En esta sección se hará una corta y rápida revisión de algunos aspectos relacionados con el modelo de regresión lineal simple.
ImportanteActividad autónoma independiente (antes de las clases correspondientes a esta sección)
Lee todo el contenido de esta sección (Inferencia, 14. Regresión lineal simple).
En tus propias palabras, has una exposición escrita detallada en tu cuaderno sobre cada parte de lo leído, como si le estuvieras explicando a un compañero o amigo. Recuerda que aprendemos aproximadamente el 95% de lo que tratamos de enseñar a otros.
Anota cualquier duda o tema que te resulte confuso. ¡No te preocupes si no lo entiendes todo a la primera!
Busca por tu cuenta respuestas a esas dudas. Esto te ayudará a llegar a clase con ideas para compartir.
Lleva a clase: tu exposición escrita, tus dudas y las respuestas que encontraste. ¡Trabajaremos juntos para aclararlo todo!
14.1 Modelo
Y = \beta_0 + \beta_1 X + \varepsilon
Y es la variable respuesta, variable explicada o variable dependiente (“target”).
X es el regresor, variable explicativa o variable independiente (“features”).
\beta_0 es el coeficiente del ¿intercepto/intersecto? para la ecuación de la recta.
\beta_1 es el coeficiente de la pendiente para la ecuación de la recta.
\varepsilon es una variable aleatoria asociada al error.
Supuestos del modelo:
E[\varepsilon] = 0. Debido a que E[Y|x] = \beta_0 + \beta_1 x, entonces \beta_0 y \beta_1 deben ser constantes, y por lo tanto E[\varepsilon] = 0.
Var[\varepsilon] = \sigma^2. Debido a que Var[Y] = \sigma^2_Y = \sigma^2, entonces no hay variabilidad aportada por X, y por lo tanto Var[\varepsilon] = \sigma^2.
\varepsilon \sim \mathcal{N}(0,\sigma^2), que necesitamos para la parte inferencial (para las distribuciones muestrales que usaremos).
14.2 Recta estimada y residuo
Notación:
Sea \hat{b}_0 una estimación de \beta_0 y \hat{b}_1 una estimación de \beta_1.
Recta de regresión estimada:
La recta de regresión estimada está dada por:
\hat{y} = \hat{b}_0 + \hat{b}_1 \, x
Residuo:
El error en el ajuste o el residuo estimado para cada individuo es:
McGivern Jewelers se ubica en Levis Square Mall, al sur de Toledo, Ohio. Recientemente publicó un anuncio en redes sociodigitales donde indicaba forma, tamaño, precio y grado de corte de 33 de sus diamantes en existencia.
Lind, D. A., Marchal, W. G., Wathen, S. A. (2019). Estadística aplicada a los negocios y la economía. (17a. ed.) McGraw-Hill.
Los datos asociados a las cuatro variables de los 33 diamantes se encuentran en la pestaña “Datos” de la hoja de cálculo (Google Sheets):EjemploDatosDiamantesLind(15Ed)4.37.gsheet
Supongamos que los 33 diamantes no son unos datos poblacionales como lo hicimos en Capítulo 3 (Estadística Descriptiva, 3. Bivariada), sino consideremos hipotéticamente que son datos de una muestra aleatoria y que nos interesa modelar la relación entre tamaño y precio de los diamantes (inferir el modelo poblacional a partir de los datos muestrales).
Se tiene que SST = SSR + SSE, donde SST es un valor fijo (dados los valores conocidos y_i). Por lo tanto, \frac{SSE}{SST} determina la proporción del error y, R^2 = \frac{SSR}{SST} = 1 - \frac{SSE}{SST}, denominado coeficiente de determinación R^2, determina la proporción que es explicada por la regresión (con respecto a los valores o a la magnitud de los y_i).
Por otra parte, para el caso del modelo de regresión lineal simple se tiene que, R^2 = r_{xy}^2 donde r_{xy} es el coeficiente de correlación de Pearson muestral.
A partir de las anteriores distribuciones muestrales, ¿cómo serían los intervalos de confianza y las pruebas de hipótesis para \beta_1 y \beta_0?
14.7 Análisis de varianza
Nuevamente teniendo en cuenta que SST = SSR + SSE, se puede construir la siguiente tabla, llamada tabla ANOVA,
Fuentes de variación
Suma de cuadrados
Grados de libertad
Cuadrado medio
Estadístico
Regresión
SSR
1
MSR = \frac{SSR}{1}
F = \frac{MSR}{MSE}
Error
SSE
n-2
MSE = \frac{SSE}{n-2}
Total
SST
n-1
Si F > f_{(\alpha, 1, n-2)} entonces se rechaza H_0: \beta_1 = 0 con un nivel de significancia \alpha (equivalente a la prueba de hipótesis que utiliza la distribución muestral del estimador de \beta_1). Adicionalmente, es claro que MSE es una estimación de \sigma^2.
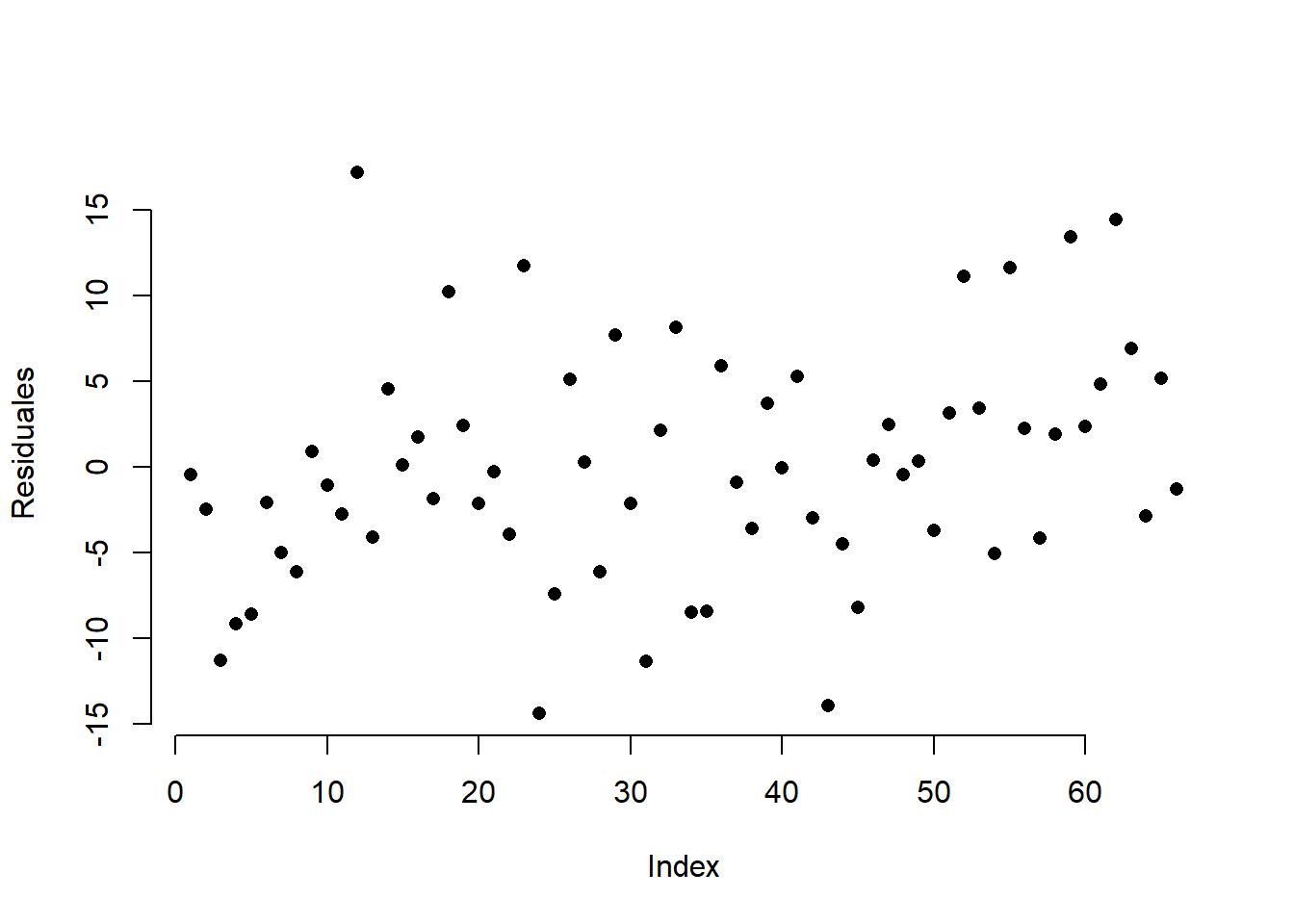
14.8 Supuestos y gráficos de los residuales
Los residuales son realizaciones de la variable aleatoria \varepsilon y el valor esperado de dicha variable es cero.
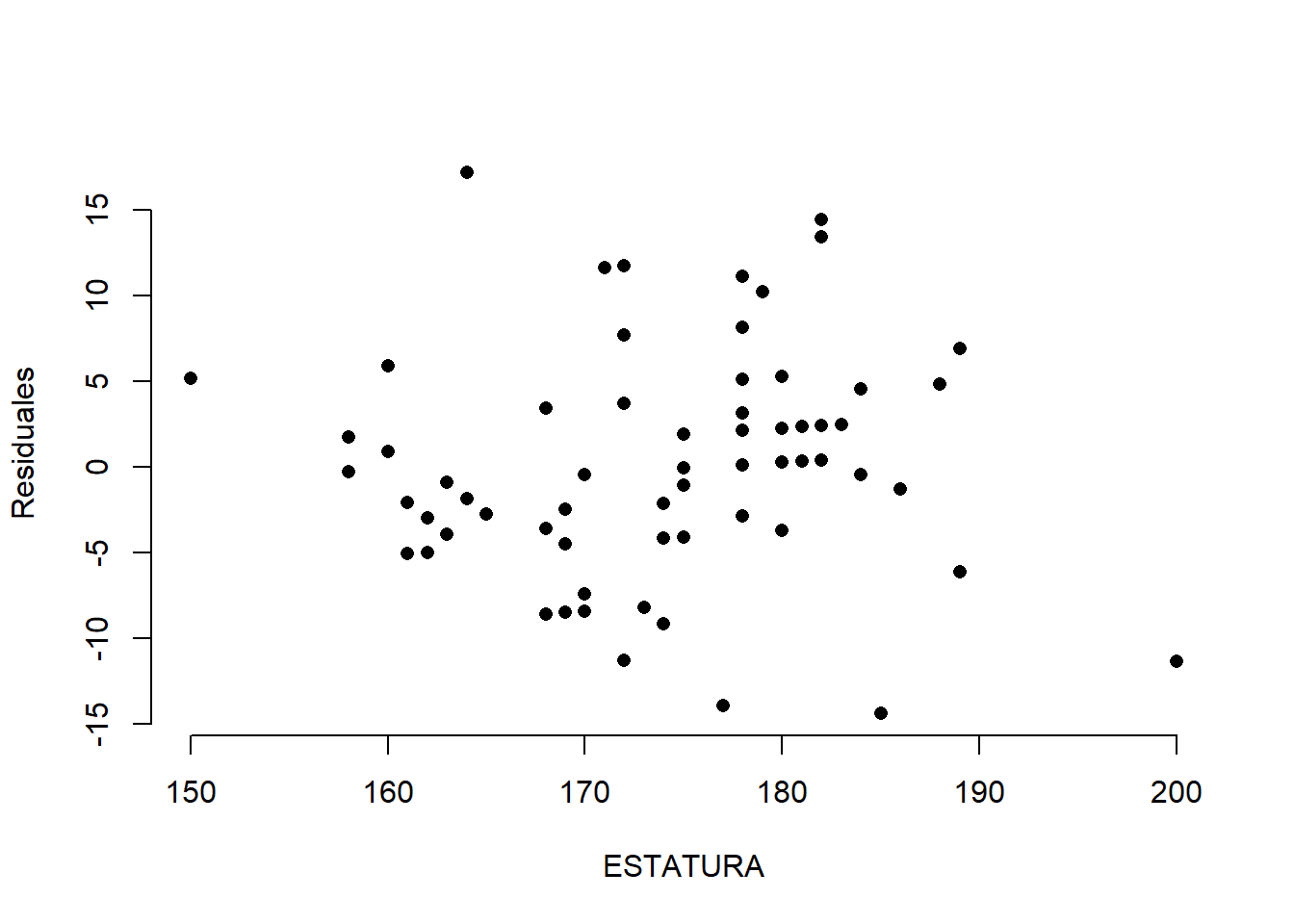
Gráfique i vs e_i. No debe haber patrones en la nube de puntos y los valores de los e_i deben estar “repartidos equitativamente” alrededor de cero.
No hay relación entre \varepsilon y X.
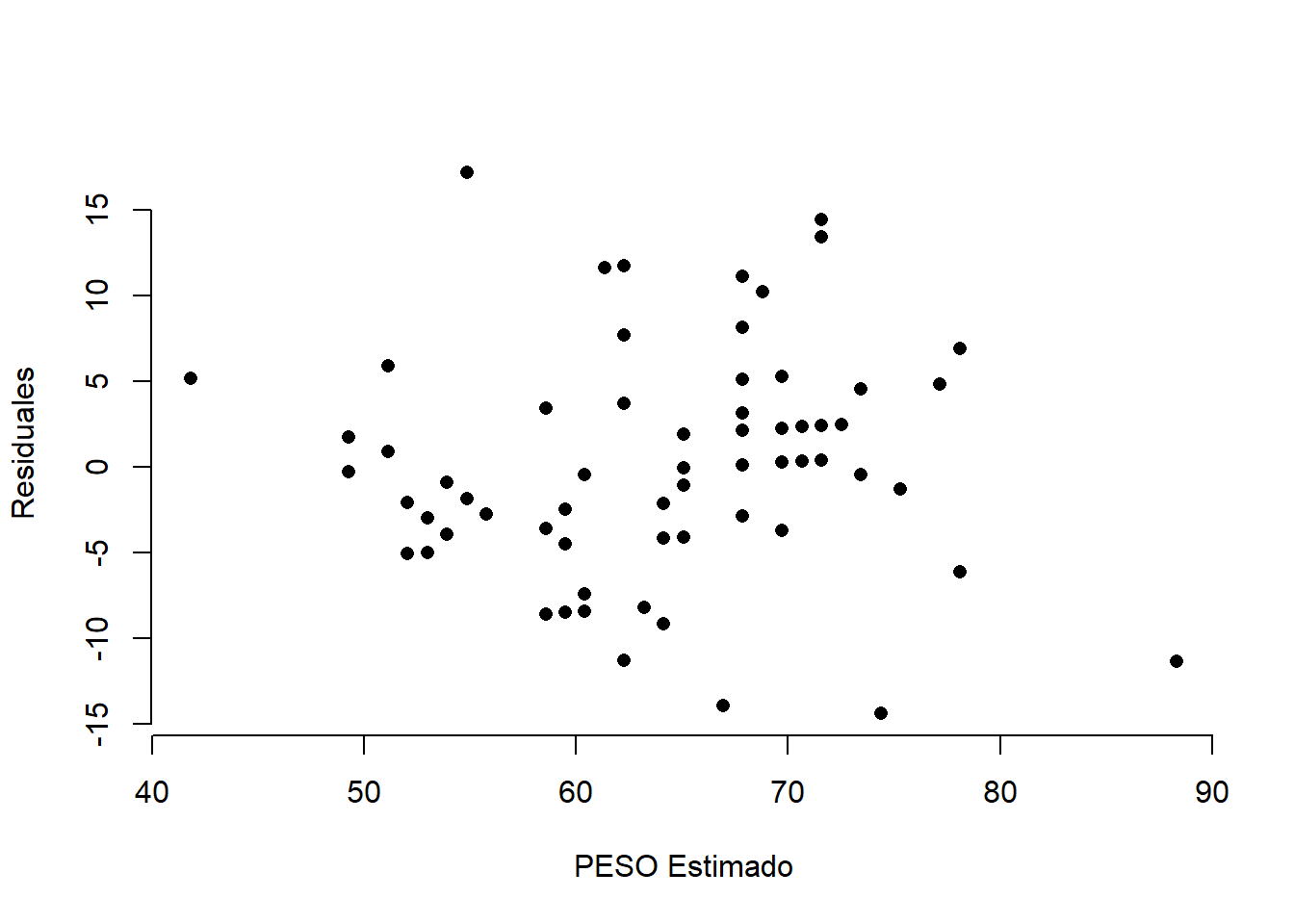
Gráfique x_i vs e_i. No debe haber patrones en la nube de puntos.
La varianza de \varepsilon es \sigma^2, es decir, la varianza es homogénea.
Gráfique \hat{y}_i vs e_i. No debe haber patrones en la nube de puntos.
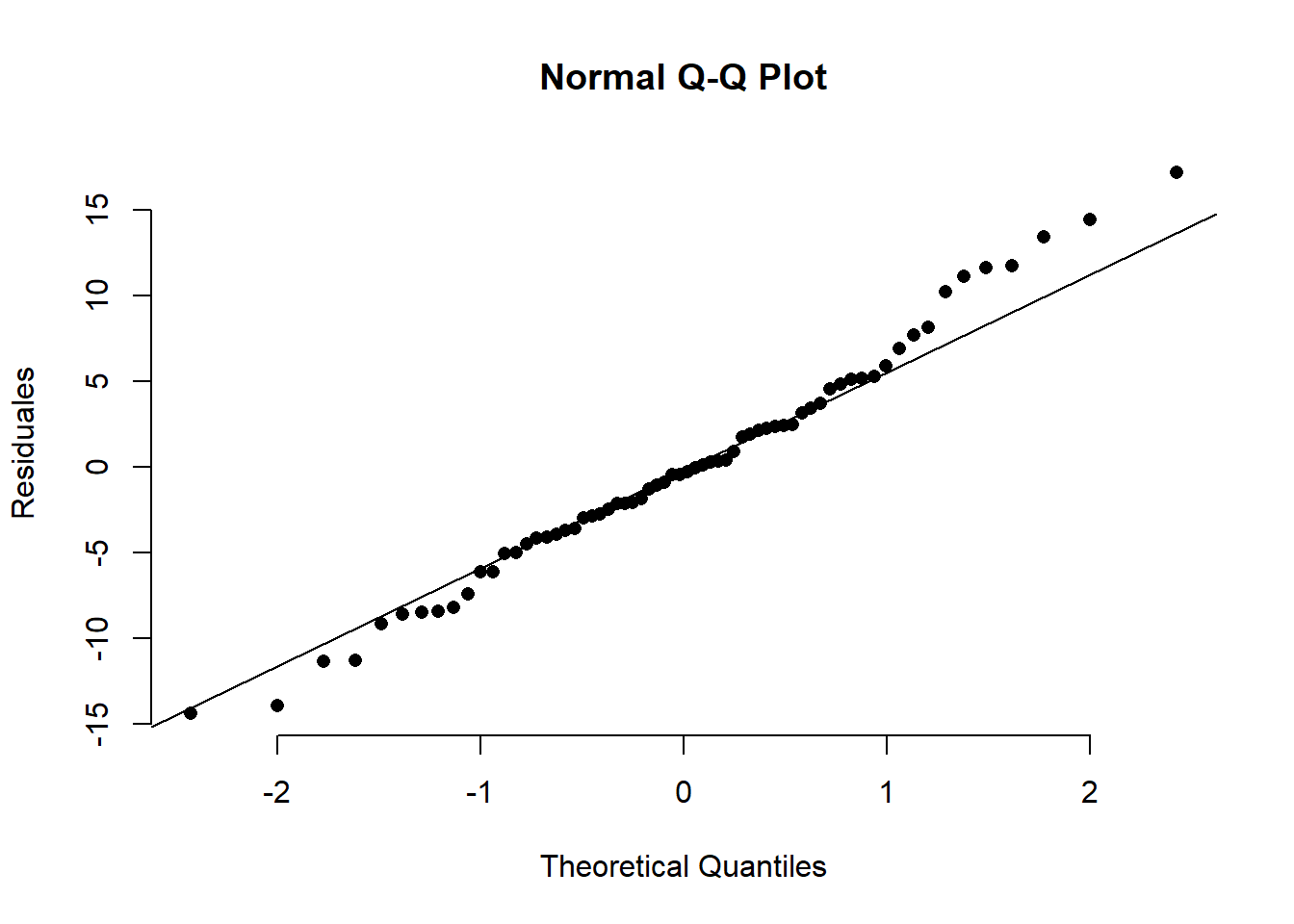
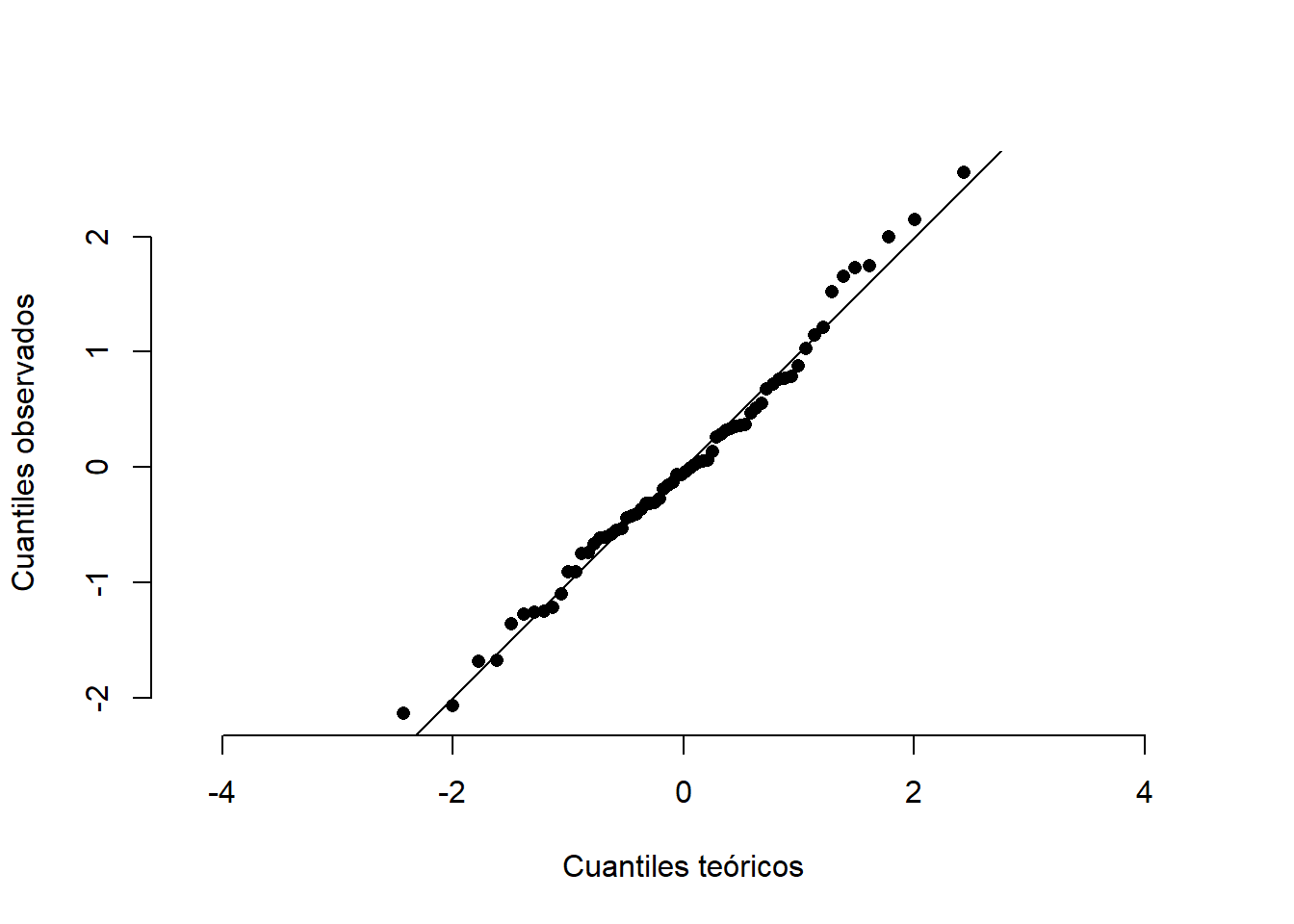
\varepsilon tiene una distribución normal (para las distribuciones muestrales de la parte inferencial).
Haga un qqplot (gráfico cuantil-cuatil) contra la distribución normal. La nube de puntos debe estar muy cercana a ser una recta (es mucho mejor hacer una prueba de normalidad. Investigar acerca del “Test de Shapiro-Wilk”).
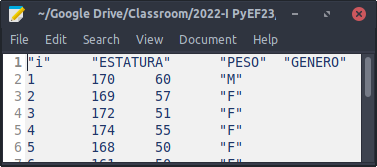
Para leer los datos del archivo Estatura-Peso.txt y almacenarlos en la variable DatosEstud hacer:
DatosEstud<-read.table("ruta/Estatura-Peso.txt", sep="\t", header=TRUE, row.names=1, stringsAsFactors=TRUE)# Para imprimir las primeras filas de lo almacenado en la variable DatosEstud:head(DatosEstud)
ESTATURA PESO GENERO
1 170 60 M
2 169 57 F
3 172 51 F
4 174 55 F
5 168 50 F
6 161 50 F
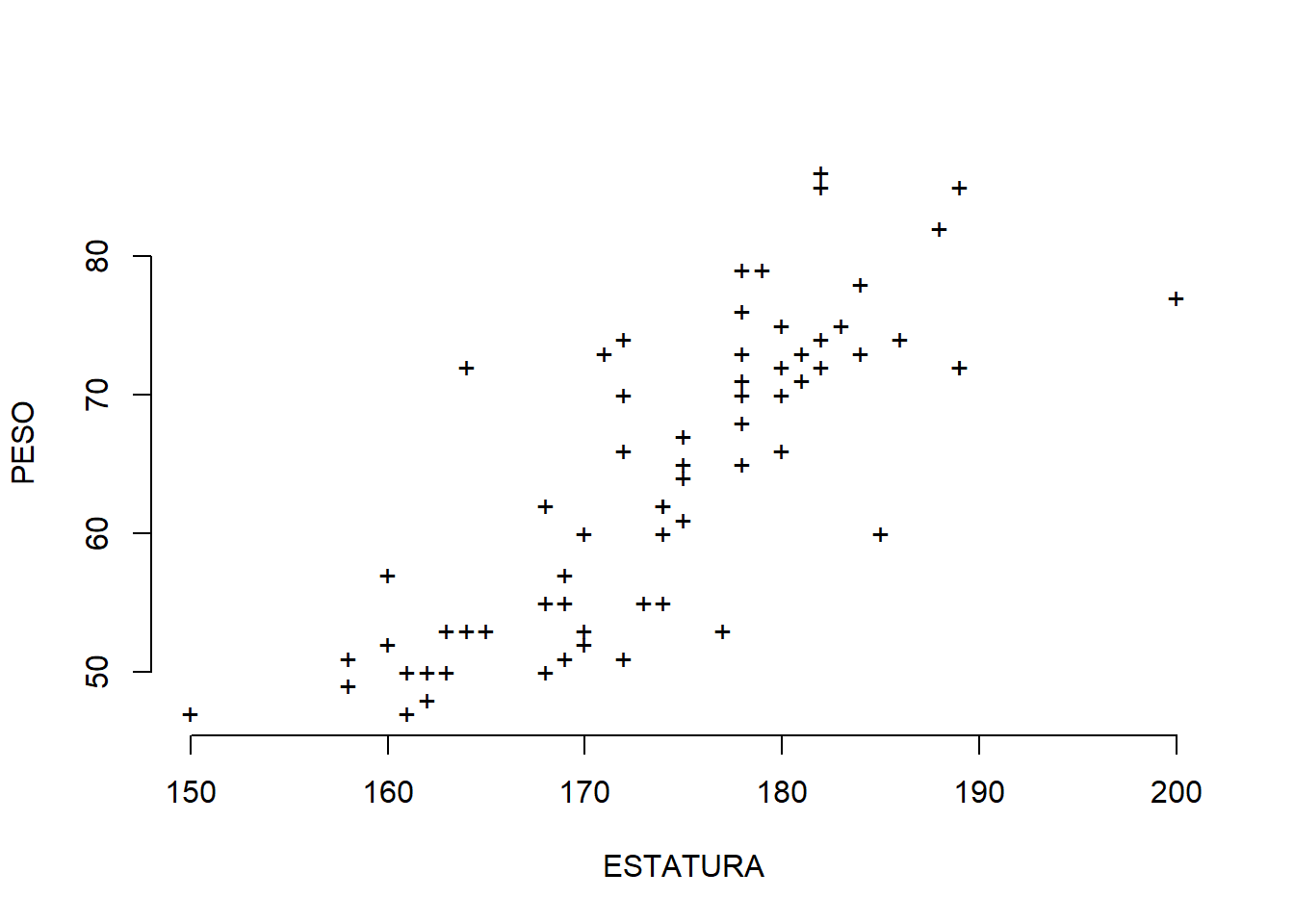
Diagrama de dispersión:
Para realizar un diagrama de dispersión de las variables estatura y peso hacer:
# Par gráficar columnas 1 y 2 de la varible DatosEstudplot(DatosEstud[,1:2], bty="n", pch="+")
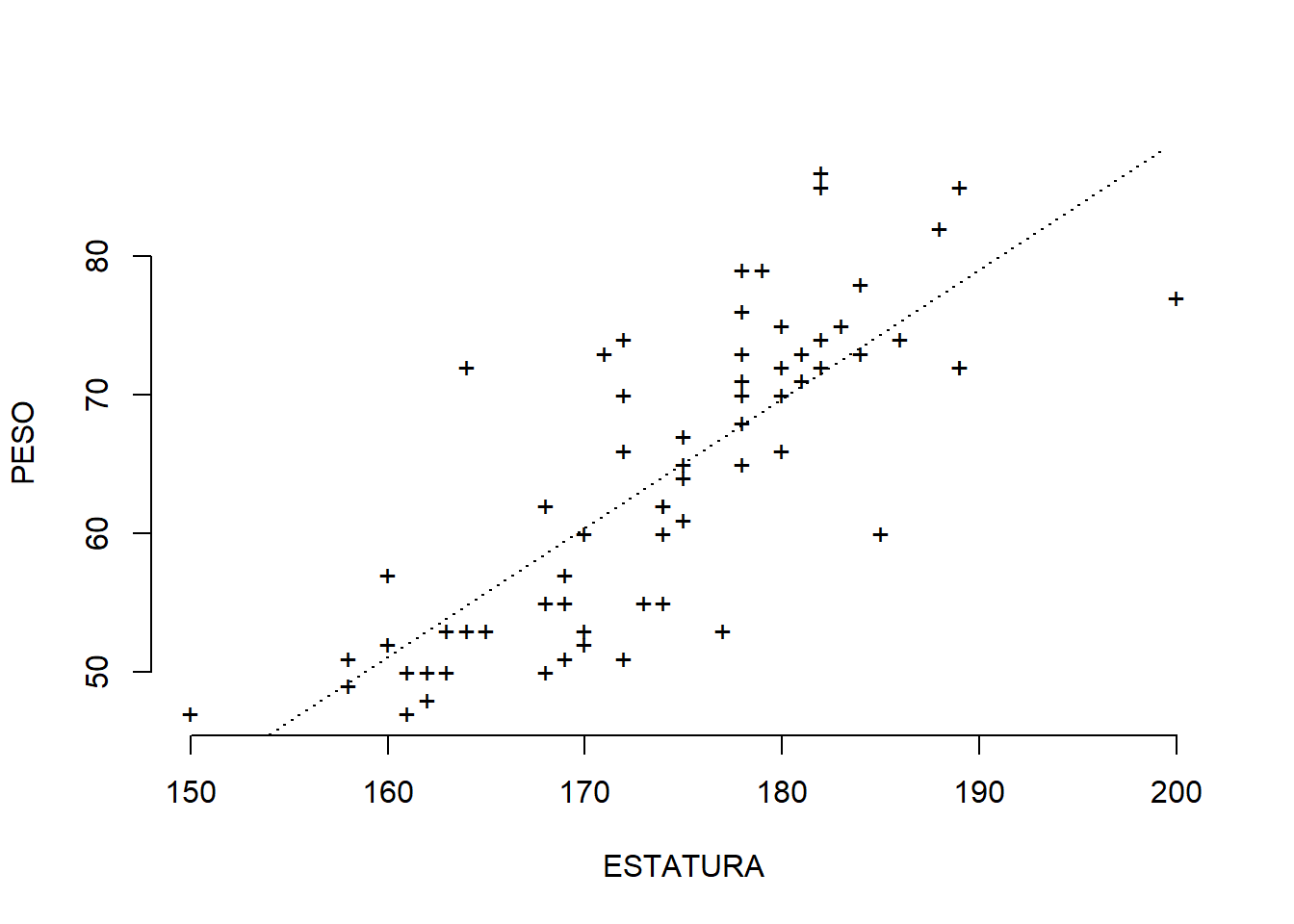
Modelo de regresión lineal simple:
La función lm obtiene el modelo de regresión lineal que se le indique, por ejemplo, peso = \beta_0 + \beta_1 estatura:
RegresionEstud<-lm(DatosEstud$PESO~DatosEstud$ESTATURA)# Para imprimir algunos pocos detalles del modelo almacenado en RegresionEstudRegresionEstud
Realice nuevamente el análisis del modelo de regresión lineal simple para el Ejercicio 2 pero obteniendo todos los valores con la calculadora o con una hoja de cálculo (verifique que los resultados coinciden con los obtenidos mediante R)
14.9.4 Ejercicio 4
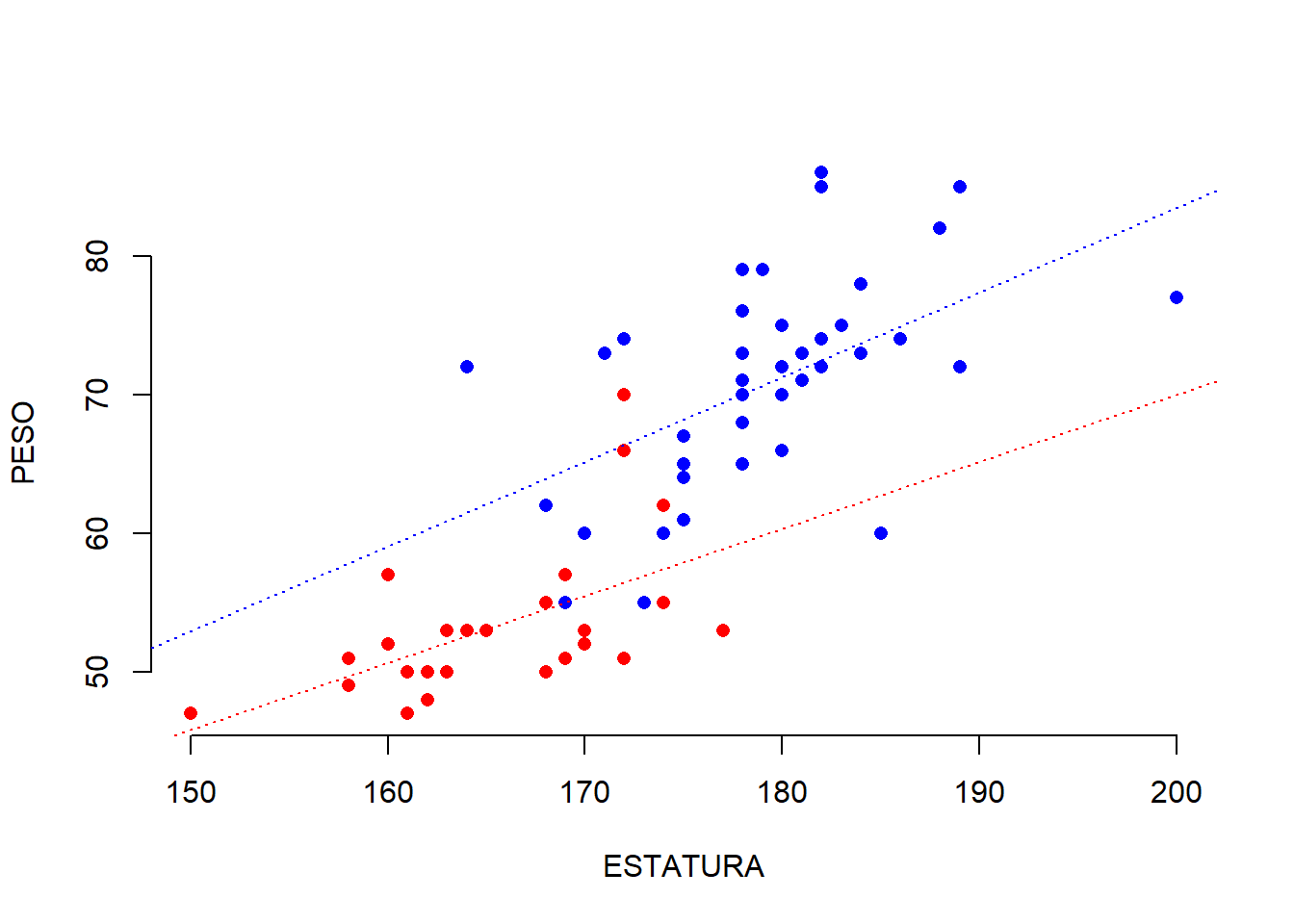
Obtenga los modelos de regresión lineal simple para cada género por aparte y haga el análisis completo de los mismos. ¿Qué conclusiones saca con respecto al modelo que tenía incluidos todos los individuos?
Algunos aspectos asociados a otros modelos, relacionados con el modelo de regresión lineal simple, se pueden consultar en el Apéndice E (Revisión básica: Más allá de la Regresión Lineal Simple (RLS))
ImportanteActividad autónoma independiente (después de las clases correspondientes a esta sección)
No olvides seleccionar y resolver ejercicios de un libro acerca de lo visto en esta sección (preferiblemente que tengan respuesta). Por ejemplo, selecciona ejercicios del capítulo 11 (sin las secciones 11.6, 11.9 y 11.12) del libro de Walpole o del capítulo 14 (sin las secciones 14.6 y 14.9) del libro de Anderson.