \, \mathrm{I}_{\{0,1\}}(x); 0 < \theta < 1 \right).
La realización de la muestra aleatoria x_1, \dots, x_n es una secuencia de ceros y unos. La función de verosimilitud es,
\begin{aligned}
\mathrm{L}(\theta; x_1, \dots, x_n) &= \prod_{i=1}^{n} \mathrm{f}_X \left(x_i, \theta\right) \\
&= \prod_{i=1}^{n} \theta^{x_i} (1-\theta)^{1-x_i} \, \mathrm{I}_{\{0,1\}}(x_i) \\
&= \theta^{\sum_{i=1}^{n} x_i} (1-\theta)^{n - \sum_{i=1}^{n} x_i} \, \prod_{i=1}^{n} \mathrm{I}_{\{0,1\}}(x_i)
\end{aligned}
Con la segunda derivada tenemos que,
\begin{aligned}
\frac{\partial^2 }{\partial \theta^2} \log \mathrm{L}(\theta; x_1, \dots, x_n) &= -\frac{\sum_{i=1}^{n} x_i}{\theta^2} - \frac{n-\sum_{i=1}^{n} x_i}{(1-\theta)^2} < 0
\end{aligned}
con lo cual se garantiza que \bar{x} es un máximo del logaritmo de la función de log-verosimilitud (y también de la función de verosimilitud).
Concluimos que, \hat{\theta}_{ML} = \bar{x}.
Teniendo en cuenta que la realización de la muestra aleatoria x_1, \dots, x_n es una secuencia de ceros y unos, entonces \sum_{i=1}^{n} x_i es la cantidad de unos en la muestra y \bar{x} sería la proporción de unos. Es decir, para el caso de la distribución Bernoulli, el estimador máximo-verosímil de \theta es la media muestral \bar{X}, que coincide con la proporción muestral \hat{P}. Para X \sim Bern(p = \theta),
\hat{\theta}_{ML} = \bar{x} = \hat{p}.
Finalmente, es bueno recordar que X_1, \dots, X_n es una muestra aleatoria únicamente si las observaciones o realizaciones de dichas variables aleatorias se obtuvieron mediante un adecuado muestreo (lo cual garantiza lo independiente identicamente distribuido de la muestra aleatoria).
Ejercicio 2.1 (Distribución binomial) Sabemos que \sum_{i=1}^{n} X_i \sim Bin(n,p=\theta). Por lo tanto, dada una muestra aleatoria Y_1 de tamaño 1 de una población con Y \sim Bin(n,p=\theta), entonces, suponiendo que n (“número de ensayos”) es conocido, verifique que el estimador máximo verosímil del parámetro \theta (“probabilidad de éxito”) es \frac{y_1}{n}.
Suponiendo que n es conocido, ¿cuál sería el estimador de máximo verosimilitud del parámetro \theta cuando Y_1, \dots, Y_m es una muestra aleatoria de tamaño m de una población con Y \sim Bin(n,p=\theta)\left( \mathrm{f}_Y \left(y, \theta\right) = \binom{n}{y} \theta^y (1-\theta)^{n-y} \, \mathrm{I}_{\{0,1,\dots,n\}}(y) \right)?
2.2.2 Otro tipo de solución analítica
Una variable aleatoria X con distribución hipergeométrica X \sim Hg(n, N, R) se puede visualizar o pensar como el número de individuos que tienen cierta característica de interés (“aciertos”), de n que fueron seleccionados simultáneamente o uno a uno sin reemplazamiento. Esta selección se realiza sobre una población finita de tamaño N, en donde R de los N individuos tienen la característica de interés (y por ende, N-R no la tienen). La función de densidad de X estaría dada por \mathrm{f}_X \left(x; n, N, R\right) = \frac{\binom{R}{x}\binom{N - R}{n - x}}{\binom{N}{n}} para x \in \mathbb{Z} tal que \max\{0, n - (N - R)\} \leq x \leq \min\{n, R\} (o lo que es lo mismo, para x \in \mathbb{Z} tal que \mathrm{I}_{\{\max\{0, n - (N - R)\},\dots,\min\{n, R\}\}}(x) = 1) y donde n, N, R \in \mathbb{Z}^+.
El que cada individuo seleccionado tenga o no la característica de interés se asocia a una variable aleatoria con distribución Bernoulli, pero en este caso la selección de los n individuos no cumple el criterio de independencia que se exige en el caso de una distribución Binomial. Si X_1, \dots, X_n son variables aleatorias idénticamente distribuidas con X_i \sim Bern\left( p=\frac{R}{N} \right) y sus realizaciones se tomaron simultáneamente, o uno a uno sin reemplazamiento, de una población finita de tamaño N, entonces \sum_{i=1}^{m} X_i = Y \sim Hg(n, N, R). De lo anterior, estimar alguno de los parámetros n, N o R a partir de las variables X_1, \dots, X_n mencionadas es equivalente a estimar dichos parámetros a partir de una muestra aleatoria Y_1 de tamaño 1 de una población con Y \sim Hg(n, N, R).
2.2.2.1 Estimación del parámetro N
Sea Y_1 (o los X_1, \dots, X_n equivalentes descritos anteriormente) y supongamos que n y R son conocidos, entonces el único parámetro a estimar sería \theta = N\left( \mathrm{f}_Y \left(y, \theta\right) = \frac{\binom{R}{y} \binom{\theta - R}{n - y}}{\binom{\theta}{n}} \mathrm{I}_{\{\max\{0, n - (\theta - R)\},\dots,\min\{n, R\}\}}(y) \right). Es decir que en este caso tendríamos conocimiento de que un cierto número de individuos tienen una característica de interés (y_1) dentro una muestra de cierto tamaño (n) (o sabemos que cierto número de individuos tiene la característica (y_1) y cierto número de individuos no la tienen n - y_1); ademas, sabemos que en toda la población hay un cierto número de individuos que tienen la característica (R). A partir de esto que conocemos, queremos inferir la cantidad total de individuos de la población (\theta = N), la cuál debe ser desconocida.
Ilustremos un poco más lo anterior a partir de la siguiente situación. Supongamos que queremos conocer la cantidad de peces de cierta especie en un lago. Para inferir dicha cantidad, introducimos al lago un cierto número de peces (R) de la misma especie pero marcados de alguna manera especial. Al día siguiente, capturamos simultáneamente (pesca con red) o sin reemplazamiento (uno a uno pero sin devolver los peces capturados) y contamos el número de peces con la marca especial (y_1) del total de los que capturamos (n) (o, el número de capturados con la marca especial (y_1) y el número de capturados sin la marca (n-y_1)). Ahora con la información que poseemos se debería poder estimar la cantidad total de peces que había en el lago en el instante previo a proceder con la captura (\hat{\theta} = N), y por ende también la cantidad de peces que había en el lago antes de introducir los marcados \hat{\theta} - R = N - R. Es así que se requiere establecer una fórmula o mecanismo que permita obtener estimaciones máximo verosímiles para \theta = N, a partir de lo observado mediante y_1, y bajo el supuesto de que R y n son conocidos.
Primero, determinemos cuáles podrían ser valores válidos para \theta = N:
A partir del valor que podría tomar y_1, es posible establecer los valores válidos que podría tomar \theta = N:
\begin{aligned}
\max\{0, n - (\theta - R)\} & \leq y_1 \leq \min\{n, R\} \\
n - (\theta - R) & \leq y_1 \\
- (\theta - R) & \leq y_1 - n \\
\theta - R & \geq n - y_1 \\
\theta & \geq R + (n - y_1)
\end{aligned}
Es decir \theta = N tiene que ser un número entero positivo, mayor o igual que la suma del número de individuos con la característica dentro de toda la población (R) y el número de individuos sin la característica dentro de los n seleccionados (n-y_1).
Segundo, determinar cuándo crece, cuando permance constante y cuando decrece la función de verosimilitud:
La función de verosimilitud para el parámetro \theta = N no es una función continua, por tanto no es posible encontrar un máximo usando derivadas. Una alternativa es analizar el comportamiento de la función de verosimilitud, es decir, establecer cuándo crece, cuándo decrece o incluso cuándo permanece constante. Una forma de analizar dicho comportamiento es comparando el cambio que ocurre en los valores que toma la función de verosimilitud para un valor posible del parámetro (\theta^*) y su valor inmediatamente anterior (\theta^*). Es así que comparamos L(\theta^*) con respecto a L(\theta^*-1) y establecemos que, al pasar de (\theta^* - 1) a \theta^*,
L(.) crece si y sólo si L(\theta^*-1) < L(\theta^*), o equivalentemente si 1 < \frac{L(\theta^*)}{L(\theta^*-1)};
L(.) permanece constante si y sólo si L(\theta^*-1) = L(\theta^*), o equivalentemente si 1 = \frac{L(\theta^*)}{L(\theta^*-1)};
L(.) decrece si y sólo si L(\theta^*-1) > L(\theta^*), o equivalentemente si 1 > \frac{L(\theta^*)}{L(\theta^*-1)};
Dada y_1, la realización de la variable aleatoria Y_1 (o x_1, \dots, x_n una realización de X_1, \dots, X_n Bernoulli no independientes), y para \theta^* tal que L(\theta^*-1) \neq 0, es decir para \theta^* - 1 \geq R + (n - y_1), tenemos que,
\begin{aligned}
\frac{L(\theta^*)}{L(\theta^*-1)} &= \frac{\binom{R}{y_1}\binom{\theta^* - R}{n - y_1}}{\binom{\theta^*}{n}} \frac{\binom{\theta^*-1}{n}}{\binom{R}{y_1}\binom{\theta^* - R - 1}{n - y_1}} \\
&= \frac{\binom{\theta^* - R}{n - y_1}}{\binom{\theta^*}{n}} \frac{\binom{\theta^*-1}{n}}{\binom{\theta' - R - 1}{n - y_1}} \\
&= \frac{\frac{(\theta^* - R)!}{(n - y_1)!(\theta^* - R - (n - y_1))!}}{\frac{\theta^*!}{n!(\theta^* - n)!}} \frac{\frac{(\theta^* - 1)!}{n!(\theta^* - n - 1)!}}{\frac{(\theta^* - R - 1)!}{(n - y_1)!(\theta^* - R - (n - y_1)-1)!}} \\
&= \frac{(\theta^* - R)!(\theta^* - n)!(\theta^* - 1)!(\theta^* - R - (n - y_1)-1)!}{(\theta^* - R - (n - y_1))!\theta^*!(\theta^* - n - 1)!(\theta^* - R - 1)!} \\
&= \frac{(\theta^* - R)(\theta^* - n)}{(\theta^* - R - (n - y_1)) \theta^*}
\end{aligned}
Lo que quiere decir que \frac{L(\theta^*)}{L(\theta^*-1)} > 1 (la función de verosimilitud crece) cuando, \frac{(\theta^* - R)(\theta^* - n)}{(\theta^* - R - (n - y_1)) \theta^*} > 1. Además, como \theta^* \in \mathbb{Z}^+ y \theta^* - R - (n - y_1) \geq 1 entonces \frac{L(\theta^*)}{L(\theta^*-1)} > 1 cuando,
\begin{aligned}
(\theta^* - R)(\theta^* - n) & > (\theta^* - R - (n - y_1)) \theta^* \\
\theta^{*2} - R \, \theta^* - n \, \theta + R \, n & > \theta^{*2} - R \, \theta^* - n \, \theta^* + y_1 \, \theta^* \\
R \, n & > y_1 \, \theta^* \\
\frac{R \, n}{y_1} & > \theta^*
\end{aligned}
Concluimos que, al pasar de (\theta^* - 1) a \theta^*,
L(.) crece \left(L(\theta^*) > L(\theta^*-1)\right) si y sólo si \theta^* < \frac{R \, n}{y_1};
L(.) permanece igual \left(L(\theta^*) = L(\theta^*-1)\right) si y sólo si \theta^* = \frac{R \, n}{y_1}.
L(.) decrece \left(L(\theta^*) < L(\theta^*-1)\right) si y sólo si \theta^* > \frac{R \, n}{y_1};
Entonces, \frac{R \, n}{y_1} será un valor de referencia para saber si la función de verosimilitud crece, decrece, o permanece igual.
Tercero, sabiendo cuando crece, permanece igual o decrece la función de verosimilitud, identificar el valor del parámetro que hace que dicha función alcance su valor máximo:
Sin embargo, tenemos dos situaciones distintas, dependiendo de si \frac{R \, n}{y_1} es o no un número entero
Si \frac{R \, n}{y_1} NO ES entero, entonces,
\left[ \frac{R \, n}{y_1} \right] < \frac{R \, n}{y_1} < \left[ \frac{R \, n}{y_1} \right] + 1,
y como L(.) crece al pasar de (\theta* - 1) a \theta* para todo \theta* entero menor que \frac{R \, n}{y_1}, entonces,
\begin{aligned}
L \left( \left[ \frac{R \, n}{y_1} \right] \right) &> L \left( \left[ \frac{R \, n}{y_1} \right] - 1 \right) \\
L \left( \left[ \frac{R \, n}{y_1} \right] - 1 \right) &> L \left( \left[ \frac{R \, n}{y_1} \right] - 2 \right) \\
&\dots
\end{aligned}
además, como L(.) decrece al pasar de (\theta* - 1) a \theta* para todo \theta* entero mayor que \frac{R \, n}{y_1}, entonces,
\begin{aligned}
L \left( \left[ \frac{R \, n}{y_1} \right] + 1 \right) &< L \left( \left( \left[ \frac{R \, n}{y_1} \right] + 1 \right) - 1 \right) = L \left( \left[ \frac{R \, n}{y_1} \right] \right) \\
L \left( \left[ \frac{R \, n}{y_1} \right] + 2 \right) &< L \left( \left( \left[ \frac{R \, n}{y_1} \right] + 2 \right) - 1 \right) = L \left( \left[ \frac{R \, n}{y_1} \right] + 1 \right) \\
&\dots
\end{aligned}
De los dos resultados anteriores, concluimos que L \left( \left[ \frac{R \, n}{y_1} \right] \right) es el máximo valor posible de la función L(.) y por ende \hat{\theta}_{ML} = \left[ \frac{R \, n}{y_1} \right].
Ahora, si \frac{R \, n}{y_1} ES entero, entonces,
\left[ \frac{R \, n}{y_1} \right] = \frac{R \, n}{y_1}
a partir de lo cual se puede ver que:
L(.) crece para \theta < \left[ \frac{R \, n}{y_1} \right], es decir, L \left( \left[ \frac{R \, n}{y_1} \right] - 1 \right) > L \left( \left[ \frac{R \, n}{y_1} \right] - 2 \right) > L \left( \left[ \frac{R \, n}{y_1} \right] - 3 \right) > \dots,
L(.) permanece igual para \theta = \left[ \frac{R \, n}{y_1} \right], es decir, L \left( \left[ \frac{R \, n}{y_1} \right] \right) = L \left( \left[ \frac{R \, n}{y_1} \right] - 1 \right),
L(.) decrece para \theta > \left[ \frac{R \, n}{y_1} \right], es decir, L \left( \left[ \frac{R \, n}{y_1} \right] \right) > L \left( \left[ \frac{R \, n}{y_1} \right] + 1 \right) > L \left( \left[ \frac{R \, n}{y_1} \right] + 2 \right) > \dots.
De donde se concluye que \left[ \frac{R \, n}{y_1} \right] y \left[ \frac{R \, n}{y_1} \right] - 1 son los valores del parámetro que hacen que L(\theta) alcance su valor máximo. En este caso, \left[ \frac{R n}{y_1} \right] y \left[ \frac{R n}{y_1} \right] - 1 serían las estimaciones máximo verosímiles de \theta. \hat{\theta}_{ML} no sería único, \hat{\theta}_{ML} = \left\{ \left[ \frac{R n}{y_1} \right] - 1, \left[ \frac{R n}{y_1} \right] \right\}
Cuarto, usamos el estimador que hallamos en todas las aplicaciones prácticas que apliquen
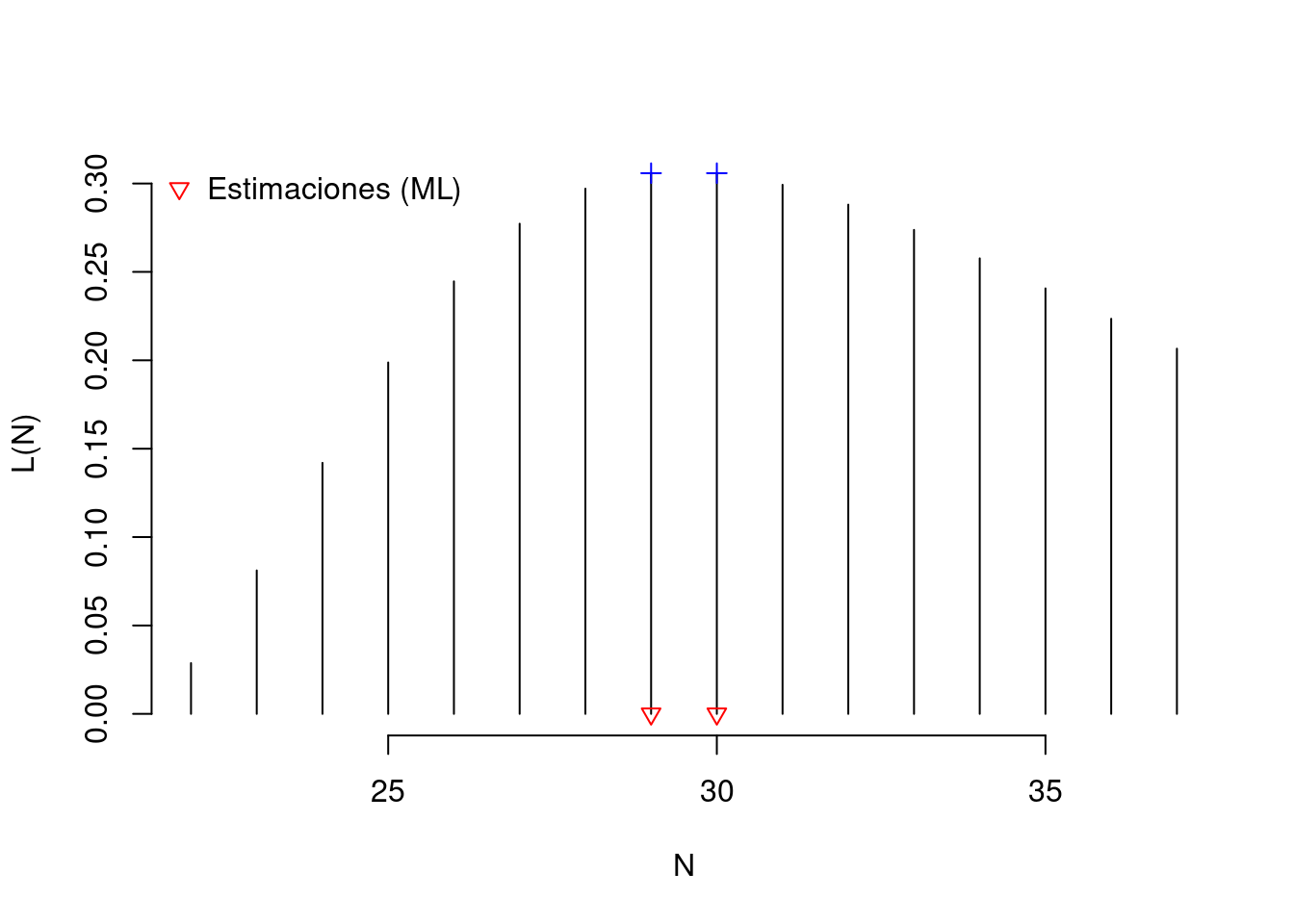
Mediante el anterior desarrollo analítico obtuvimos las expresiones matemáticas para asociadas a las estimaciones máximo verosímiles. Ahora para ilustrar un poco las cosas, primero simulemos la selección simultanea (sin reemplazamiento) de n = 10 individuos sobre una población de tamaño N = 30, en donde R = 18. Eso sí, sin olvidar que en la realidad los datos poblacionales son desconocidos (no se podría saber que N = 30). Por eso aquí estamos hablando de datos simulados y no de datos reales (a continuación, ALL serían los datos poblacionales desconocidos y tanto x como y_1.op2 serían los datos muestrales simulados).
Código
# Datos poblacionales (que en una situación real no conocería)ALL<-c(1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1,0, 1, 1, 0, 1, 0, 1, 1, 0, 1)N<-length(ALL)# Datos conocidosR<-sum(ALL)n<-10# Semilla para la generación de valores pseudoaleatoriosset.seed(123)
Código
# Simulación opción 1: # muestra de tamaño n sin reemplazamiento de una variable Bernoullix<-sample(ALL, n, replace =FALSE)y_1.op1<-sum(x)cat("Simulación opción 1.\nx_1, ..., x_n: ", paste(x, collapse =", "),"\ny_1: ", y_1.op1)
# Simulación opción 2: # muestra de tamaño 1 de una variable Hipergeométricay_1.op2<-rhyper(1, R, N-R, n)cat("Simulación opción 2.\ny_1: ", y_1.op2)
Simulación opción 2.
y_1: 6
Luego, veamos la función de verosimilitud asociada a los datos simulados y_1 (es decir, la función de verosimilitud asociada a lo que sería conocido: y_1, n y R), y las estimaciones máximo verosímiles para el parámetro \theta = N.
Código
aux.plot<-0:15theta<-R+(n-y_1.op2)+aux.plotL<-dhyper(y_1.op2, R, theta-R, n)plot(theta, L, type ="h", bty ="n", xlab ="N", ylab ="L(N)", ylim=c(0,max(L)))val.ref<-R*n/y_1.op2if(val.ref!=trunc(val.ref)){theta.hat<-trunc(val.ref)}else{theta.hat<-trunc(val.ref)-c(0,1)}points(theta.hat, dhyper(y_1.op2, R, theta.hat-R, n), col ="blue", pch =3)points(theta.hat, rep(0, length(theta.hat)), col ="red", pch =6)legend("topleft", legend ="Estimaciones (ML)", col ="red", pch =6, bty ="n")
¿Qué pasaría si en vez de Y_1 (o las equivalente X_1, \dots, X_n variables aleatorias Bernoulli no independientes), se tiene una muestra aleatoria Y_1, \dots, Y_m de tamaño m, de una población Y \sim Hg(n,N = \theta,R)?
Para ilustrar un poco la situación, podemos simular un conjunto de datos asociado a la misma:
Código
m<-15# Tamaño de muestra# R, N y n iguales que antesy<-rhyper(m, R, N-R, n)# Simular una realización de la muestra aleatoriacat("y_1, ..., y_m: ", paste(y, collapse =", "))
Para los datos simulados, la estimación máximo verosímil sería, \hat{\theta}_{ML} = \hat{N}_{ML} = 32, Ya que es el valor para el cual la función de log-verosimilitud llega a su máximo (suponiendo que para \theta = 36, 37, \dots dicha función seguirá decreciendo).
En este caso, se encontró la estimación para un caso particular, pero desconocemos la expresión matemática del estimador respectivo. Aún no tenemos la expresión matemática de la función de la muestra correspondiente al estimador máximo verosímil.
¿Será posible demostrar que \hat{\theta}_{ML} = \max \left\{\theta \in \mathbb{Z}^+ : \theta \geq \left( R + \underset{1 \leq i \leq m}{\max} \left\{ n - x_i \right\} \right) \land \frac{L(\theta+1)}{L(\theta)} \geq 1 \right\} para Y_1, \dots, Y_m una muestra aleatoria de una población Y \sim Hg(n,N = \theta,R)?
¿Es posible encontrar de forma analítica una expresión más simple para el estimador máximo verosímil del parámetro \theta = N, suponiendo que n y R son conocidos?
2.2.2.2 Estimación del parámetro R
Ejercicio 2.2 Sea Y_1 una variable aleatoria como la descrita anteriormente (o la muestra X_1, \dots, X_n equivalente) y supongamos que n y N son conocidos, entonces el único parámetro a estimar sería \theta = R\left( \mathrm{f}_Y \left(y, \theta\right) = \frac{\binom{\theta}{y} \binom{N - \theta}{n - y}}{\binom{N}{n}} \mathrm{I}_{\{\max\{0, n - (N - \theta)\},\dots,\min\{n, \theta\}\}}(y) \right).
¿Cuál sería la expresión matemática asociada a la estimación máximo verosímil del parámetro \theta = R, suponiendo que n y N son conocidos??
¿Qué pasaría si en vez de Y_1 (o las equivalente X_1, \dots, X_n variables aleatorias Bernoulli no independientes), se tiene una muestra aleatoria Y_1, \dots, Y_m de tamaño m, de una población Y \sim Hg(n, N, R = \theta)?
Para ilustrar un poco la situación, podemos simular un conjunto de datos asociado a la misma:
Código
m<-15# Tamaño de muestraN<-20; R<-8; n<-10# Supongamos estos valores para los parámetrosy<-rhyper(m, R, N-R, n)# Simular una realización de la muestra aleatoriacat("y_1, ..., y_m: ", paste(y, collapse =", "))
Para los datos simulados, la estimación máximo verosímil sería, \hat{\theta}_{ML} = \hat{R}_{ML} = 8, Ya que es el valor para el cual la función de log-verosimilitud llega a su máximo (los posibles valores de \theta son finitos, entonces estoy seguro de que se logró llegar a un valor que maximiza dicha función).
En este caso, se encontró la estimación para un caso particular, pero desconocemos la expresión matemática del estimador respectivo. Aún no tenemos la expresión matemática de la función de la muestra correspondiente al estimador máximo verosímil.
¿Para este caso (muestra aleatoria Y_1, \dots, Y_m de tamaño m, de una población Y \sim Hg(n, N, R = \theta)), es posible encontrar de forma analítica una expresión relativamente simple para el estimador máximo verosímil del parámetro \theta = R, suponiendo que n y N son conocidos?
2.2.2.3 Estimación del parámetro n
De la misma manera en que lo hicimos con los parámetros R y N, podríamos tomar Y_1 (o la muestra X_1, \dots, X_n equivalente) y suponer que N y R son conocidos, entonces el único parámetro a estimar sería n = \theta\left( \mathrm{f}_Y \left(y, \theta\right) = \frac{\binom{R}{y} \binom{N - R}{\theta - y}}{\binom{N}{\theta}} \mathrm{I}_{\{\max\{0, \theta - (N - R)\},\dots,\min\{\theta, R\}\}}(y) \right). Matemáticamente hablando, no veríamos problema alguno en tratar de establecer una fórmula o mecanismo que nos permita llegar a estimaciones máximo verosímiles para n = \theta. Sin embargo, antes de ponernos a trabajar en ello deberíamos preguntarnos:
¿Es posible encontrar o proponer una situación real o hipotética en donde se requiera inferir n (el cual naturalmente tiene que ser desconocido) a partir de lo observado mediante y_1, y bajo el supuesto de que N y R son conocidos?
2.2.3 Una solución numérica
Supongamos que queremos estimar los parámetros de la distribución poblacional asociada a la variable porcentaje de gasto en alimentación de los hogares, a partir de los datos a los que se refiere el siguiente texto:
The data frame contains 38 observations (random sample of 38 households in a large US city) on 3 variables:
food: household expenditures for food.
income: household income.
persons: number of persons living in household.
Griffiths, W.E., Hill, R.C., and Judge, G.G. 1993. Learning and Practicing Econometrics New York: John Wiley and Sons (Table 15.4).
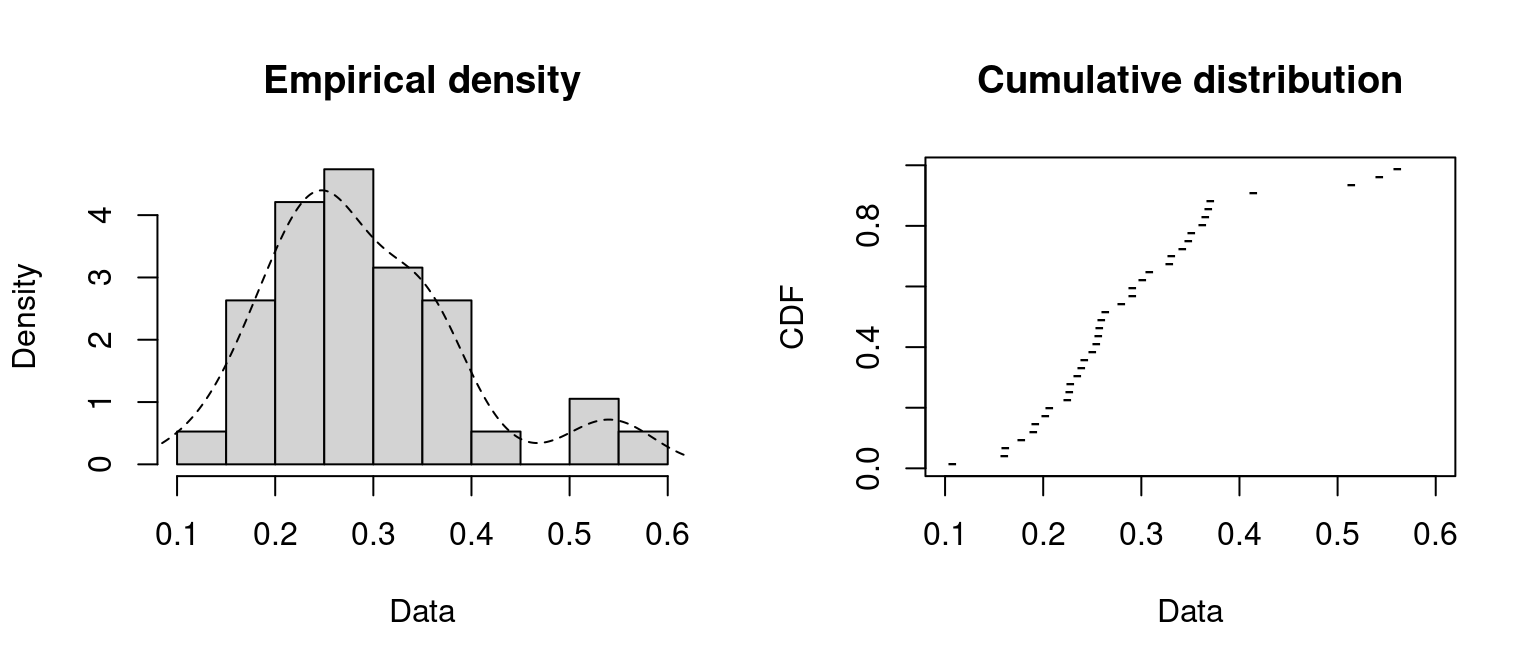
Lo primero que deberíamos hacer es un análisis exploratorio de los datos de la muestra.
Código
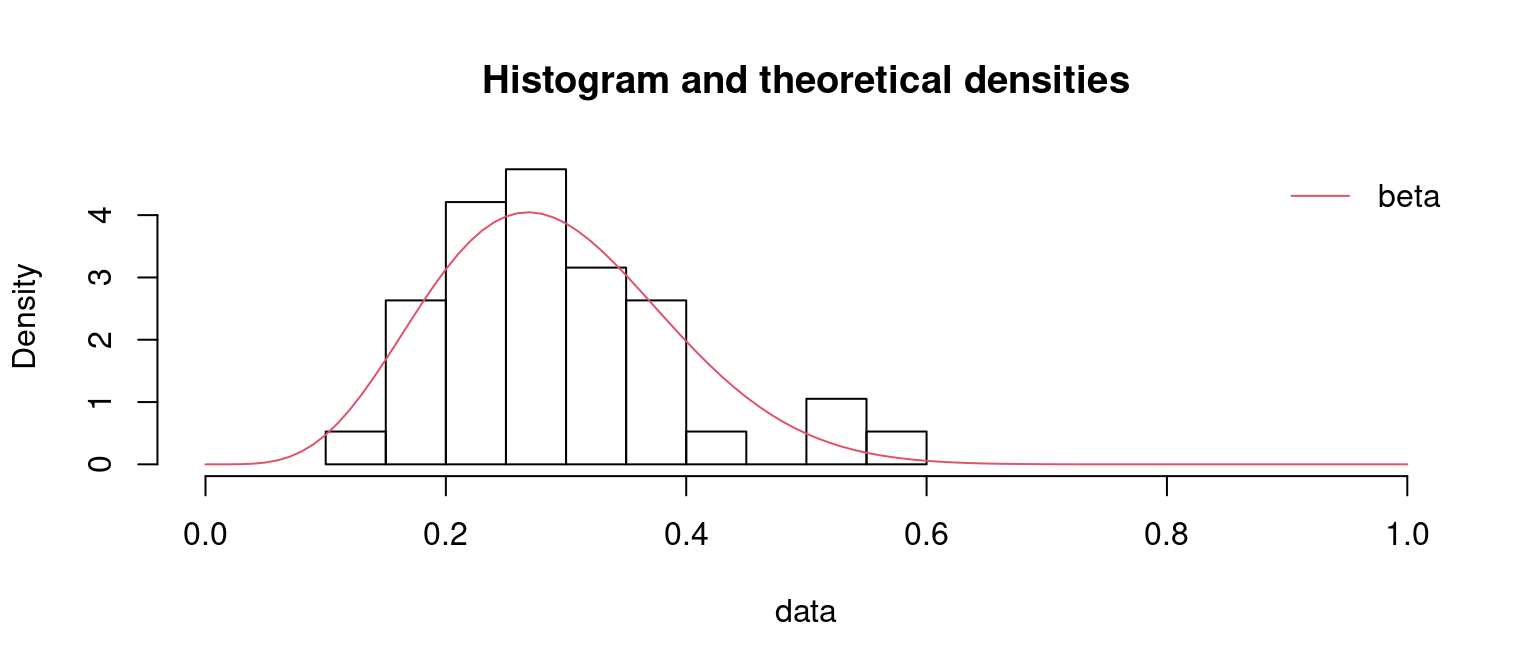
# Instalar y cargar la libreria betareg (datos FoodExpenditure)if(!require(betareg)){install.packages("betareg"); require(betareg)}# Cargar los datos de gasto en alimentación (38 hogares)data("FoodExpenditure", package="betareg")# Porcentaje de gasto en alimentaciónx<-FoodExpenditure$food/FoodExpenditure$income# Instalar y cargar la libreria fitdistrplus (gráficos y ajuste)if(!require(fitdistrplus)){install.packages("fitdistrplus"); require(fitdistrplus)}# Gráficoplotdist(x, histo=TRUE, demp=TRUE, pch="-")
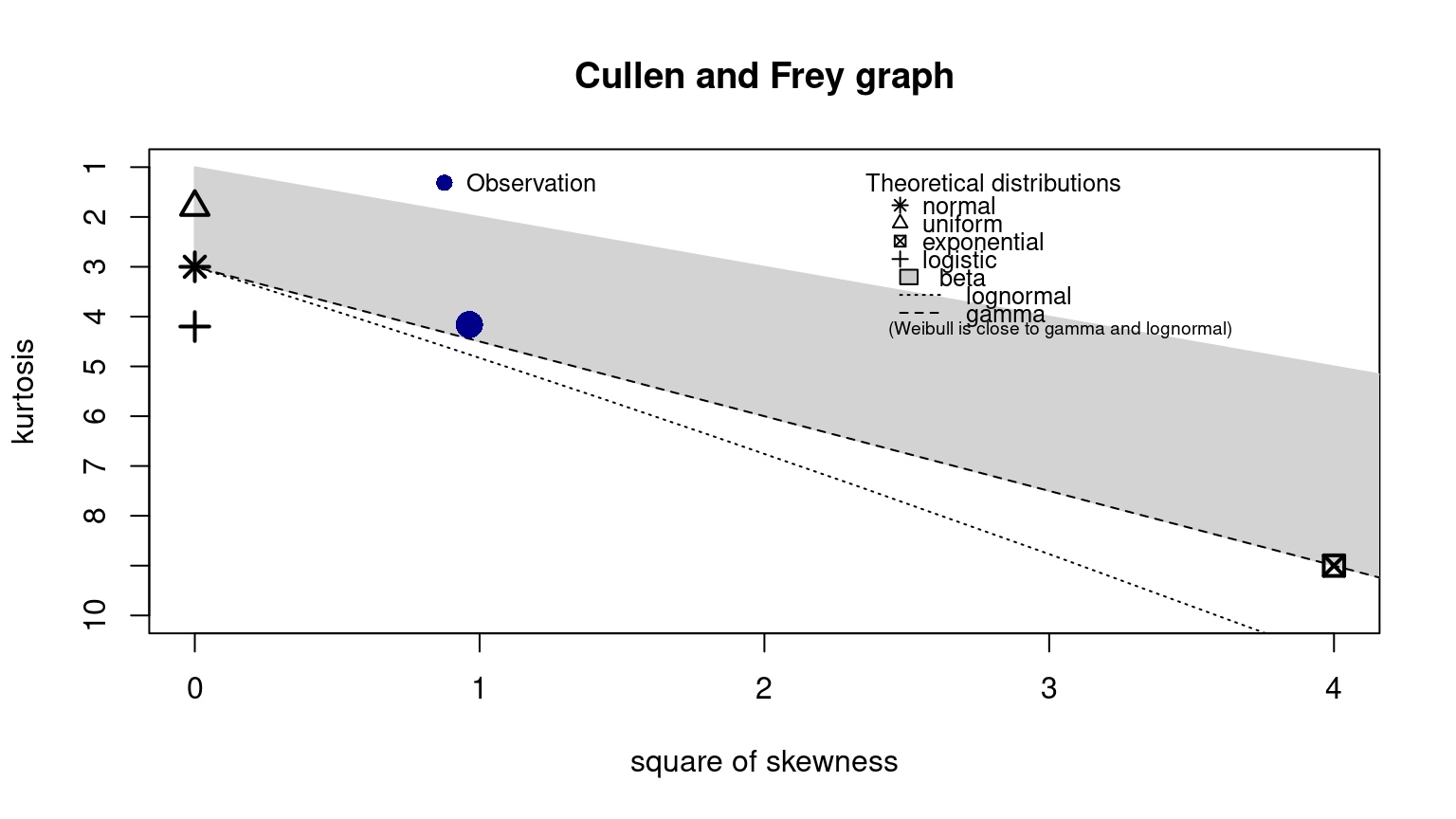
Al ejecutar la función descdist() del paquete fitdistrplus en R, se obtienen medidas descriptivas para la muestra y un gráfico que me permite ver el coeficiente de asimetría y el de curtosis muestral con respecto a las regiones en el plano que ocuparían algunas distribuciones de acuerdo a los valores que pueden tomar sus coeficientes de asimetría y de curtosis (es decir los teóricos poblacionales).
Código
# Medidas descriptivas y plano asimetría^2 vs kurtosisdescdist(x)
Generalmente una variable que representa un porcentaje tendrá valores entre 0\% y 100\%, y así mismo, una variable que representa una razón o proporción tendrá valores entre 0 y 1. Para modelar este tipo de variables sería apropiado utilizar una distribución con dominio acotado (con dominio en un intervalo (a,b)). La distribución Beta es una de las distribuciones más usadas para variables que toman valores en (0,1).
2.2.3.1 Intentamos solución analítica
Para la distribución beta en (0,1), se tienen las fórmulas que se muestran a continuación.
Función de densidad: \mathrm{f}_X \left(x, \alpha, \beta\right) = \frac{1}{\mathrm{B}(\alpha,\beta)} x^{\alpha-1} (1-x)^{\beta-1} \mathrm{I}_{(0,1)}(x) donde \mathrm{B}(\alpha,\beta) = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)} y \Gamma(x) = \int_{0}^{\infty} t^{x-1} e^{-t} dt.
Espacio de los parámetros: \theta = \left( \alpha, \beta \right)^T \in \Theta = (0, \infty) \times (0, \infty).
Al parecer debido a la forma de funciones gamma, digamma y trigamma, hasta ahora nadie ha podido obtener una formula o expresión explícita y cerrada para el estimador máximo verosímil de una distribución Beta con parámetros \alpha y \beta. ¿Qué hacer en una situación como esta?
2.2.3.2 Optimización mediante métodos numéricos
Exceptuando algunos casos especiales, las ecuaciones de verosimilitud, \frac{\partial }{\partial \theta} \mathrm{L}(\theta; x_1, \dots, x_n) = 0 \quad \text{ y } \quad \frac{\partial }{\partial \theta} \log \mathrm{L}(\theta; x_1, \dots, x_n) = 0, no pueden solucionarse de manera analítica. Por tanto, es necesario usar métodos numéricos o procedimientos iterativos para poder solucionar el problema de optimización asociado a dichas ecuaciones, \underset{\theta \in \Theta}{\arg \sup} \; \mathrm{L}\left(\theta; x_1, \dots, x_n \right) \quad \text{ y } \quad \underset{\theta \in \Theta}{\arg \sup} \; \log \mathrm{L}\left(\theta; x_1, \dots, x_n \right).
Existen variados métodos numéricos para resolver problemas de optimización. Buena parte de ellos toman un valor inicial para \theta, notado \hat{\theta}_0, y a partir de él buscan obtener una secuencia convergente \{ \hat{\theta}_r \}_{r=0,1,\dots}. Los algoritmos más comunmente utilizados, los Hill climbing algorithms, se basan en una ecuación de actualización de este tipo, \hat{\theta}_{r+1} = \hat{\theta}_{r} + \lambda_r \; \mathbf{\mathrm{d}}_r\left(\hat{\theta}_r\right) donde el vector \mathbf{\mathrm{d}}_r\left(\hat{\theta}_r\right) indica la “dirección del r-ésimo paso” y el escalar \lambda_r representa la “longitud o tamaño de ese r-ésimo paso”.
En el caso de los Gradient ascent algorithms, la dirección de cada paso es la del gradiente de la función objetivo, \mathbf{\mathrm{d}}_r\left(\hat{\theta}_r\right) = \Delta \left(\hat{\theta}_r\right). El gradiente de la función de log-verosimilitud con respecto al vector de parámetros suele denominarse score, \Delta \left(\theta\right) = \frac{\partial}{\partial \theta} \log \mathrm{L}.
En el método de Newton–Raphson, \lambda_r = 1 y \mathbf{\mathrm{d}}_r\left(\hat{\theta}\right) = -\mathbf{\mathrm{H}}^{-1}\left(\hat{\theta}_r\right) \Delta\left(\hat{\theta}_r\right), donde \Delta(\theta) es el score y \mathbf{\mathrm{H}}^{-1}(\theta) es el inverso de la matrix Hessiana de la función de log-verosimilitud \left( \mathbf{\mathrm{H}}(\theta) = \frac{\partial^2}{\partial \theta \partial \theta^T} \log \mathrm{L} \right), ambos evaluados en \hat{\theta}_r.
El método denominado Fisher’s Scoring es casi identico al método de Newton-Raphson, pero en vez de utilizar el negativo del inverso de la matrix Hessiana de la función de log-verosimilitud \left(-\mathbf{\mathrm{H}}^{-1}(\theta) \right), utiliza el inverso de la matrix de información de Fisher \left(\mathcal{I}^{-1}\left(\theta\right) \right). La matrix de información de Fisher es la varianza del score, \mathcal{I}\left(\theta\right) = Var \left[ \Delta\left(\theta\right) \right] = E \left[ \Delta\left(\theta\right) \Delta\left(\theta\right)^T \right] y bajo ciertas condiciones (condiciones de regularidad), también es igual al inverso aditivo del valor esperado de la matrix Hessiana de la función de log-verosimilitud, \mathcal{I}\left(\theta\right) = Var \left[ \Delta\left(\theta\right) \right] = E \left[ \Delta\left(\theta\right) \Delta\left(\theta\right)^T \right] = - E \left[ \mathbf{\mathrm{H}}(\theta) \right].
Dado que el cálculo de la matrix Hessiana o el de la matrix de información (más el cálculo de la respectiva inversa) son computacionalmente costosos, otras alternativas han sido propuestas. Una de ellas es, por ejemplo, el algoritmo de Broyden–Fletcher–Goldfarb–Shanno (BFGS).
¿Existen situaciones en las cuales el método de optimización numérica utilizado podría “fallar”? ¿Qué debería hacer para estar seguro de que voy a encontrar o de que encontré el máximo de la función para todos los posibles valores de los parámetros?
2.2.3.3 Aplicando optimización numérica
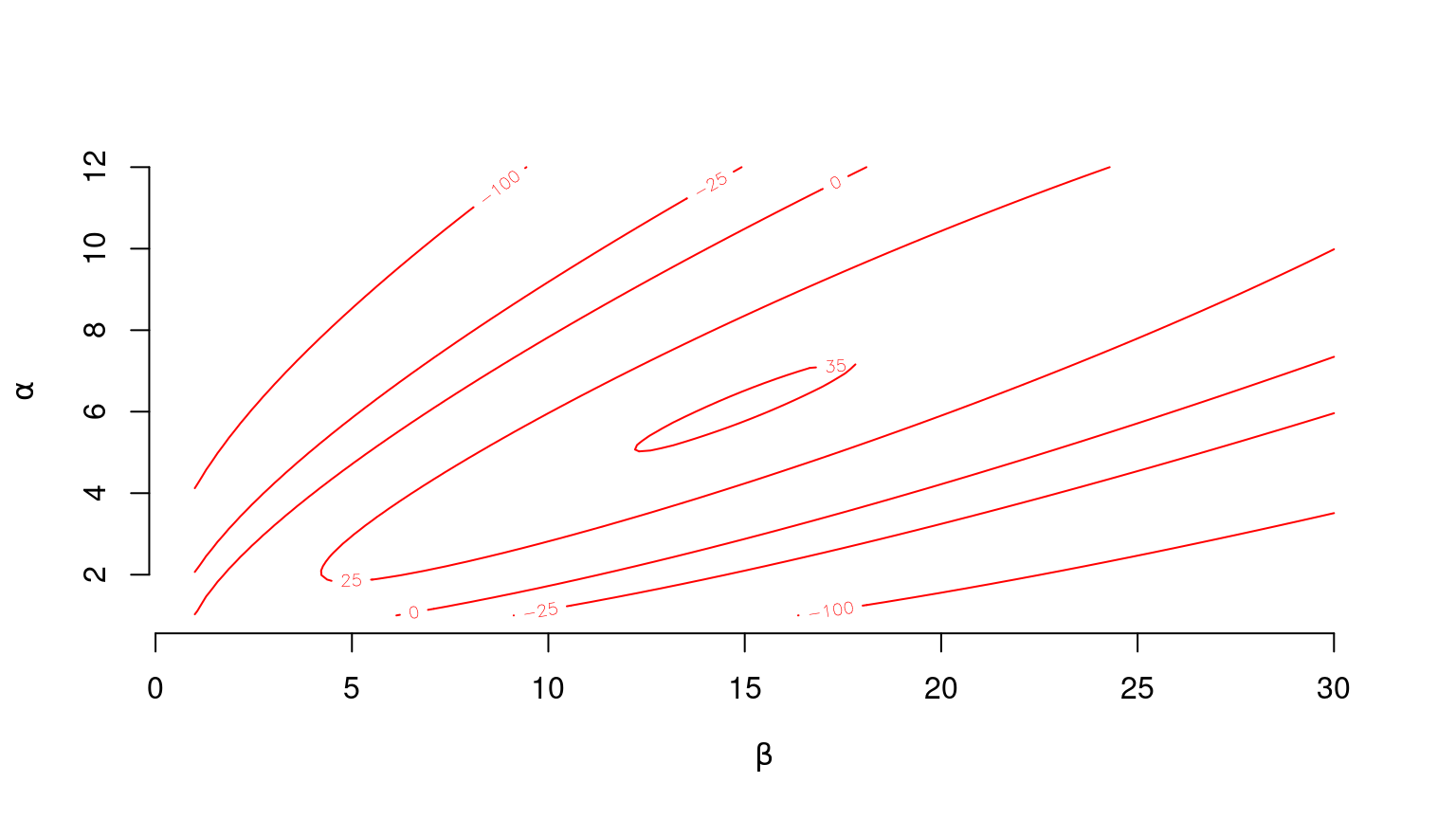
Retomando los datos mencionados acerca del porcentaje de gasto en alimentación de los hogares, La siguiente gráfica muestra algunas curvas de nivel de la función de log-verosimilitud.
Código
### log-verosimilitud con la distribución Beta### para el porcentaje de gasto en alimentaciónloglik.beta<-function(theta, sample){sum(dbeta(sample, theta[1], theta[2], log =TRUE))}### Gráfico de log-verosimilitud (curvas de nivel)alpha<-seq(1, 12, length.out =101)beta<-seq(1, 30, length.out =101)z<-apply(expand.grid(alpha, beta), 1, loglik.beta, sample =x)z<-matrix(z, 101, 101, byrow =TRUE)contour(beta, alpha, z, drawlabels =TRUE, levels =c(-100,-25,0,25,35), col="red", bty ="none", xlab=quote(beta), ylab=quote(alpha))
Esperariamos encontrar el máximo \left(\hat{\alpha}, \hat{\beta} \right) de dicha función dentro de la curva de nivel (elipse) etiquetada con el número 35.
Si queremos realizar la optimización numérica usando el método de Newton-Raphson, necesitamos calcular el gradiente y la Hessiana de la función de log-verosimilitud, para un valor de \theta requerido.
### Opción 2: Derivación automática o algorítmica### Expresión LogL para la función de log-verosimilitudn<-length(x)# Tamaño de la muestraslx<-sum(log(x))# sl1mx<-sum(log(1-x))#logL<-expression((a-1)*slx+(b-1)*sl1mx-n*(log(gamma(a))+log(gamma(b))-log(gamma(a+b))))### Gradiente y Hessiana automática de la función logLderiv.logL<-deriv(logL, c("a", "b"), hessian =TRUE)# Expresiónres<-eval(deriv.logL)# Evaluacióncat("\nGradiente automática evaluada en theta (función deriv):\n")
Gradiente automática evaluada en theta (función deriv):
### Opción 3: Implementar formulas analíticas.### Gradiente de la función de log-verosimilitudscore<-function(theta, sample){n<-length(sample)c(sum(log(sample)), sum(log(1-sample)))-n*(digamma(theta)-digamma(sum(theta)))}cat("\nGradiente analítica evaluada en theta (función propia):\n")
Gradiente analítica evaluada en theta (función propia):
### Hessiana de la función de log-verosimilitudH<-function(theta, sample){n<-length(sample); aux1<-trigamma(sum(theta))H<--n*diag(trigamma(theta)-aux1)H[1,2]<-H[2,1]<-n*aux1H}cat("\nHessiana analítica evaluada en theta (función propia):\n")
Hessiana analítica evaluada en theta (función propia):
Podemos utilizar otros métodos. Sin embargo, es importante recordar que \theta = (\alpha, \beta) \in \mathbb{R}^+ \times \mathbb{R}^+ = \Theta, y por ende, debemos garantizar que esto es tenido en cuenta por aquellos métodos que vayamos a utilizar.
Código
### Optimizacion usando múltiples métodos con optimx ### pero sin darle el gradiente o la Hessiana### (by default optimx performs minimization)### Instalar y cargar la libreria optimx (optimización)if(!require(optimx)){install.packages("optimx"); require(optimx)}### Espacio de los parámetros: theta \in (0,\infty)^2m.loglik.beta<-function(theta, x){-loglik.beta(theta, x)}# -1 * log-verosimilitud(theta)m.opt<-optimx(c(6, 15), m.loglik.beta, x =x, lower =1e-6, control =list(all.methods =TRUE))# todosknitr::kable(summary(m.opt, order =value))# reporte ordenado
p1
p2
value
fevals
gevals
niter
convcode
kkt1
kkt2
xtime
nlminb
6.071641
14.82210
-3.534644e+01
11
28
9
0
TRUE
TRUE
0.002
L-BFGS-B
6.071635
14.82209
-3.534644e+01
9
9
NA
0
TRUE
TRUE
0.002
Rcgmin
6.071653
14.82214
-3.534644e+01
870
406
NA
1
TRUE
TRUE
0.041
spg
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
Rvmmin
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
bobyqa
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.003
nmkb
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
hjkb
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.000
Algunos métodos solamente funcionan para cuando \Theta = \mathbb{R}^d, donde d es el número de parámetros a estimar. Para poder usar esos métodos, podemos reparametrizar nuestro problema de optimización. Esto quiere decir que utilizamos una transformación adecuada para cambiar de parámetros (de espacio de parámetros), obteniendo un problema de optimización equivalente al que teniamos, \underset{\theta \in \Theta}{\arg \sup} \; \log \mathrm{L}\left(\theta; x_1, \dots, x_n \right) = \underset{\theta^* \in \mathbb{R}^d}{\arg \sup} \; \log \mathrm{L}\left(\theta^*; x_1, \dots, x_n \right)
En el caso de los parámetros de la distribución Beta, podemos utilizar esta transformación, \begin{align*}
\mathbb{R}^+ \times \mathbb{R}^+ &\longrightarrow \mathbb{R}^2 \\
\theta = \left(\alpha, \beta\right) &\longrightarrow \left(e^{\alpha}, e^{\beta}\right) = \theta^*
\end{align*}
Código
### Optimizacion usando múltiples métodos con optimx### pero sin darle el gradiente o la Hessiana### (by default optimx performs minimization)### Reparametrizando theta = exp(eta). eta \in R x R t.m.loglik.beta<-function(eta, x){-loglik.beta(exp(eta), x)}# -1 * log-verosimilitud(eta)t.m.opt<-optimx(c(0.8, 1.2), t.m.loglik.beta, x =x, # sin lower control =list(all.methods =TRUE))# todost.m.opt$p1<-exp(t.m.opt$p1); t.m.opt$p2<-exp(t.m.opt$p2)# thetaknitr::kable(summary(t.m.opt, order =value))# reporte ordenado
p1
p2
value
fevals
gevals
niter
convcode
kkt1
kkt2
xtime
nlminb
6.071642
14.82210
-3.534644e+01
16
31
12
0
TRUE
TRUE
0.001
CG
6.071617
14.82204
-3.534644e+01
332
79
NA
0
TRUE
TRUE
0.009
Rvmmin
6.071614
14.82203
-3.534644e+01
261
62
NA
0
TRUE
TRUE
0.015
L-BFGS-B
6.071612
14.82203
-3.534644e+01
13
13
NA
0
TRUE
TRUE
0.001
Rcgmin
6.071606
14.82202
-3.534644e+01
875
254
NA
1
TRUE
TRUE
0.031
nlm
6.071523
14.82180
-3.534644e+01
NA
NA
10
0
TRUE
TRUE
0.001
Nelder-Mead
6.071250
14.82130
-3.534644e+01
75
NA
NA
0
TRUE
TRUE
0.002
BFGS
6.070940
14.82002
-3.534644e+01
25
11
NA
0
TRUE
TRUE
0.003
spg
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
ucminf
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
newuoa
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
bobyqa
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
nmkb
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.001
hjkb
NA
NA
8.988466e+307
NA
NA
NA
9999
NA
NA
0.000
Uno o varios de los métodos de optimización numérica suelen estar implementados e incorporados de alguna manera en paquetes o funciones existentes.
Código
### Estimación máximo verosímil usando fitdistrplus::fitdist ### Instalar y cargar la libreria fitdistrplus (gráficos y ajuste)if(!require(fitdistrplus)){install.packages("fitdistrplus"); require(fitdistrplus)}fit.b<-fitdist(x, "beta")# estimación (by default method="mle")summary(fit.b)
Fitting of the distribution ' beta ' by maximum likelihood
Parameters :
estimate Std. Error
shape1 6.07213 1.358727
shape2 14.82243 3.398868
Loglikelihood: 35.34644 AIC: -66.69289 BIC: -63.41772
Correlation matrix:
shape1 shape2
shape1 1.0000000 0.9435681
shape2 0.9435681 1.0000000
Código
denscomp(list(fit.b), xlim =c(0,1))# Función de densidad ajustada
Código
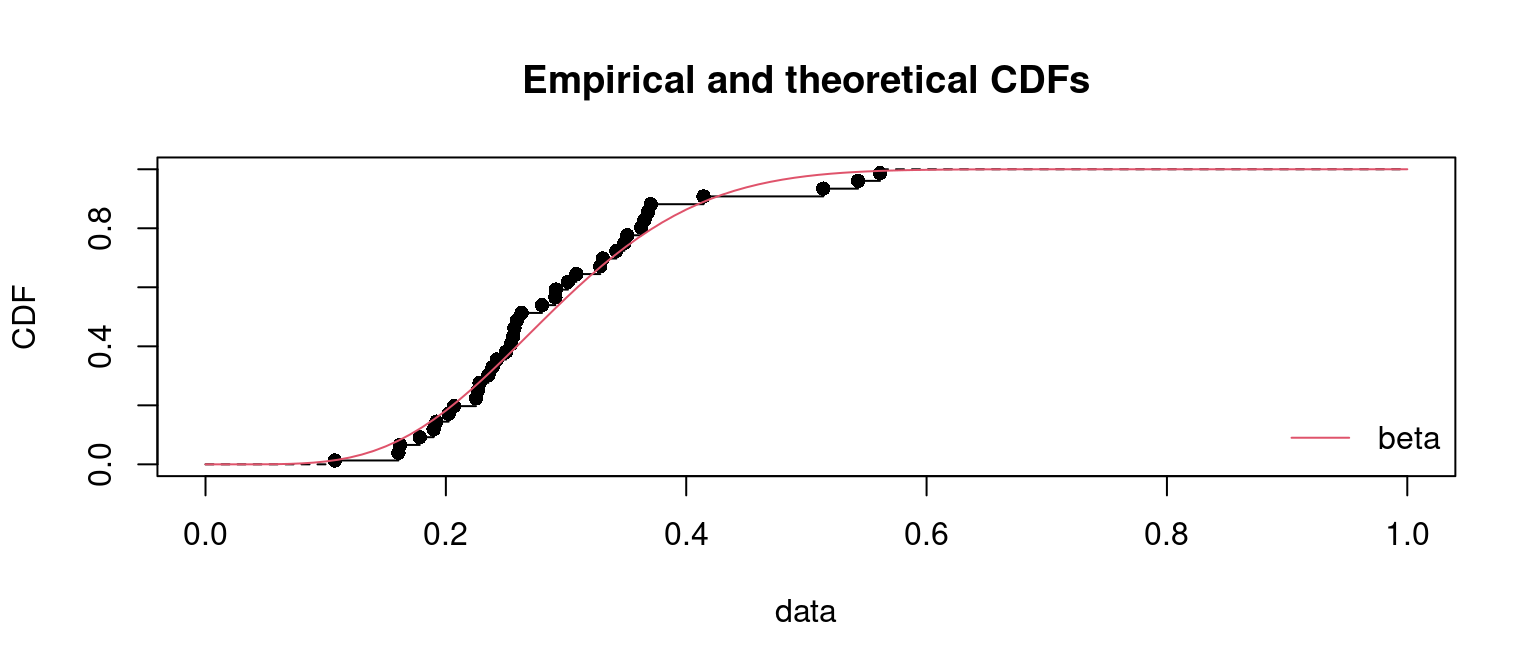
cdfcomp(list(fit.b), xlim =c(0,1))# Función de distribución ajustada
Dada una muestra aleatoria X_1, \dots, X_n proveniente de una población con distribución \mathrm{f}_X(x, \boldsymbol{\theta}), donde \boldsymbol{\theta} es el vector de parámetros, dada una función del vector de parámetros \mathrm{g}(.), y suponiendo que \mathbf{\mathrm{T}}(X_1, \dots, X_n) es el estimador de máxima verosimilitud de \boldsymbol{\theta}, entonces el estimador de máxima verosimilitud de \mathrm{g}(\boldsymbol{\theta}) es la estadística \mathrm{g}(\mathbf{\mathrm{T}}(X_1, \dots, X_n)).
2.3 Método de momentos
El método de momentos se puede asociar a la resolución de un sistema de ecuaciones, \hat{\boldsymbol{\theta}}_{MM} = \left\{\boldsymbol{\theta} \in \boldsymbol{\Theta} : \left( \hat{\eta}_1, \dots, \hat{\eta}_k \right) = \left( \eta_1(\boldsymbol{\theta}), \dots, \eta_k(\boldsymbol{\theta}) \right) \right\} donde \eta_1(\boldsymbol{\theta}), \dots, \eta_k(\boldsymbol{\theta}) pueden ser momentos ordinarios, centrales o estandarizados poblacionales, expresados como funciones de los parámetros, y \hat{\eta}_1, \dots, \hat{\eta}_k serían los respectivos momentos muestrales asociados.
2.3.1 Momentos poblacionales y muestrales
Sean X_1, \dots, X_n una muestra aleatoria de una población con momentos ordinarios y centrales de orden r, \mu_*^{(r)} = E\left[ X^r \right] \quad \text{ y } \quad \mu^{(r)} = E\left[ \left( X - \mu_*^{(1)} \right)^r \right] Los momentos muestrales ordinarios y centrales de ordenr = 1, 2, \dots se denotan y definen como, M_*^{(r)} = \frac{1}{n} \sum_{i=1}^n X_i^r \quad \text{ y } \quad M^{(r)} = \frac{1}{n} \sum_{i=1}^n \left( X_i - M_*^{(1)} \right)^r.
2.3.2 Una solución analítica
Encontrar \hat{\boldsymbol{\theta}}_{MM} = T(x_1, \dots, x_n) cuando X_1, \dots, X_n es una muestra aleatoria de una población con X \sim Gamma(k = \theta_1, \beta = \theta_2)\left( \mathrm{f}_X \left(x, \boldsymbol{\theta}\right) = \frac{1}{\theta_2^{\theta_1} \Gamma(\theta_1)} x^{\theta_1 - 1} \, \mathrm{e}^{-\frac{x}{\theta_2}} \, \mathrm{I}_{(0, \infty)}(x) \right).
Como tengo dos parámetros por estimar, necesito dos momentos. Dos momentos me permitan tener dos ecuaciones para esas dos incógnitas. El primer momento ordinario de una variable aleatoria X distribuida Gamma con parámetro de forma \theta_1 y parámetro de escala \theta_2 es, E[X] = \theta_1 \theta_2, y el segundo momento central es, E\left[\left(X-E\left(X\right)\right)^2\right] = Var[X] = \theta_1 \theta_2^2
El sistema de ecuaciones me quedaría así, \begin{align*}
\theta_1 \theta_2 = \mu_*^{(1)} &= M_*^{(1)} = \frac{1}{n} \sum_{i=1}^n X_i = \bar{X} \\
\theta_1 \theta_2^2 = \mu^{(2)} &= M^{(2)} = \frac{1}{n} \sum_{i=1}^n \left( X_i - \bar{X} \right)^2
\end{align*}
Para resolver el sistema de ecuaciones podría tomar la segunda ecuación y dividirla por la primera, \frac{\frac{1}{n} \sum_{i=1}^n \left( X_i - \bar{X} \right)^2}{\bar{X}} = \frac{\theta_1 \theta_2^2}{\theta_1 \theta_2} = \theta_2, despejando \theta_1 y reemplazando \theta_2 en la primera ecuación, \begin{align*}
\theta_1 \theta_2 &= \bar{X} \\
\theta_1 &= \frac{\bar{X}}{\theta_2} \\
\theta_1 &= \frac{\bar{X}^2}{\frac{1}{n} \sum_{i=1}^n \left( X_i - \bar{X} \right)^2}
\end{align*} luego \hat{\boldsymbol{\theta}}_{MM} = \left( \frac{\bar{X}^2}{\frac{1}{n} \sum_{i=1}^n \left( X_i - \bar{X} \right)^2}, \frac{\frac{1}{n} \sum_{i=1}^n \left( X_i - \bar{X} \right)^2}{\bar{X}} \right) es un estimador por el método de momentos de \boldsymbol{\theta} = (\theta_1, \theta_2).
2.4 Métodos en general
Sean X_1, \dots, X_n una muestra aleatoria de una población con vector de parámetros \boldsymbol{\theta}. La mayoría de los métodos usados para obtener estimadores se pueden dividir en dos grupos; aquellos que tienen que ver con la resolución de un sistema de ecuaciones, \hat{\boldsymbol{\theta}} = \left\{\boldsymbol{\theta} \in \boldsymbol{\Theta} : \hat{\boldsymbol{h}}_n(\boldsymbol{x})=\boldsymbol{h}(\boldsymbol{x};\boldsymbol{\theta}) \right\} y aquellos que tienen que ver con la resolución de un problema de optimización, \hat{\boldsymbol{\theta}} = \arg \min_{\boldsymbol{\theta} \in \boldsymbol{\Theta}} \; \mathrm{d} \left[ \hat{\boldsymbol{h}}_n(\boldsymbol{x}),\boldsymbol{h}(\boldsymbol{x};\boldsymbol{\theta}) \right] donde \mathrm{d}\left[,\right] es una distancia generalizada, \hat{\boldsymbol{h}}_n(\boldsymbol{x}) es una función escalar o vectorial asociada a la muestra y \boldsymbol{h}(\boldsymbol{x};\boldsymbol{\theta}) es una función conformable asociada al modelo teórico seleccionado.
Si tuviese que hacer un listado de métodos:
Maximum likelihood
Maximum product of spacing
Maximum goodness of fit or minimum distance for the Cumulative Distribution Function
Kolmogorov-Smirnov
Cramér-von Mises
Anderson-Darling
Method of moments or moment matching
Minimum distance for the Moments
Minimum distance for the Moment Generating Function
Minimum distance for the Characteristic Function
Quantile matching
Minimum distance for the Quantile Function
En el caso de los métodos que involucran una distancia, cabe la posibilidad de usar diferentes funciones, es decir diferentes métricas. Generalmente se suele usar la distancia euclidiana pero no es la única opción. Adicionalmente, se pueden introducir pesos diferenciados para darle más o menos importancia a alguna parte de una función. Por ejemplo, darle más peso a la distancia en la cola derecha de una función de distribución acumulativa y darle menor peso a la cola izquierda.
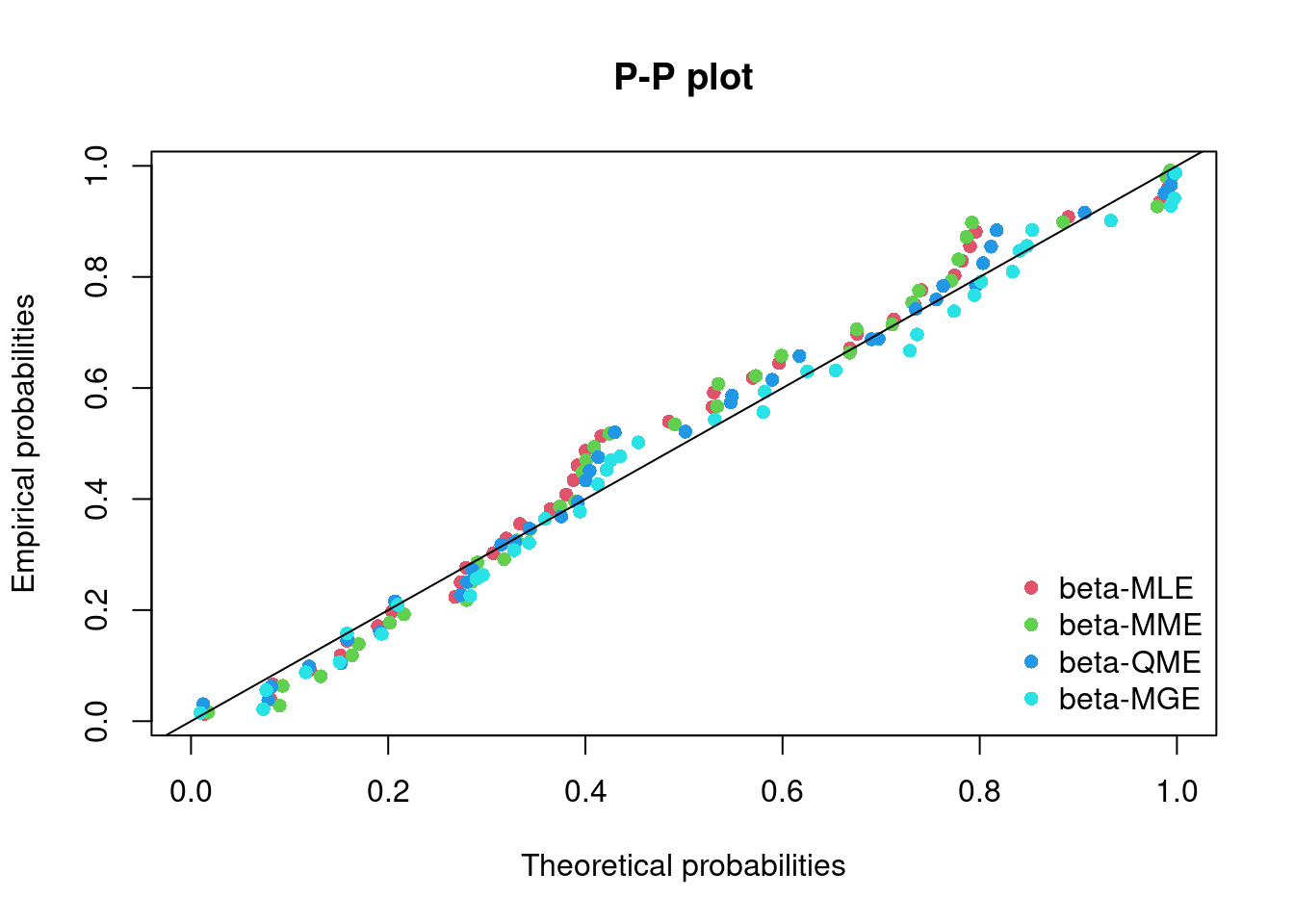
2.4.1 Usando paquete fitdistrplus
Código
### Instalar y cargar la libreria betareg (datos FoodExpenditure)if(!require(betareg)){install.packages("betareg"); require(betareg)}library(betareg)### Instalar y cargar la libreria fitdistrplus (ajuste)if(!require(fitdistrplus)){install.packages("fitdistrplus"); require(fitdistrplus)}library(fitdistrplus)### Cargar los datos de gasto en alimentación (38 hogares)data("FoodExpenditure", package="betareg")### Porcentaje de gasto en alimentaciónx<-FoodExpenditure$food/FoodExpenditure$income### Estimación fitdistrplus::fitdist fit.b<-fitdist(x, "beta")# (by default method="mle")fit.b.mme<-fitdist(x, "beta", method ="mme")# moment matchingfit.b.qme<-fitdist(x, "beta", method ="qme", probs =c(1/3, 2/3))# quantile matchingfit.b.KSe<-fitdist(x, "beta", method ="mge", gof ="KS")# Kolmogorov-Smirnovrbind(MLE =fit.b$estimate, MME =fit.b.mme$estimate, QME =fit.b.qme$estimate, MGE.KS =fit.b.KSe$estimate)